 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Size and Approximation Error of Distilled Sets
May 23, 2023



Dataset Distillation is the task of synthesizing small datasets from large ones while still retaining comparable predictive accuracy to the original uncompressed dataset. Despite significant empirical progress in recent years, there is little understanding of the theoretical limitations/guarantees of dataset distillation, specifically, what excess risk is achieved by distillation compared to the original dataset, and how large are distilled datasets? In this work, we take a theoretical view on kernel ridge regression (KRR) based methods of dataset distillation such as Kernel Inducing Points. By transforming ridge regression in random Fourier features (RFF) space, we provide the first proof of the existence of small (size) distilled datasets and their corresponding excess risk for shift-invariant kernels. We prove that a small set of instances exists in the original input space such that its solution in the RFF space coincides with the solution of the original data. We further show that a KRR solution can be generated using this distilled set of instances which gives an approximation towards the KRR solution optimized on the full input data. The size of this set is linear in the dimension of the RFF space of the input set or alternatively near linear in the number of effective degrees of freedom, which is a function of the kernel, number of datapoints, and the regularization parameter $\lambda$. The error bound of this distilled set is also a function of $\lambda$. We verify our bounds analytically and empirically.
Learning Stability Attention in Vision-based End-to-end Driving Policies
Apr 05, 2023Modern end-to-end learning systems can learn to explicitly infer control from perception. However, it is difficult to guarantee stability and robustness for these systems since they are often exposed to unstructured, high-dimensional, and complex observation spaces (e.g., autonomous driving from a stream of pixel inputs). We propose to leverage control Lyapunov functions (CLFs) to equip end-to-end vision-based policies with stability properties and introduce stability attention in CLFs (att-CLFs) to tackle environmental changes and improve learning flexibility. We also present an uncertainty propagation technique that is tightly integrated into att-CLFs. We demonstrate the effectiveness of att-CLFs via comparison with classical CLFs, model predictive control, and vanilla end-to-end learning in a photo-realistic simulator and on a real full-scale autonomous vehicle.
Infrastructure-based End-to-End Learning and Prevention of Driver Failure
Mar 21, 2023



Intelligent intersection managers can improve safety by detecting dangerous drivers or failure modes in autonomous vehicles, warning oncoming vehicles as they approach an intersection. In this work, we present FailureNet, a recurrent neural network trained end-to-end on trajectories of both nominal and reckless drivers in a scaled miniature city. FailureNet observes the poses of vehicles as they approach an intersection and detects whether a failure is present in the autonomy stack, warning cross-traffic of potentially dangerous drivers. FailureNet can accurately identify control failures, upstream perception errors, and speeding drivers, distinguishing them from nominal driving. The network is trained and deployed with autonomous vehicles in the MiniCity. Compared to speed or frequency-based predictors, FailureNet's recurrent neural network structure provides improved predictive power, yielding upwards of 84% accuracy when deployed on hardware.
Dataset Distillation with Convexified Implicit Gradients
Feb 13, 2023We propose a new dataset distillation algorithm using reparameterization and convexification of implicit gradients (RCIG), that substantially improves the state-of-the-art. To this end, we first formulate dataset distillation as a bi-level optimization problem. Then, we show how implicit gradients can be effectively used to compute meta-gradient updates. We further equip the algorithm with a convexified approximation that corresponds to learning on top of a frozen finite-width neural tangent kernel. Finally, we improve bias in implicit gradients by parameterizing the neural network to enable analytical computation of final-layer parameters given the body parameters. RCIG establishes the new state-of-the-art on a diverse series of dataset distillation tasks. Notably, with one image per class, on resized ImageNet, RCIG sees on average a 108% improvement over the previous state-of-the-art distillation algorithm. Similarly, we observed a 66% gain over SOTA on Tiny-ImageNet and 37% on CIFAR-100.
