 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding Up Distributed Machine Learning Using Codes
Paper and Code
Jan 29, 2018
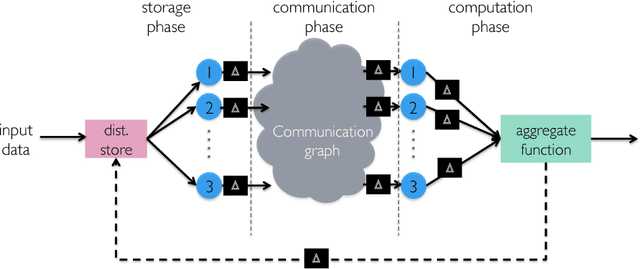
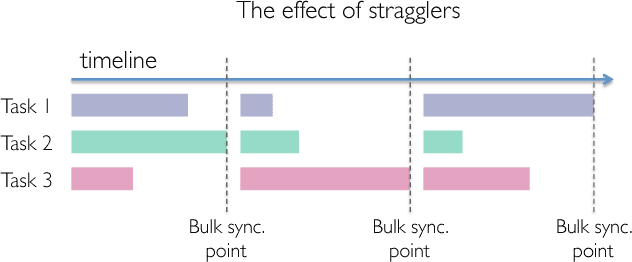
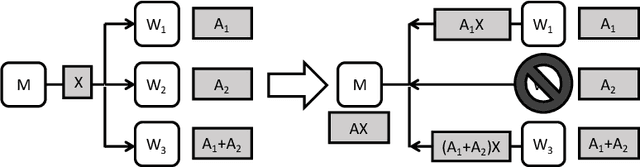
Codes are widely used in many engineering applications to offer robustness against noise. In large-scale systems there are several types of noise that can affect the performance of distributed machine learning algorithms -- straggler nodes, system failures, or communication bottlenecks -- but there has been little interaction cutting across codes, machine learning, and distributed systems. In this work, we provide theoretical insights on how coded solutions can achieve significant gains compared to uncoded ones. We focus on two of the most basic building blocks of distributed learning algorithms: matrix multiplication and data shuffling. For matrix multiplication, we use codes to alleviate the effect of stragglers, and show that if the number of homogeneous workers is $n$, and the runtime of each subtask has an exponential tail, coded computation can speed up distributed matrix multiplication by a factor of $\log n$. For data shuffling, we use codes to reduce communication bottlenecks, exploiting the excess in storage. We show that when a constant fraction $\alpha$ of the data matrix can be cached at each worker, and $n$ is the number of workers, \emph{coded shuffling} reduces the communication cost by a factor of $(\alpha + \frac{1}{n})\gamma(n)$ compared to uncoded shuffling, where $\gamma(n)$ is the ratio of the cost of unicasting $n$ messages to $n$ users to multicasting a common message (of the same size) to $n$ users. For instance, $\gamma(n) \simeq n$ if multicasting a message to $n$ users is as cheap as unicasting a message to one user. We also provide experiment results, corroborating our theoretical gains of the coded algorithms.