 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarizing Front Ends for Robust CNNs
Feb 22, 2020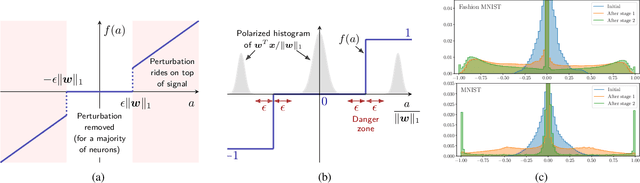
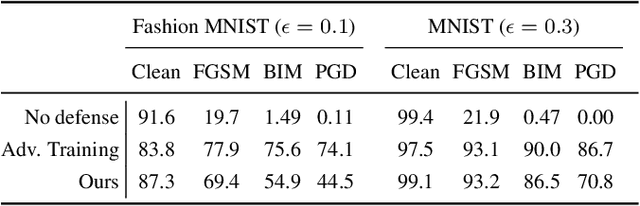
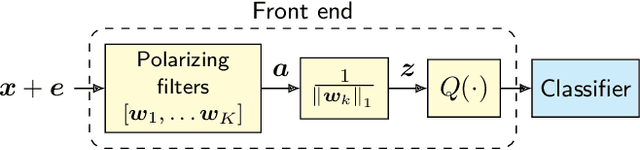
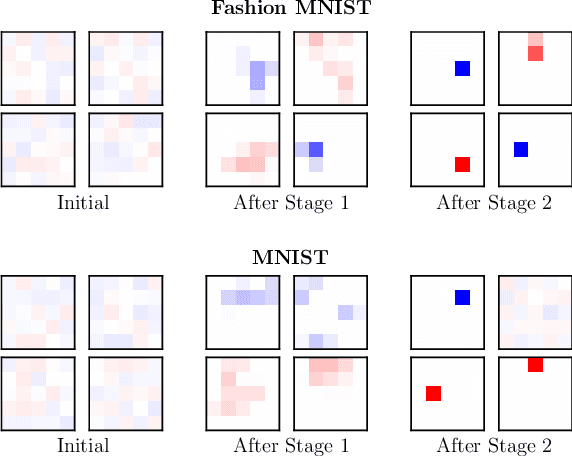
The vulnerability of deep neural networks to small, adversarially designed perturbations can be attributed to their "excessive linearity." In this paper, we propose a bottom-up strategy for attenuating adversarial perturbations using a nonlinear front end which polarizes and quantizes the data. We observe that ideal polarization can be utilized to completely eliminate perturbations, develop algorithms to learn approximately polarizing bases for data, and investigate the effectiveness of the proposed strategy on the MNIST and Fashion MNIST datasets.
FedPAQ: A Communication-Efficient Federated Learning Method with Periodic Averaging and Quantization
Oct 12, 2019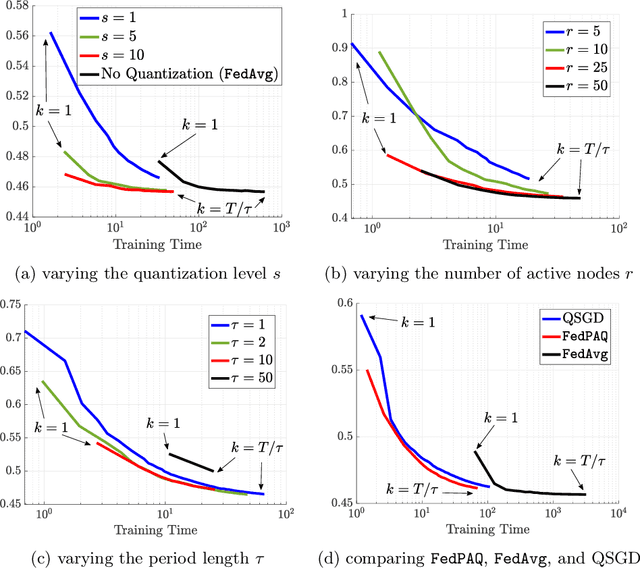
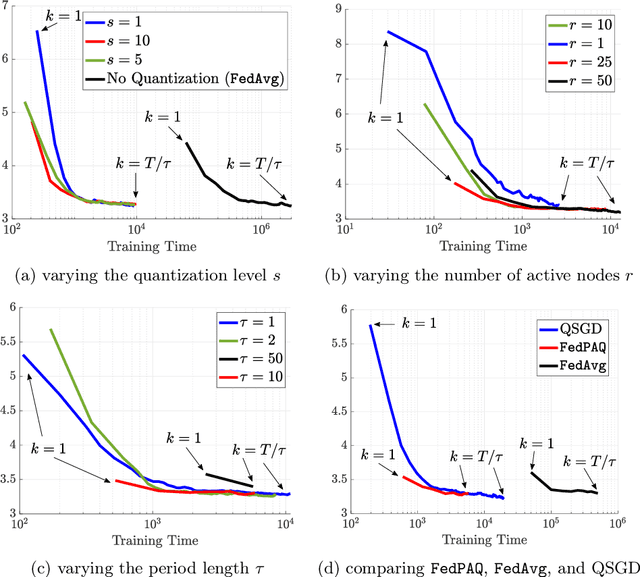
Federated learning is a distributed framework according to which a model is trained over a set of devices, while keeping data localized. This framework faces several systems-oriented challenges which include (i) communication bottleneck since a large number of devices upload their local updates to a parameter server, and (ii) scalability as the federated network consists of millions of devices. Due to these systems challenges as well as issues related to statistical heterogeneity of data and privacy concerns, designing a provably efficient federated learning method is of significant importance yet it remains challenging. In this paper, we present FedPAQ, a communication-efficient Federated Learning method with Periodic Averaging and Quantization. FedPAQ relies on three key features: (1) periodic averaging where models are updated locally at devices and only periodically averaged at the server; (2) partial device participation where only a fraction of devices participate in each round of the training; and (3) quantized