Dataset Distillation Fixes Dataset Reconstruction Attacks
Feb 02, 2023

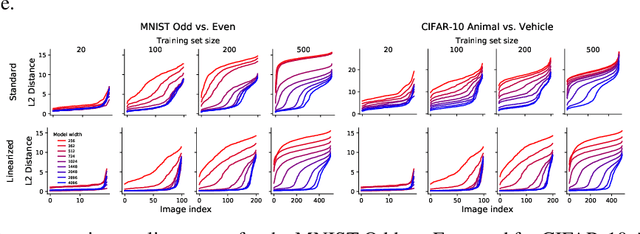
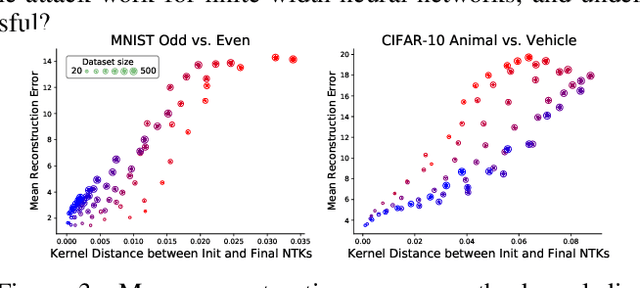
Modern deep learning requires large volumes of data, which could contain sensitive or private information which cannot be leaked. Recent work has shown for homogeneous neural networks a large portion of this training data could be reconstructed with only access to the trained network parameters. While the attack was shown to work empirically, there exists little formal understanding of its effectiveness regime, and ways to defend against it. In this work, we first build a stronger version of the dataset reconstruction attack and show how it can provably recover its entire training set in the infinite width regime. We then empirically study the characteristics of this attack on two-layer networks and reveal that its success heavily depends on deviations from the frozen infinite-width Neural Tangent Kernel limit. More importantly, we formally show for the first time that dataset reconstruction attacks are a variation of dataset distillation. This key theoretical result on the unification of dataset reconstruction and distillation not only sheds more light on the characteristics of the attack but enables us to design defense mechanisms against them via distillation algorithms.
Cooperative Flight Control Using Visual-Attention -- Air-Guardian
Dec 21, 2022



The cooperation of a human pilot with an autonomous agent during flight control realizes parallel autonomy. A parallel-autonomous system acts as a guardian that significantly enhances the robustness and safety of flight operations in challenging circumstances. Here, we propose an air-guardian concept that facilitates cooperation between an artificial pilot agent and a parallel end-to-end neural control system. Our vision-based air-guardian system combines a causal continuous-depth neural network model with a cooperation layer to enable parallel autonomy between a pilot agent and a control system based on perceived differences in their attention profile. The attention profiles are obtained by computing the networks' saliency maps (feature importance) through the VisualBackProp algorithm. The guardian agent is trained via reinforcement learning in a fixed-wing aircraft simulated environment. When the attention profile of the pilot and guardian agents align, the pilot makes control decisions. If the attention map of the pilot and the guardian do not align, the air-guardian makes interventions and takes over the control of the aircraft. We show that our attention-based air-guardian system can balance the trade-off between its level of involvement in the flight and the pilot's expertise and attention. We demonstrate the effectivness of our methods in simulated flight scenarios with a fixed-wing aircraft and on a real drone platform.
Interpreting Neural Policies with Disentangled Tree Representations
Oct 13, 2022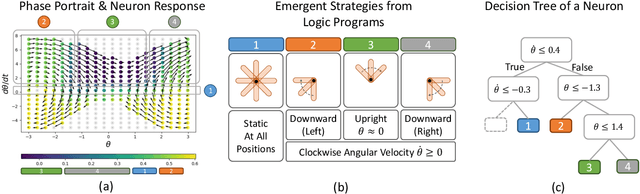
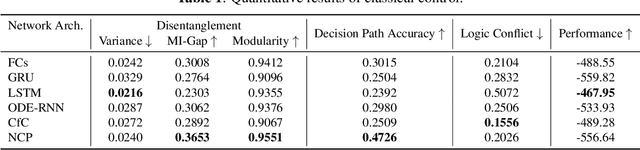
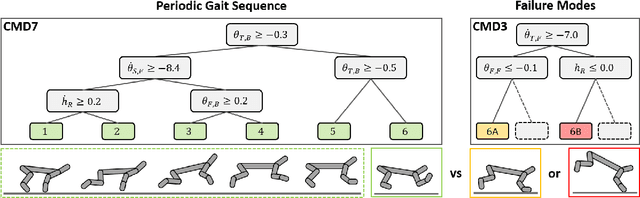
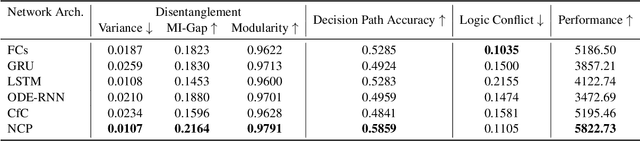
Compact neural networks used in policy learning and closed-loop end-to-end control learn representations from data that encapsulate agent dynamics and potentially the agent-environment's factors of variation. A formal and quantitative understanding and interpretation of these explanatory factors in neural representations is difficult to achieve due to the complex and intertwined correspondence of neural activities with emergent behaviors. In this paper, we design a new algorithm that programmatically extracts tree representations from compact neural policies, in the form of a set of logic programs grounded by the world state. To assess how well networks uncover the dynamics of the task and their factors of variation, we introduce interpretability metrics that measure the disentanglement of learned neural dynamics from a concentration of decisions, mutual information, and modularity perspectives. Moreover, our method allows us to quantify how accurate the extracted decision paths (explanations) are and computes cross-neuron logic conflict. We demonstrate the effectiveness of our approach with several types of compact network architectures on a series of end-to-end learning to control tasks.
