 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain-Specific Deblurring via Disentangled Representations
Mar 05, 2019
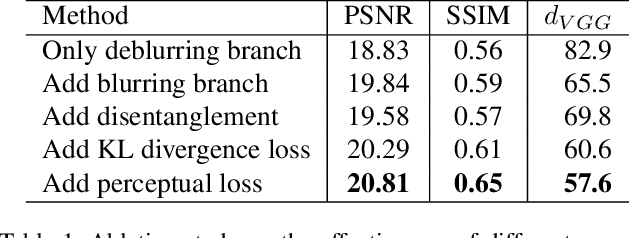
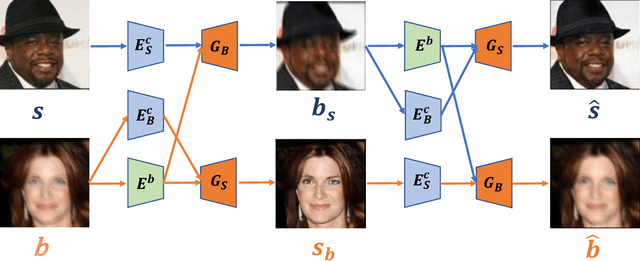
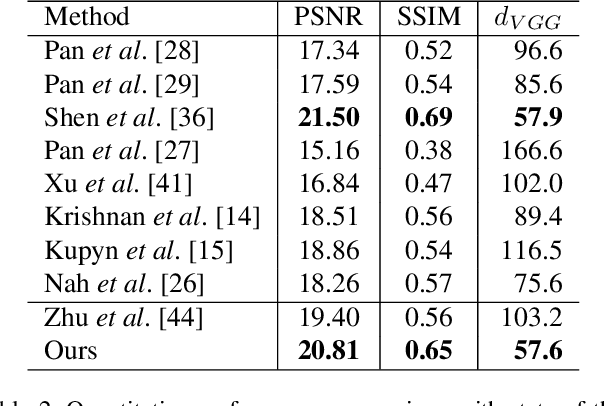
Image deblurring aims to restore the latent sharp images from the corresponding blurred ones. In this paper, we present an unsupervised method for domain-specific single-image deblurring based on disentangled representations. The disentanglement is achieved by splitting the content and blur features in a blurred image using content encoders and blur encoders. We enforce a KL divergence loss to regularize the distribution range of extracted blur attributes such that little content information is contained. Meanwhile, to handle the unpaired training data, a blurring branch and the cycle-consistency loss are added to guarantee that the content structures of the deblurred results match the original images. We also add an adversarial loss on deblurred results to generate visually realistic images and a perceptual loss to further mitigate the artifacts. We perform extensive experiments on the tasks of face and text deblurring using both synthetic datasets and real images, and achieve improved results compared to recent state-of-the-art deblurring methods.
On measuring the iconicity of a face
Mar 04, 2019