message-passing where the edge nodes quantize their updates before uploading to the parameter server. These features address the communications and scalability challenges in federated learning. We also show that FedPAQ achieves near-optimal theoretical guarantees for strongly convex and non-convex loss functions and empirically demonstrate the communication-computation tradeoff provided by our method.
Learning How to Dynamically Route Autonomous Vehicles on Shared Roads
Sep 09, 2019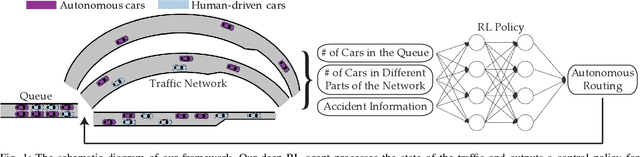
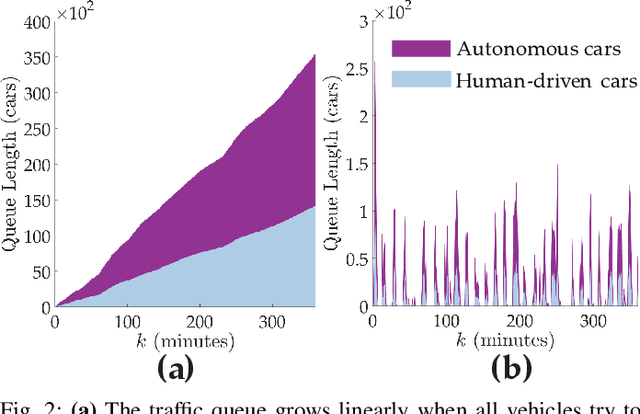

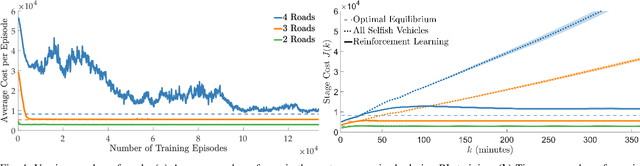
Road congestion induces significant costs across the world, and road network disturbances, such as traffic accidents, can cause highly congested traffic patterns. If a planner had control over the routing of all vehicles in the network, they could easily reverse this effect. In a more realistic scenario, we consider a planner that controls autonomous cars, which are a fraction of all present cars. We study a dynamic routing game, in which the route choices of autonomous cars can be controlled and the human drivers react selfishly and dynamically to autonomous cars' actions. As the problem is prohibitively large, we use deep reinforcement learning to learn a policy for controlling the autonomous vehicles. This policy influences human drivers to route themselves in such a way that minimizes congestion on the network. To gauge the effectiveness of our learned policies, we establish theoretical results characterizing equilibria on a network of parallel roads and empirically compare the learned policy results with best possible equilibria. Moreover, we show that in the absence of these policies, high demands and network perturbations would result in large congestion, whereas using the policy greatly decreases the travel times by minimizing the congestion. To the best of our knowledge, this is the first work that employs deep reinforcement learning to reduce congestion by influencing humans' routing decisions in mixed-autonomy traffic.
