 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeDPO: Debiased Direct Preference Optimization for Diffusion Models
Feb 05, 2026Direct Preference Optimization (DPO) has emerged as a predominant alignment method for diffusion models, facilitating off-policy training without explicit reward modeling. However, its reliance on large-scale, high-quality human preference labels presents a severe cost and scalability bottleneck. To overcome this, We propose a semi-supervised framework augmenting limited human data with a large corpus of unlabeled pairs annotated via cost-effective synthetic AI feedback. Our paper introduces Debiased DPO (DeDPO), which uniquely integrates a debiased estimation technique from causal inference into the DPO objective. By explicitly identifying and correcting the systematic bias and noise inherent in synthetic annotators, DeDPO ensures robust learning from imperfect feedback sources, including self-training and Vision-Language Models (VLMs). Experiments demonstrate that DeDPO is robust to the variations in synthetic labeling methods, achieving performance that matches and occasionally exceeds the theoretical upper bound of models trained on fully human-labeled data. This establishes DeDPO as a scalable solution for human-AI alignment using inexpensive synthetic supervision.
DIRI: Adversarial Patient Reidentification with Large Language Models for Evaluating Clinical Text Anonymization
Oct 22, 2024Sharing protected health information (PHI) is critical for furthering biomedical research. Before data can be distributed, practitioners often perform deidentification to remove any PHI contained in the text. Contemporary deidentification methods are evaluated on highly saturated datasets (tools achieve near-perfect accuracy) which may not reflect the full variability or complexity of real-world clinical text and annotating them is resource intensive, which is a barrier to real-world applications. To address this gap, we developed an adversarial approach using a large language model (LLM) to re-identify the patient corresponding to a redacted clinical note and evaluated the performance with a novel De-Identification/Re-Identification (DIRI) method. Our method uses a large language model to reidentify the patient corresponding to a redacted clinical note. We demonstrate our method on medical data from Weill Cornell Medicine anonymized with three deidentification tools: rule-based Philter and two deep-learning-based models, BiLSTM-CRF and ClinicalBERT. Although ClinicalBERT was the most effective, masking all identified PII, our tool still reidentified 9% of clinical notes Our study highlights significant weaknesses in current deidentification technologies while providing a tool for iterative development and improvement.
Chimera: Effectively Modeling Multivariate Time Series with 2-Dimensional State Space Models
Jun 06, 2024



Modeling multivariate time series is a well-established problem with a wide range of applications from healthcare to financial markets. Traditional State Space Models (SSMs) are classical approaches for univariate time series modeling due to their simplicity and expressive power to represent linear dependencies. They, however, have fundamentally limited expressive power to capture non-linear dependencies, are slow in practice, and fail to model the inter-variate information flow. Despite recent attempts to improve the expressive power of SSMs by using deep structured SSMs, the existing methods are either limited to univariate time series, fail to model complex patterns (e.g., seasonal patterns), fail to dynamically model the dependencies of variate and time dimensions, and/or are input-independent. We present Chimera that uses two input-dependent 2-D SSM heads with different discretization processes to learn long-term progression and seasonal patterns. To improve the efficiency of complex 2D recurrence, we present a fast training using a new 2-dimensional parallel selective scan. We further present and discuss 2-dimensional Mamba and Mamba-2 as the spacial cases of our 2D SSM. Our experimental evaluation shows the superior performance of Chimera on extensive and diverse benchmarks, including ECG and speech time series classification, long-term and short-term time series forecasting, and time series anomaly detection.