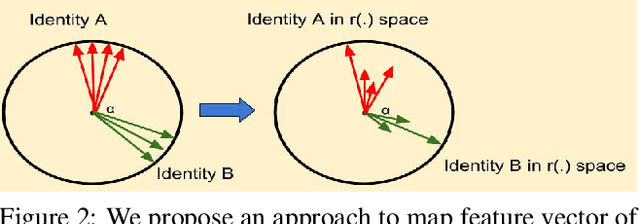
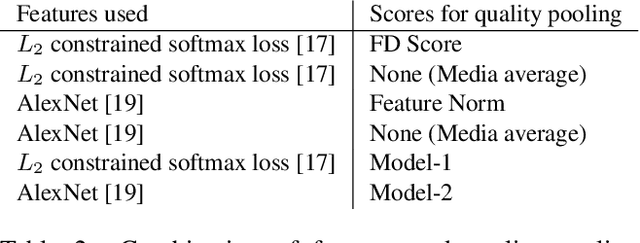
For a given identity in a face dataset, there are certain iconic images which are more representative of the subject than others. In this paper, we explore the problem of computing the iconicity of a face. The premise of the proposed approach is as follows: For an identity containing a mixture of iconic and non iconic images, if a given face cannot be successfully matched with any other face of the same identity, then the iconicity of the face image is low. Using this information, we train a Siamese Multi-Layer Perceptron network, such that each of its twins predict iconicity scores of the image feature pair, fed in as input. We observe the variation of the obtained scores with respect to covariates such as blur, yaw, pitch, roll and occlusion to demonstrate that they effectively predict the quality of the image and compare it with other existing metrics. Furthermore, we use these scores to weight features for template-based face verification and compare it with media averaging of features.
Normalized Wasserstein Distance for Mixture Distributions with Applications in Adversarial Learning and Domain Adaptation
Feb 01, 2019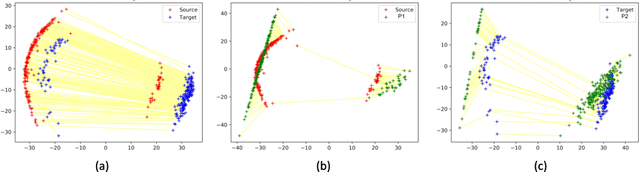
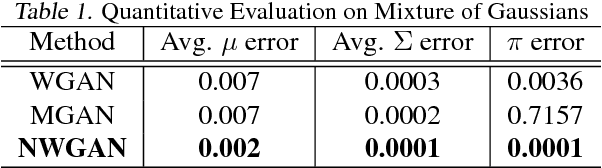
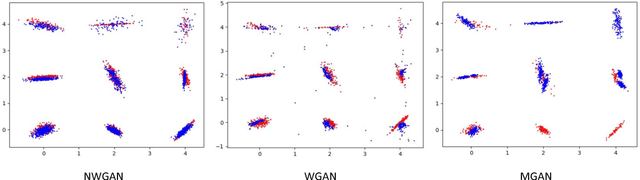
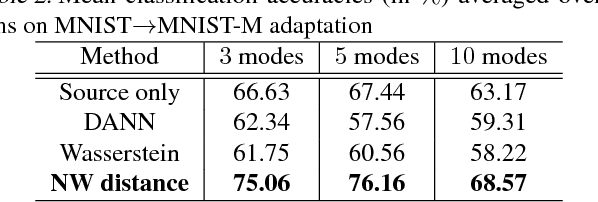
Understanding proper distance measures between distributions is at the core of several learning tasks such as generative models, domain adaptation, clustering, etc. In this work, we focus on {\it mixture distributions} that arise naturally in several application domains where the data contains different sub-populations. For mixture distributions, established distance measures such as the Wasserstein distance do not take into account imbalanced mixture proportions. Thus, even if two mixture distributions have identical mixture components but different mixture proportions, the Wasserstein distance between them will be large. This often leads to undesired results in distance-based learning methods for mixture distributions. In this paper, we resolve this issue by introducing {\it Normalized Wasserstein} distance. The key idea is to introduce mixture proportions as optimization variables, effectively normalizing mixture proportions in the Wasserstein formulation. Using the proposed normalized Wasserstein distance, instead of the vanilla one, leads to significant gains working with mixture distributions with imbalanced mixture proportions. We demonstrate effectiveness of the proposed distance in GANs, domain adaptation, adversarial clustering and hypothesis testing over mixture of Gaussians, MNIST, CIFAR-10, CelebA and VISDA datasets.
An Automatic System for Unconstrained Video-Based Face Recognition
Dec 10, 2018