Sharp Guarantees for Solving Random Equations with One-Bit Information
Aug 12, 2019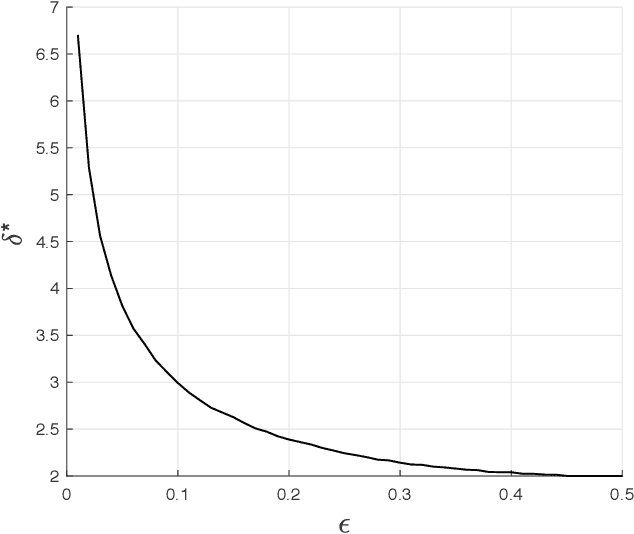
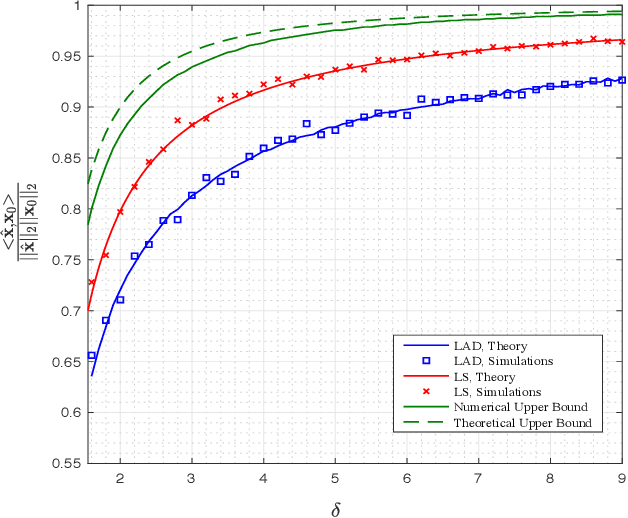
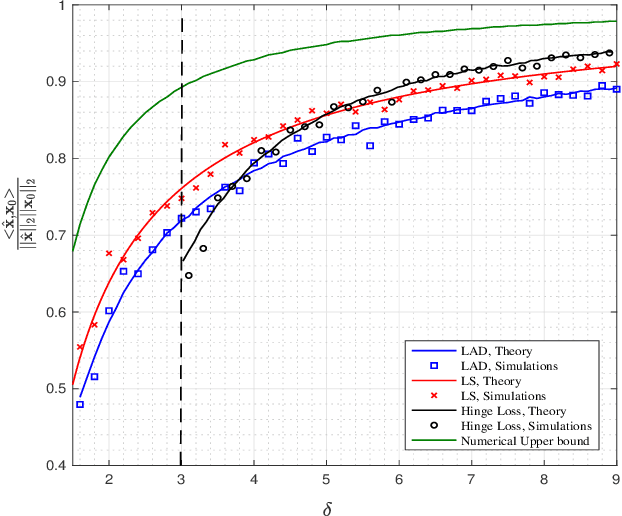
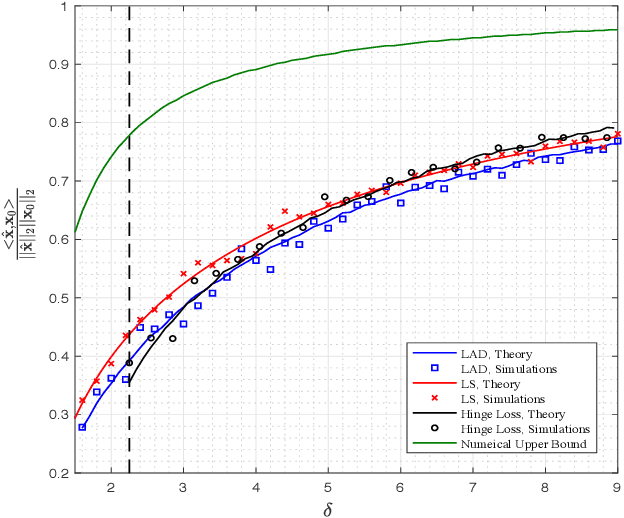
We study the performance of a wide class of convex optimization-based estimators for recovering a signal from corrupted one-bit measurements in high-dimensions. Our general result predicts sharply the performance of such estimators in the linear asymptotic regime when the measurement vectors have entries IID Gaussian. This includes, as a special case, the previously studied least-squares estimator and various novel results for other popular estimators such as least-absolute deviations, hinge-loss and logistic-loss. Importantly, we exploit the fact that our analysis holds for generic convex loss functions to prove a bound on the best achievable performance across the entire class of estimators. Numerical simulations corroborate our theoretical findings and suggest they are accurate even for relatively small problem dimensions.