On the Forward Invariance of Neural ODEs
Oct 10, 2022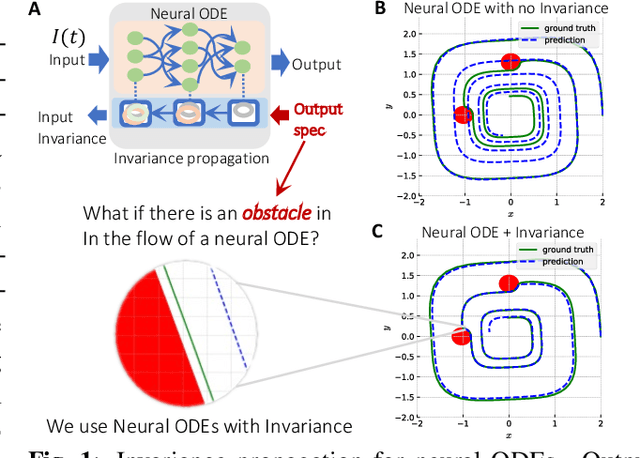

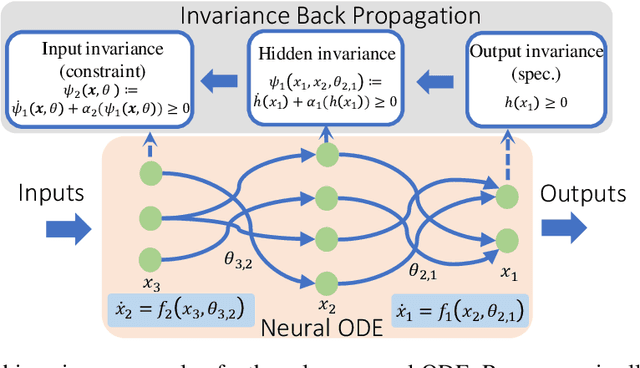
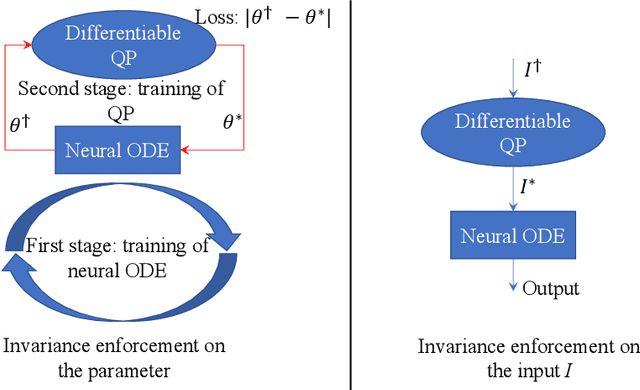
To ensure robust and trustworthy decision-making, it is highly desirable to enforce constraints over a neural network's parameters and its inputs automatically by back-propagating output specifications. This way, we can guarantee that the network makes reliable decisions under perturbations. Here, we propose a new method for achieving a class of specification guarantees for neural Ordinary Differentiable Equations (ODEs) by using invariance set propagation. An invariance of a neural ODE is defined as an output specification, such as to satisfy mathematical formulae, physical laws, and system safety. We use control barrier functions to specify the invariance of a neural ODE on the output layer and propagate it back to the input layer. Through the invariance backpropagation, we map output specifications onto constraints on the neural ODE parameters or its input. The satisfaction of the corresponding constraints implies the satisfaction of output specifications. This allows us to achieve output specification guarantees by changing the input or parameters while maximally preserving the model performance. We demonstrate the invariance propagation on a comprehensive series of representation learning tasks, including spiral curve regression, autoregressive modeling of joint physical dynamics, convexity portrait of a function, and safe neural control of collision avoidance for autonomous vehicles.