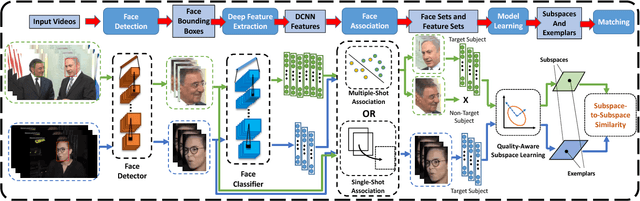

Although deep learning approaches have achieved performance surpassing humans for still image-based face recognition, unconstrained video-based face recognition is still a challenging task due to large volume of data to be processed and intra/inter-video variations on pose, illumination, occlusion, scene, blur, video quality, etc. In this work, we consider challenging scenarios for unconstrained video-based face recognition from multiple-shot videos and surveillance videos with low-quality frames. To handle these problems, we propose a robust and efficient system for unconstrained video-based face recognition, which is composed of face/fiducial detection, face association, and face recognition. First, we use multi-scale single-shot face detectors to efficiently localize faces in videos. The detected faces are then grouped respectively through carefully designed face association methods, especially for multi-shot videos. Finally, the faces are recognized by the proposed face matcher based on an unsupervised subspace learning approach and a subspace-to-subspace similarity metric. Extensive experiments on challenging video datasets, such as Multiple Biometric Grand Challenge (MBGC), Face and Ocular Challenge Series (FOCS), JANUS Challenge Set 6 (CS6) for low-quality surveillance videos and IARPA JANUS Benchmark B (IJB-B) for multiple-shot videos, demonstrate that the proposed system can accurately detect and associate faces from unconstrained videos and effectively learn robust and discriminative features for recognition.
Deep Regionlets: Blended Representation and Deep Learning for Generic Object Detection
Nov 28, 2018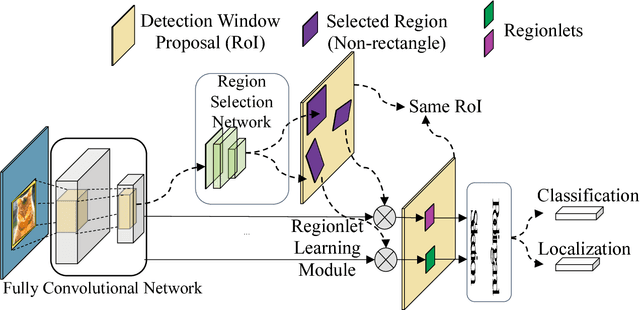
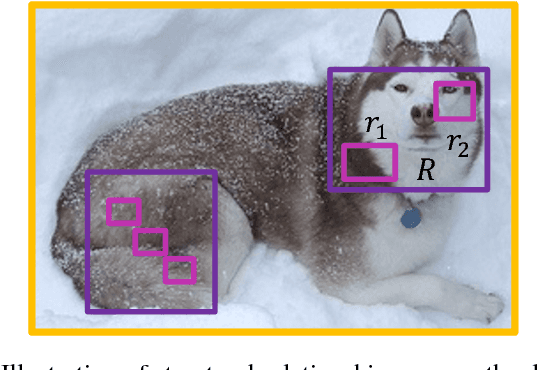

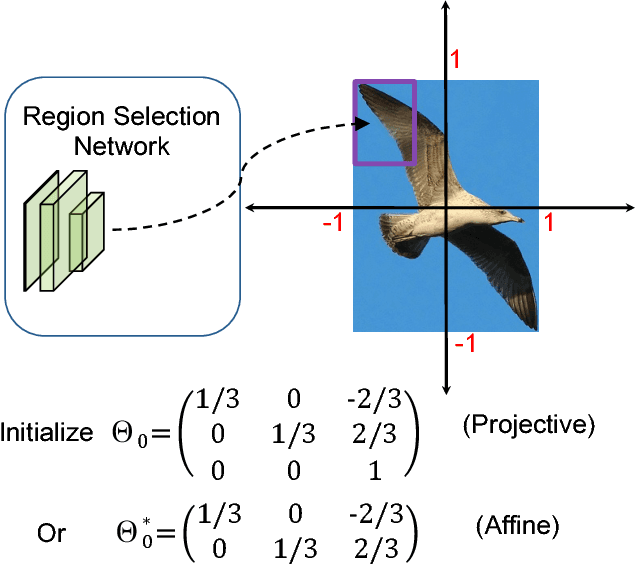
In this paper, we propose a novel object detection algorithm named "Deep Regionlets" by integrating deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the advantages of regionlets on modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions from which features can be learned from. The regionlet learning module focuses on local feature selection and transformation to alleviate the effects of appearance variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We present the results of ablation studies and extensive experiments on PASCAL VOC and Microsoft COCO datasets. The proposed algorithm outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
A Proposal-Based Solution to Spatio-Temporal Action Detection in Untrimmed Videos
Nov 23, 2018