Robust and Communication-Efficient Collaborative Learning
Jul 24, 2019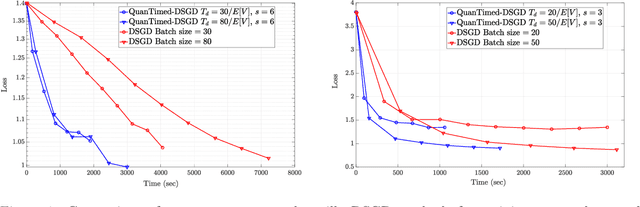
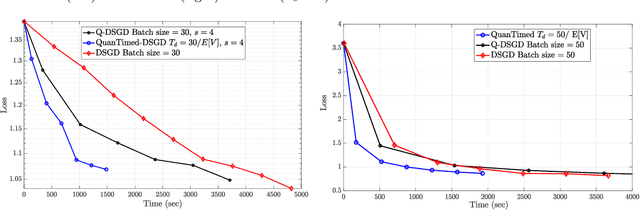
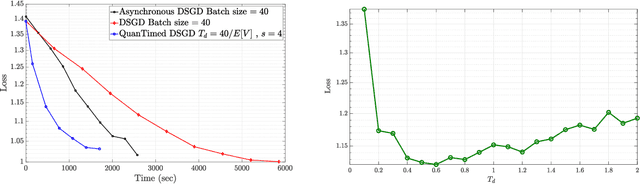
We consider a decentralized learning problem, where a set of computing nodes aim at solving a non-convex optimization problem collaboratively. It is well-known that decentralized optimization schemes face two major system bottlenecks: stragglers' delay and communication overhead. In this paper, we tackle these bottlenecks by proposing a novel decentralized and gradient-based optimization algorithm named as QuanTimed-DSGD. Our algorithm stands on two main ideas: (i) we impose a deadline on the local gradient computations of each node at each iteration of the algorithm, and (ii) the nodes exchange quantized versions of their local models. The first idea robustifies to straggling nodes and the second alleviates communication efficiency. The key technical contribution of our work is to prove that with non-vanishing noises for quantization and stochastic gradients, the proposed method exactly converges to the global optimal for convex loss functions, and finds a first-order stationary point in non-convex scenarios. Our numerical evaluations of the QuanTimed-DSGD on training benchmark datasets, MNIST and CIFAR-10, demonstrate speedups of up to 3x in run-time, compared to state-of-the-art decentralized optimization methods.