PyHopper -- Hyperparameter optimization
Oct 10, 2022
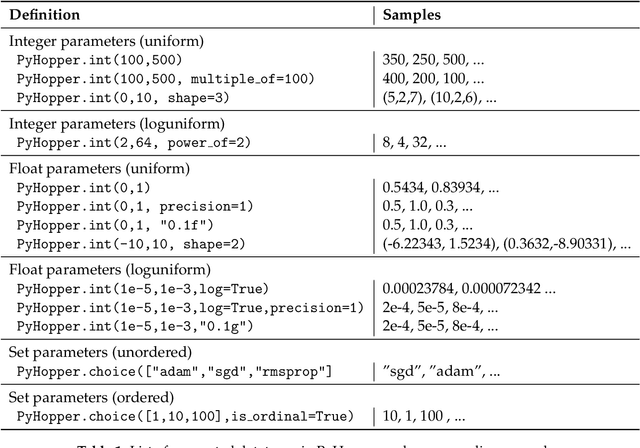
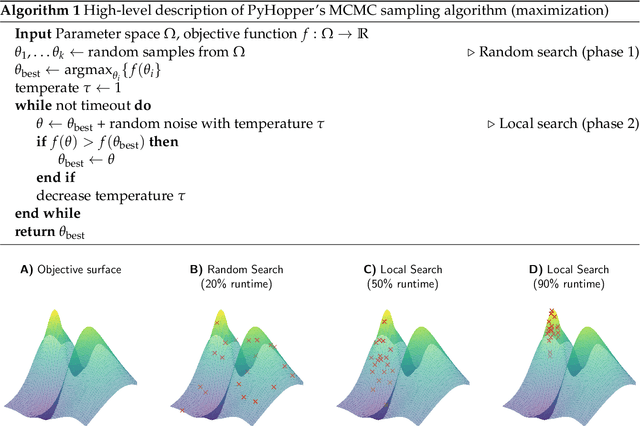
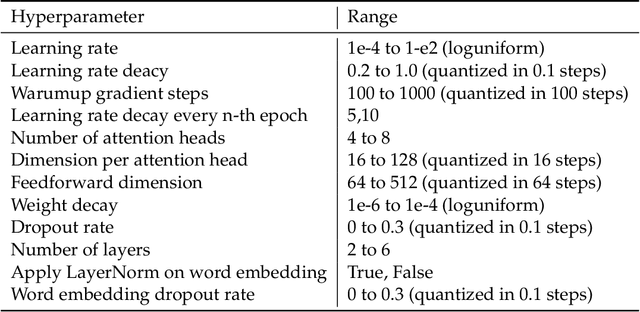
Hyperparameter tuning is a fundamental aspect of machine learning research. Setting up the infrastructure for systematic optimization of hyperparameters can take a significant amount of time. Here, we present PyHopper, a black-box optimization platform designed to streamline the hyperparameter tuning workflow of machine learning researchers. PyHopper's goal is to integrate with existing code with minimal effort and run the optimization process with minimal necessary manual oversight. With simplicity as the primary theme, PyHopper is powered by a single robust Markov-chain Monte-Carlo optimization algorithm that scales to millions of dimensions. Compared to existing tuning packages, focusing on a single algorithm frees the user from having to decide between several algorithms and makes PyHopper easily customizable. PyHopper is publicly available under the Apache-2.0 license at https://github.com/PyHopper/PyHopper.