DreamWalk: Style Space Exploration using Diffusion Guidance
Apr 04, 2024Text-conditioned diffusion models can generate impressive images, but fall short when it comes to fine-grained control. Unlike direct-editing tools like Photoshop, text conditioned models require the artist to perform "prompt engineering," constructing special text sentences to control the style or amount of a particular subject present in the output image. Our goal is to provide fine-grained control over the style and substance specified by the prompt, for example to adjust the intensity of styles in different regions of the image (Figure 1). Our approach is to decompose the text prompt into conceptual elements, and apply a separate guidance term for each element in a single diffusion process. We introduce guidance scale functions to control when in the diffusion process and \emph{where} in the image to intervene. Since the method is based solely on adjusting diffusion guidance, it does not require fine-tuning or manipulating the internal layers of the diffusion model's neural network, and can be used in conjunction with LoRA- or DreamBooth-trained models (Figure2). Project page: https://mshu1.github.io/dreamwalk.github.io/
MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection
Mar 29, 2024Recent advances in deep learning have mainly relied on Transformers due to their data dependency and ability to learn at scale. The attention module in these architectures, however, exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are either data independent, or fail to allow inter- and intra-dimension communication. Recently, State Space Models (SSMs), and more specifically Selective State Space Models, with efficient hardware-aware implementation, have shown promising potential for long sequence modeling. Motivated by the success of SSMs, we present MambaMixer, a new architecture with data-dependent weights that uses a dual selection mechanism across tokens and channels, called Selective Token and Channel Mixer. MambaMixer connects selective mixers using a weighted averaging mechanism, allowing layers to have direct access to early features. As a proof of concept, we design Vision MambaMixer (ViM2) and Time Series MambaMixer (TSM2) architectures based on the MambaMixer block and explore their performance in various vision and time series forecasting tasks. Our results underline the importance of selective mixing across both tokens and channels. In ImageNet classification, object detection, and semantic segmentation tasks, ViM2 achieves competitive performance with well-established vision models and outperforms SSM-based vision models. In time series forecasting, TSM2 achieves outstanding performance compared to state-of-the-art methods while demonstrating significantly improved computational cost. These results show that while Transformers, cross-channel attention, and MLPs are sufficient for good performance in time series forecasting, neither is necessary.
Stable Estimation of Survival Causal Effects
Oct 01, 2023We study the problem of estimating survival causal effects, where the aim is to characterize the impact of an intervention on survival times, i.e., how long it takes for an event to occur. Applications include determining if a drug reduces the time to ICU discharge or if an advertising campaign increases customer dwell time. Historically, the most popular estimates have been based on parametric or semiparametric (e.g. proportional hazards) models; however, these methods suffer from problematic levels of bias. Recently debiased machine learning approaches are becoming increasingly popular, especially in applications to large datasets. However, despite their appealing theoretical properties, these estimators tend to be unstable because the debiasing step involves the use of the inverses of small estimated probabilities -- small errors in the estimated probabilities can result in huge changes in their inverses and therefore the resulting estimator. This problem is exacerbated in survival settings where probabilities are a product of treatment assignment and censoring probabilities. We propose a covariate balancing approach to estimating these inverses directly, sidestepping this problem. The result is an estimator that is stable in practice and enjoys many of the same theoretical properties. In particular, under overlap and asymptotic equicontinuity conditions, our estimator is asymptotically normal with negligible bias and optimal variance. Our experiments on synthetic and semi-synthetic data demonstrate that our method has competitive bias and smaller variance than debiased machine learning approaches.
Distribution Normalization: An "Effortless" Test-Time Augmentation for Contrastively Learned Visual-language Models
Feb 22, 2023Advances in the field of visual-language contrastive learning have made it possible for many downstream applications to be carried out efficiently and accurately by simply taking the dot product between image and text representations. One of the most representative approaches proposed recently known as CLIP has quickly garnered widespread adoption due to its effectiveness. CLIP is trained with an InfoNCE loss that takes into account both positive and negative samples to help learn a much more robust representation space. This paper however reveals that the common downstream practice of taking a dot product is only a zeroth-order approximation of the optimization goal, resulting in a loss of information during test-time. Intuitively, since the model has been optimized based on the InfoNCE loss, test-time procedures should ideally also be in alignment. The question lies in how one can retrieve any semblance of negative samples information during inference. We propose Distribution Normalization (DN), where we approximate the mean representation of a batch of test samples and use such a mean to represent what would be analogous to negative samples in the InfoNCE loss. DN requires no retraining or fine-tuning and can be effortlessly applied during inference. Extensive experiments on a wide variety of downstream tasks exhibit a clear advantage of DN over the dot product.