The Green Choice: Learning and Influencing Human Decisions on Shared Roads
Apr 10, 2019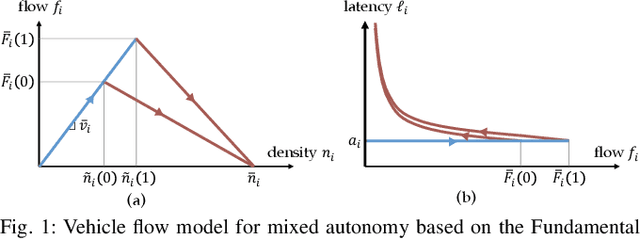
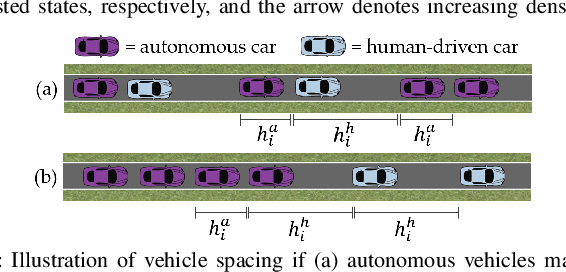
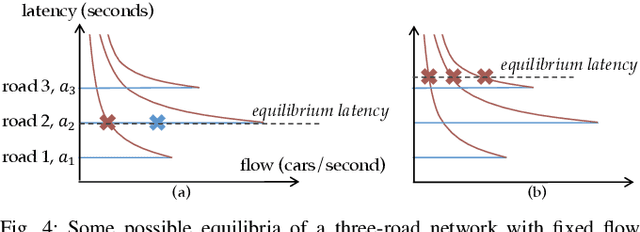
Autonomous vehicles have the potential to increase the capacity of roads via platooning, even when human drivers and autonomous vehicles share roads. However, when users of a road network choose their routes selfishly, the resulting traffic configuration may be very inefficient. Because of this, we consider how to influence human decisions so as to decrease congestion on these roads. We consider a network of parallel roads with two modes of transportation: (i) human drivers who will choose the quickest route available to them, and (ii) ride hailing service which provides an array of autonomous vehicle ride options, each with different prices, to users. In this work, we seek to design these prices so that when autonomous service users choose from these options and human drivers selfishly choose their resulting routes, road usage is maximized and transit delay is minimized. To do so, we formalize a model of how autonomous service users make choices between routes with different price/delay values. Developing a preference-based algorithm to learn the preferences of the users, and using a vehicle flow model related to the Fundamental Diagram of Traffic, we formulate a planning optimization to maximize a social objective and demonstrate the benefit of the proposed routing and learning scheme.
CodedReduce: A Fast and Robust Framework for Gradient Aggregation in Distributed Learning
Feb 06, 2019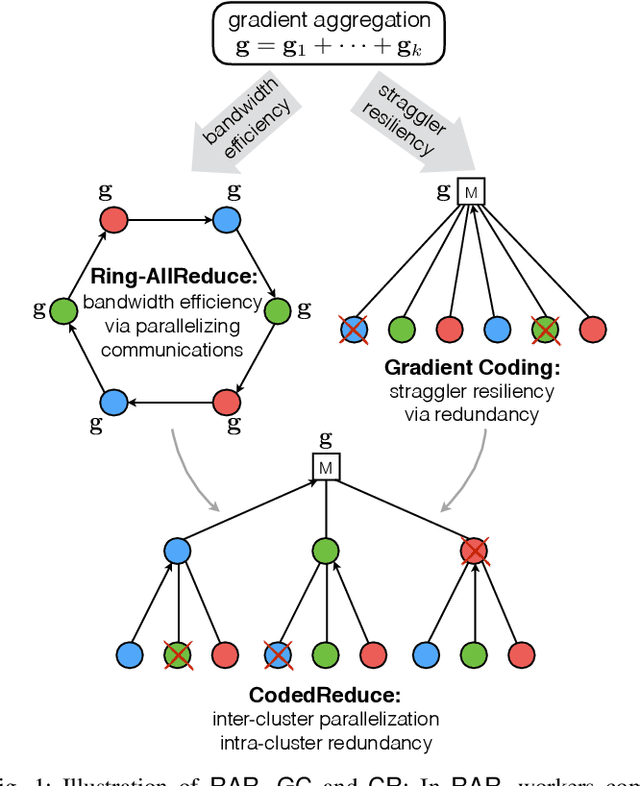
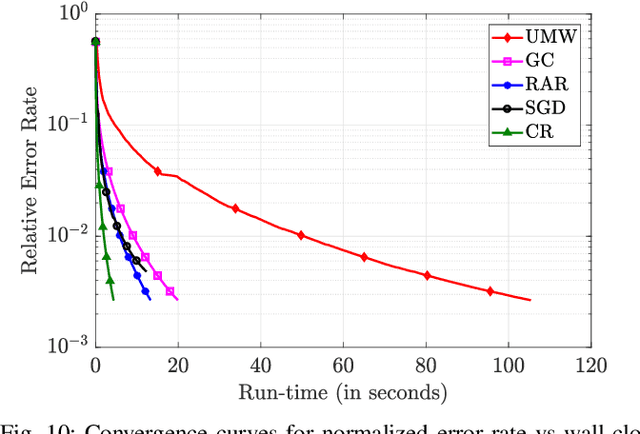
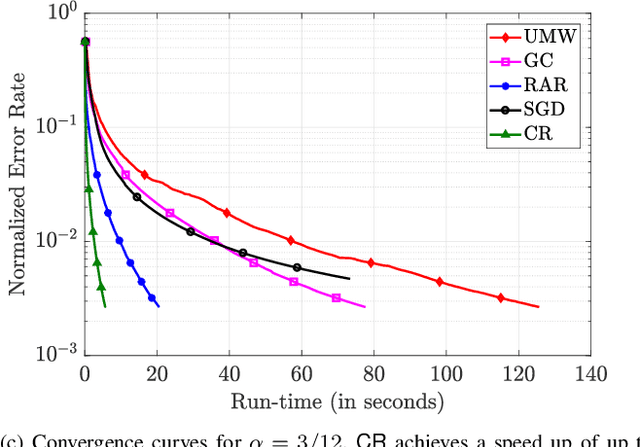
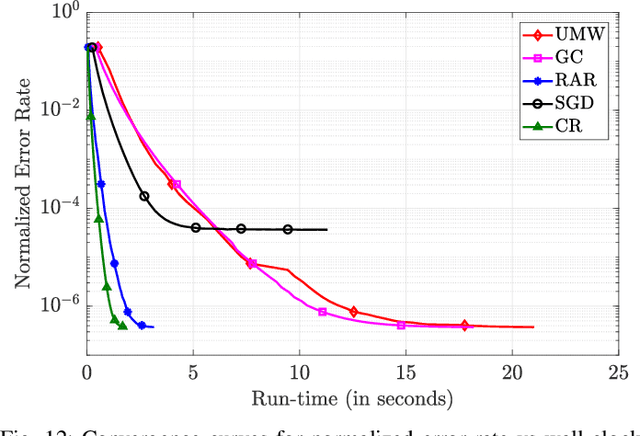