Are All Vision Models Created Equal? A Study of the Open-Loop to Closed-Loop Causality Gap
Oct 09, 2022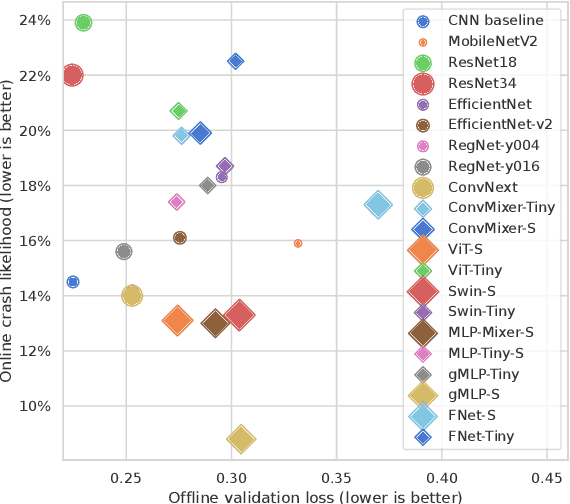
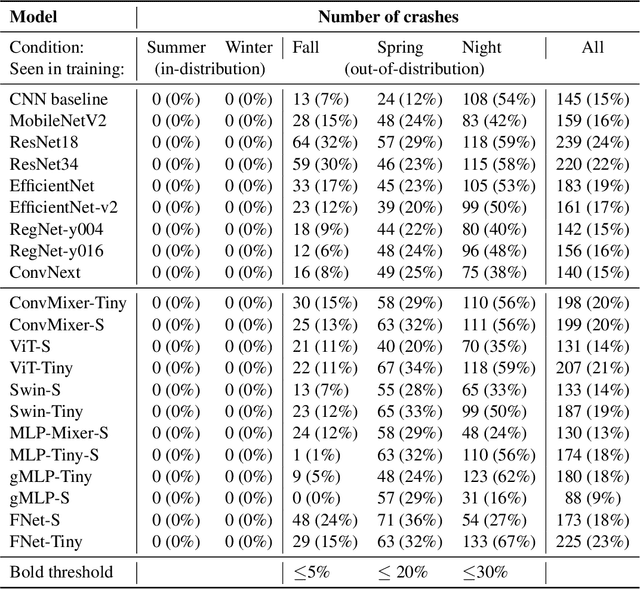

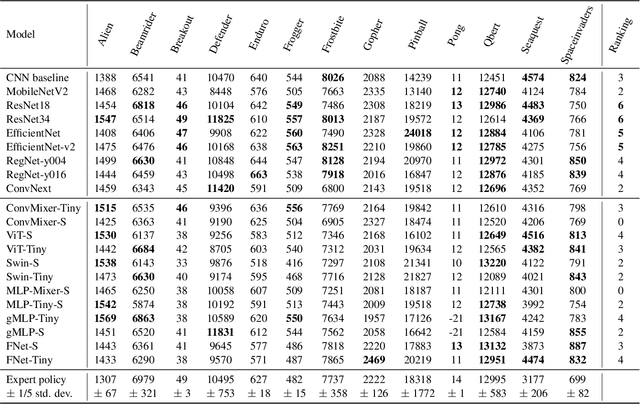
There is an ever-growing zoo of modern neural network models that can efficiently learn end-to-end control from visual observations. These advanced deep models, ranging from convolutional to patch-based networks, have been extensively tested on offline image classification and regression tasks. In this paper, we study these vision architectures with respect to the open-loop to closed-loop causality gap, i.e., offline training followed by an online closed-loop deployment. This causality gap typically emerges in robotics applications such as autonomous driving, where a network is trained to imitate the control commands of a human. In this setting, two situations arise: 1) Closed-loop testing in-distribution, where the test environment shares properties with those of offline training data. 2) Closed-loop testing under distribution shifts and out-of-distribution. Contrary to recently reported results, we show that under proper training guidelines, all vision models perform indistinguishably well on in-distribution deployment, resolving the causality gap. In situation 2, We observe that the causality gap disrupts performance regardless of the choice of the model architecture. Our results imply that the causality gap can be solved in situation one with our proposed training guideline with any modern network architecture, whereas achieving out-of-distribution generalization (situation two) requires further investigations, for instance, on data diversity rather than the model architecture.