Dimensions of Motion: Learning to Predict a Subspace of Optical Flow from a Single Image
Jan 06, 2022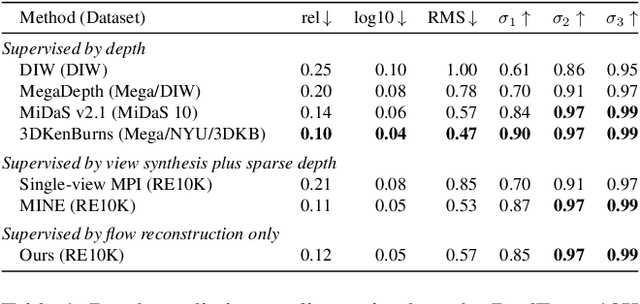
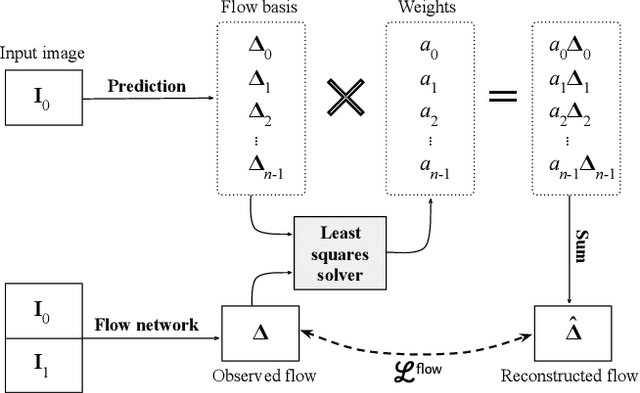
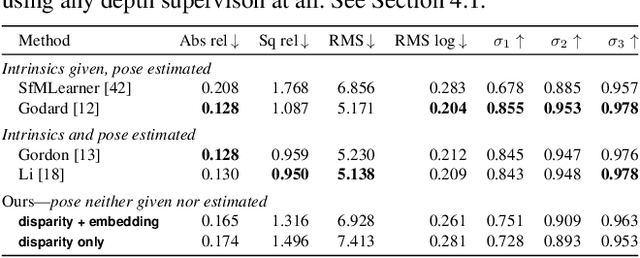
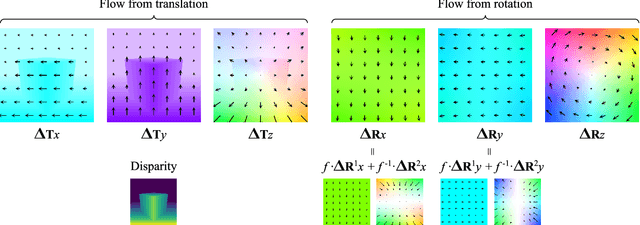
We introduce the problem of predicting, from a single video frame, a low-dimensional subspace of optical flow which includes the actual instantaneous optical flow. We show how several natural scene assumptions allow us to identify an appropriate flow subspace via a set of basis flow fields parameterized by disparity and a representation of object instances. The flow subspace, together with a novel loss function, can be used for the tasks of predicting monocular depth or predicting depth plus an object instance embedding. This provides a new approach to learning these tasks in an unsupervised fashion using monocular input video without requiring camera intrinsics or poses.
Pyramid Adversarial Training Improves ViT Performance
Nov 30, 2021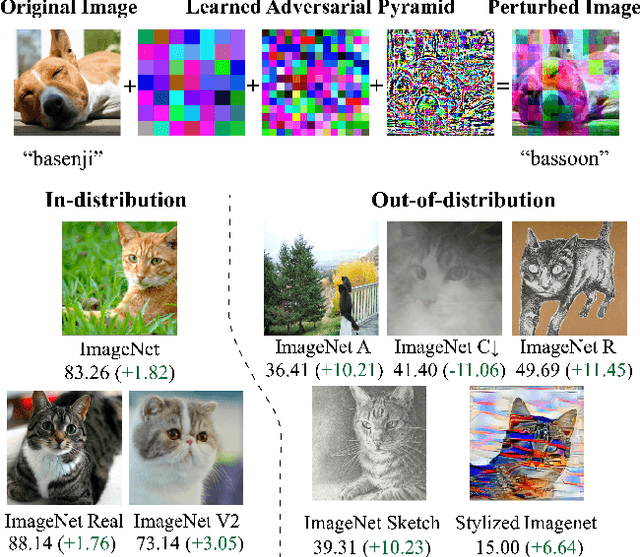
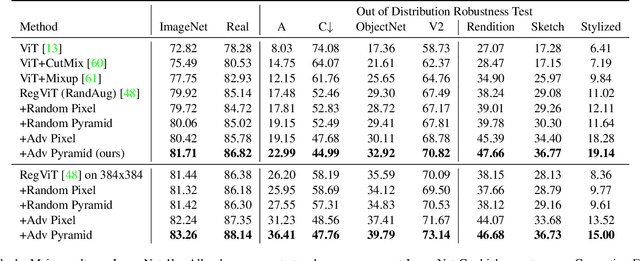

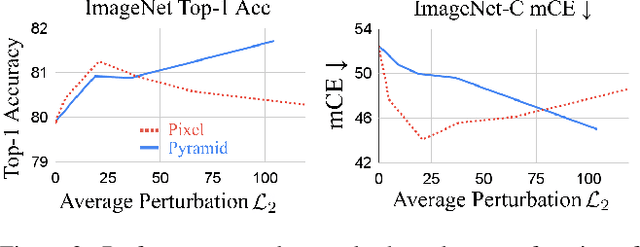
Aggressive data augmentation is a key component of the strong generalization capabilities of Vision Transformer (ViT). One such data augmentation technique is adversarial training; however, many prior works have shown that this often results in poor clean accuracy. In this work, we present Pyramid Adversarial Training, a simple and effective technique to improve ViT's overall performance. We pair it with a "matched" Dropout and stochastic depth regularization, which adopts the same Dropout and stochastic depth configuration for the clean and adversarial samples. Similar to the improvements on CNNs by AdvProp (not directly applicable to ViT), our Pyramid Adversarial Training