We focus on the commonly used synchronous Gradient Descent paradigm for large-scale distributed learning, for which there has been a growing interest to develop efficient and robust gradient aggregation strategies that overcome two key bottlenecks: communication bandwidth and stragglers' delays. In particular, Ring-AllReduce (RAR) design has been proposed to avoid bandwidth bottleneck at any particular node by allowing each worker to only communicate with its neighbors that are arranged in a logical ring. On the other hand, Gradient Coding (GC) has been recently proposed to mitigate stragglers in a master-worker topology by allowing carefully designed redundant allocation of the data set to the workers. We propose a joint communication topology design and data set allocation strategy, named CodedReduce (CR), that combines the best of both RAR and GC. That is, it parallelizes the communications over a tree topology leading to efficient bandwidth utilization, and carefully designs a redundant data set allocation and coding strategy at the nodes to make the proposed gradient aggregation scheme robust to stragglers. In particular, we quantify the communication parallelization gain and resiliency of the proposed CR scheme, and prove its optimality when the communication topology is a regular tree. Furthermore, we empirically evaluate the performance of our proposed CR design over Amazon EC2 and demonstrate that it achieves speedups of up to 18.9x and 7.9x, respectively over the benchmarks GC and RAR.
Altruistic Autonomy: Beating Congestion on Shared Roads
Oct 29, 2018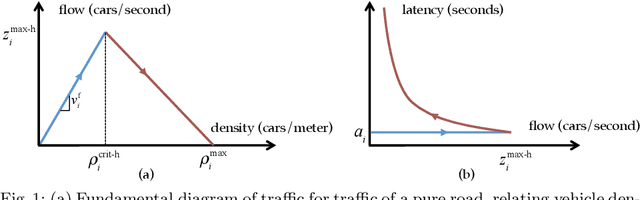
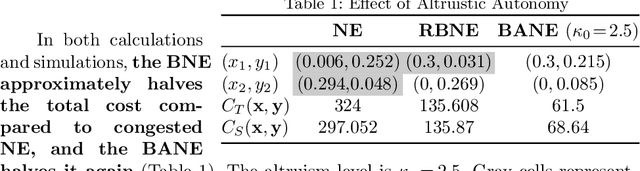
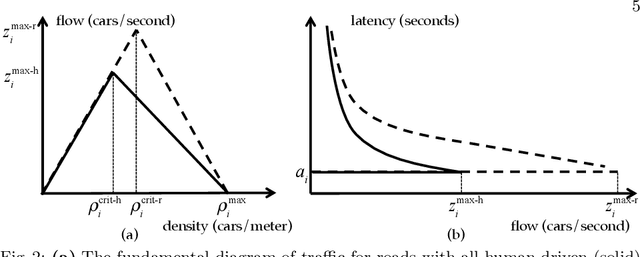
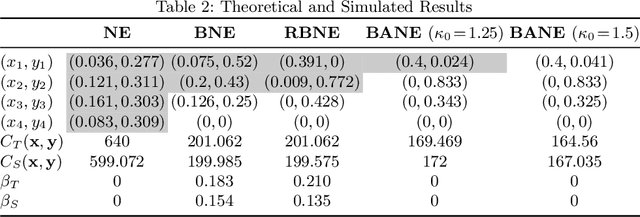
Traffic congestion has large economic and social costs. The introduction of autonomous vehicles can potentially reduce this congestion, both by increasing network throughput and by enabling a social planner to incentivize users of autonomous vehicles to take longer routes that can alleviate congestion on more direct roads. We formalize the effects of altruistic autonomy on roads shared between human drivers and autonomous vehicles. In this work, we develop a formal model of road congestion on shared roads based on the fundamental diagram of traffic. We consider a network of parallel roads and provide algorithms that compute optimal equilibria that are robust to additional unforeseen demand. We further plan for optimal routings when users have varying degrees of altruism. We find that even with arbitrarily small altruism, total latency can be unboundedly better than without altruism, and that the best selfish equilibrium can be unboundedly better than the worst selfish equilibrium. We validate our theoretical results through microscopic traffic simulations and show average latency decrease of a factor of 4 from worst-case selfish equilibrium to the optimal equilibrium when autonomous vehicles are altruistic.
Toward Robust Neural Networks via Sparsification
Oct 24, 2018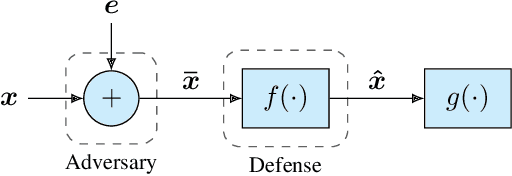
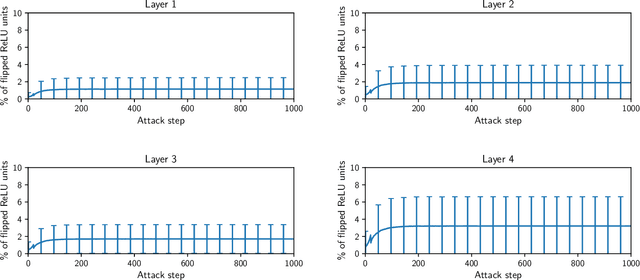

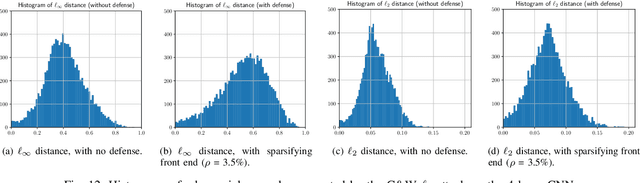
It is by now well-known that small adversarial perturbations can induce classification errors in deep neural networks. In this paper, we make the case that a systematic exploitation of sparsity is key to defending against such attacks, and that a "locally linear" model for neural networks can be used to develop a theoretical foundation for crafting attacks and defenses. We consider two defenses. The first is a sparsifying front end, which attenuates the impact of the attack by a factor of roughly $K/N$ where $N$ is the data dimension and $K$ is the sparsity level. The second is sparsification of network weights, which attenuates the worst-case growth of an attack as it flows up the network. We also devise attacks based on the locally linear model that outperform the well-known FGSM attack. We provide experimental results for the MNIST and Fashion-MNIST datasets, showing the efficacy of the proposed sparsity-based defenses.