breaks the trade-off between in-distribution accuracy and out-of-distribution robustness for ViT and related architectures. It leads to $1.82\%$ absolute improvement on ImageNet clean accuracy for the ViT-B model when trained only on ImageNet-1K data, while simultaneously boosting performance on $7$ ImageNet robustness metrics, by absolute numbers ranging from $1.76\%$ to $11.45\%$. We set a new state-of-the-art for ImageNet-C (41.4 mCE), ImageNet-R ($53.92\%$), and ImageNet-Sketch ($41.04\%$) without extra data, using only the ViT-B/16 backbone and our Pyramid Adversarial Training. Our code will be publicly available upon acceptance.
Deep survival analysis with longitudinal X-rays for COVID-19
Aug 22, 2021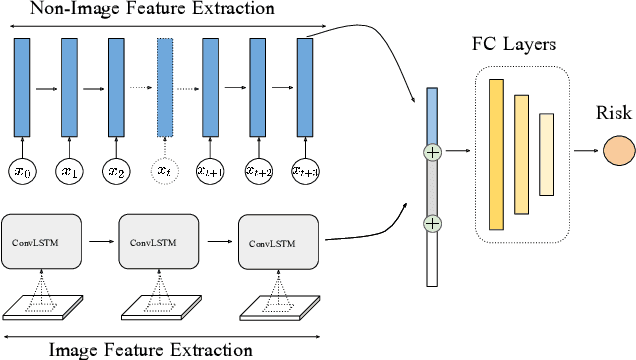
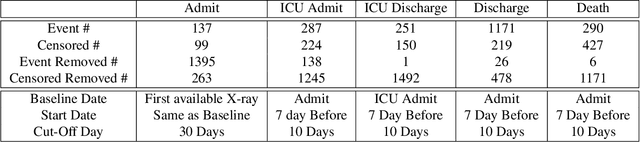
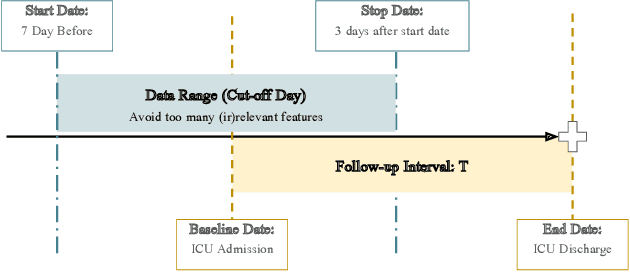
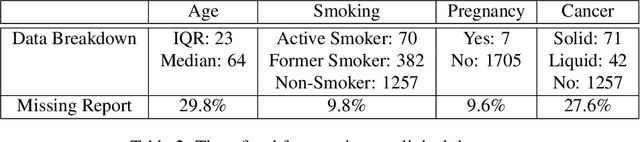
Time-to-event analysis is an important statistical tool for allocating clinical resources such as ICU beds. However, classical techniques like the Cox model cannot directly incorporate images due to their high dimensionality. We propose a deep learning approach that naturally incorporates multiple, time-dependent imaging studies as well as non-imaging data into time-to-event analysis. Our techniques are benchmarked on a clinical dataset of 1,894 COVID-19 patients, and show that image sequences significantly improve predictions. For example, classical time-to-event methods produce a concordance error of around 30-40% for predicting hospital admission, while our error is 25% without images and 20% with multiple X-rays included. Ablation studies suggest that our models are not learning spurious features such as scanner artifacts. While our focus and evaluation is on COVID-19, the methods we develop are broadly applicable.