Maximizing Road Capacity Using Cars that Influence People
Oct 09, 2018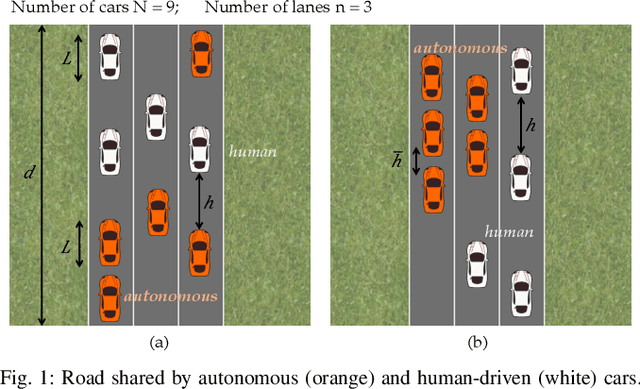
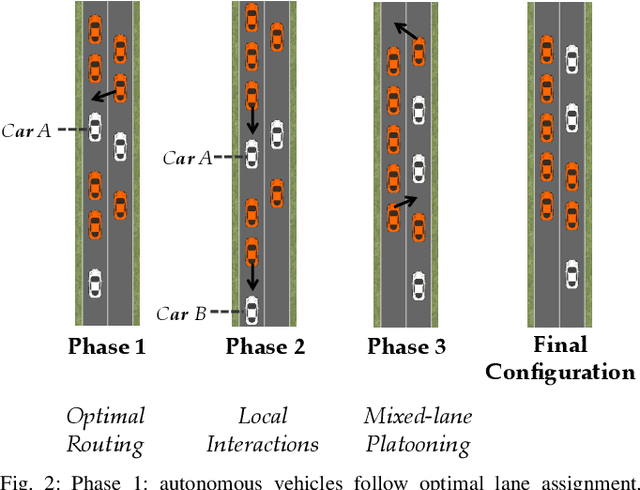
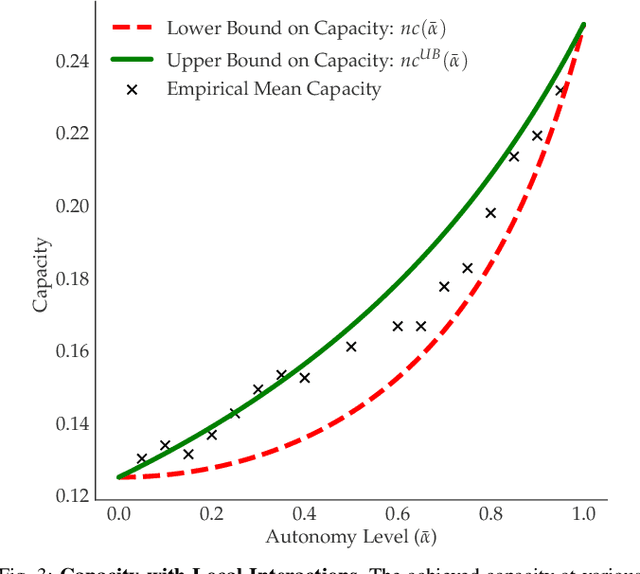
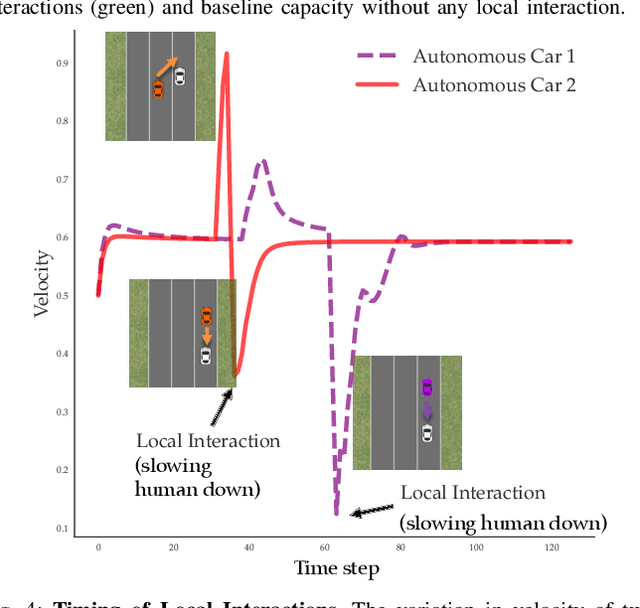
The emerging technology enabling autonomy in vehicles has led to a variety of new problems in transportation networks, such as planning and perception for autonomous vehicles. Other works consider social objectives such as decreasing fuel consumption and travel time by platooning. However, these strategies are limited by the actions of the surrounding human drivers. In this paper, we consider proactively achieving these social objectives by influencing human behavior through planned interactions. Our key insight is that we can use these social objectives to design local interactions that influence human behavior to achieve these goals. To this end, we characterize the increase in road capacity afforded by platooning, as well as the vehicle configuration that maximizes road capacity. We present a novel algorithm that uses a low-level control framework to leverage local interactions to optimally rearrange vehicles. We showcase our algorithm using a simulated road shared between autonomous and human-driven vehicles, in which we illustrate the reordering in action.