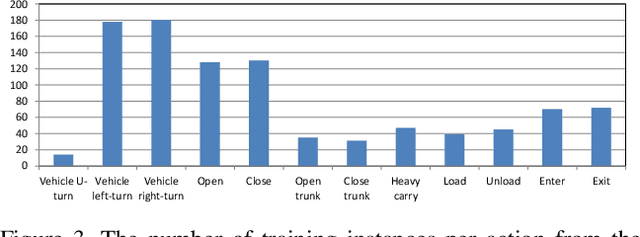
Existing approaches for spatio-temporal action detection in videos are limited by the spatial extent and temporal duration of the actions. In this paper, we present a modular system for spatio-temporal action detection in untrimmed security videos. We propose a two stage approach. The first stage generates dense spatio-temporal proposals using hierarchical clustering and temporal jittering techniques on frame-wise object detections. The second stage is a Temporal Refinement I3D (TRI-3D) network that performs action classification and temporal refinement on the generated proposals. The object detection-based proposal generation step helps in detecting actions occurring in a small spatial region of a video frame, while temporal jittering and refinement helps in detecting actions of variable lengths. Experimental results on the spatio-temporal action detection dataset - DIVA - show the effectiveness of our system. For comparison, the performance of our system is also evaluated on the THUMOS14 temporal action detection dataset.
Recognizing Disguised Faces in the Wild
Nov 21, 2018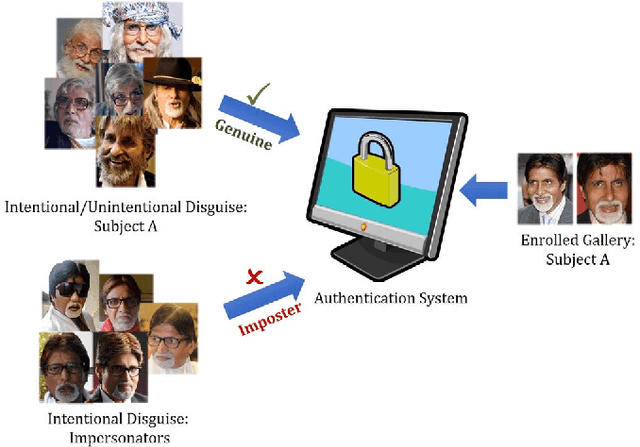

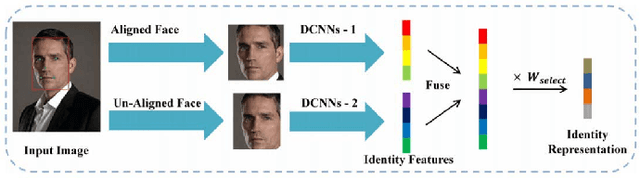
Research in face recognition has seen tremendous growth over the past couple of decades. Beginning from algorithms capable of performing recognition in constrained environments, the current face recognition systems achieve very high accuracies on large-scale unconstrained face datasets. While upcoming algorithms continue to achieve improved performance, a majority of the face recognition systems are susceptible to failure under disguise variations, one of the most challenging covariate of face recognition. Most of the existing disguise datasets contain images with limited variations, often captured in controlled settings. This does not simulate a real world scenario, where both intentional and unintentional unconstrained disguises are encountered by a face recognition system. In this paper, a novel Disguised Faces in the Wild (DFW) dataset is proposed which contains over 11000 images of 1000 identities with different types of disguise accessories. The dataset is collected from the Internet, resulting in unconstrained face images similar to real world settings. This is the first-of-a-kind dataset with the availability of impersonator and genuine obfuscated face images for each subject. The proposed dataset has been analyzed in terms of three levels of difficulty: (i) easy, (ii) medium, and (iii) hard in order to showcase the challenging nature of the problem. It is our view that the research community can greatly benefit from the DFW dataset in terms of developing algorithms robust to such adversaries. The proposed dataset was released as part of the First International Workshop and Competition on Disguised Faces in the Wild at CVPR, 2018. This paper presents the DFW dataset in detail, including the evaluation protocols, baseline results, performance analysis of the submissions received as part of the competition, and three levels of difficulties of the DFW challenge dataset.
Learning without Memorizing
Nov 20, 2018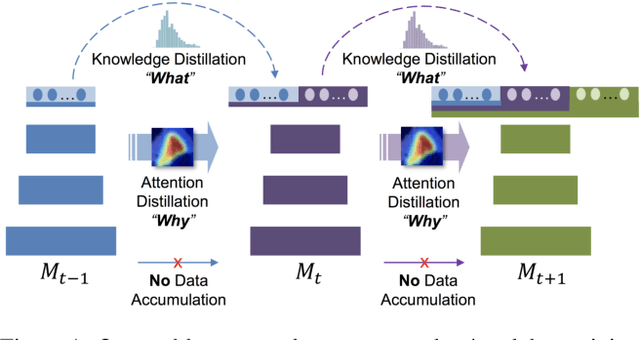


Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called "Learning without Memorizing (LwM)", to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers' attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.
Entropic GANs meet VAEs: A Statistical Approach to Compute Sample Likelihoods in GANs
Oct 09, 2018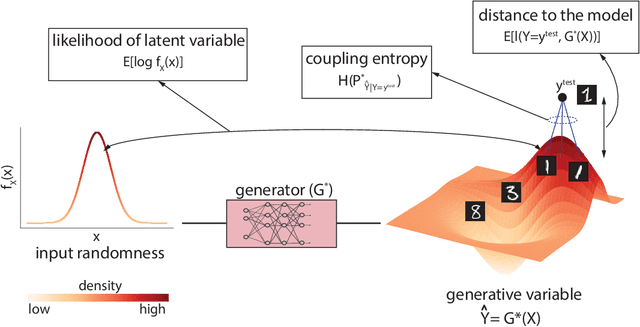


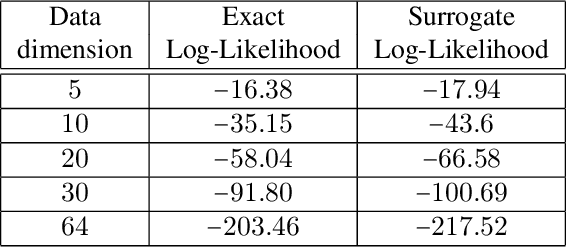
Building on the success of deep learning, two modern approaches to learn a probability model of the observed data are Generative Adversarial Networks (GANs) and Variational AutoEncoders (VAEs). VAEs consider an explicit probability model for the data and compute a generative distribution by maximizing a variational lower-bound on the log-likelihood function. GANs, however, compute a generative model by minimizing a distance between observed and generated probability distributions without considering an explicit model for the observed data. The lack of having explicit probability models in GANs prohibits computation of sample likelihoods in their frameworks and limits their use in statistical inference problems. In this work, we show that an optimal transport GAN with the entropy regularization can be viewed as a generative model that maximizes a lower-bound on average sample likelihoods, an approach that VAEs are based on. In particular, our proof constructs an explicit probability model for GANs that can be used to compute likelihood statistics within GAN's framework. Our numerical results on several datasets demonstrate consistent trends with the proposed theory.
From BoW to CNN: Two Decades of Texture Representation for Texture Classification
Oct 03, 2018

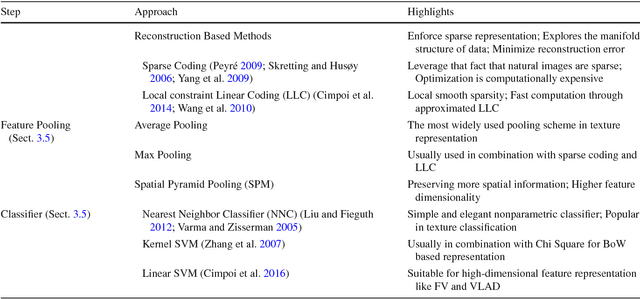
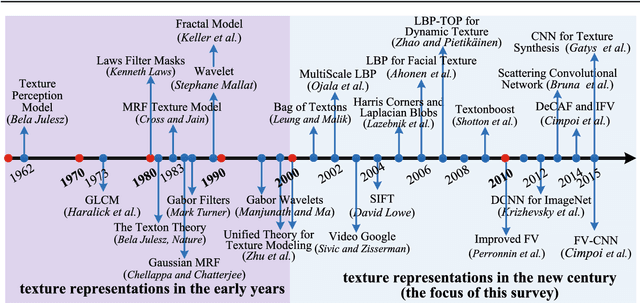
Texture is a fundamental characteristic of many types of images, and texture representation is one of the essential and challenging problems in computer vision and pattern recognition which has attracted extensive research attention. Since 2000, texture representations based on Bag of Words (BoW) and on Convolutional Neural Networks (CNNs) have been extensively studied with impressive performance. Given this period of remarkable evolution, this paper aims to present a comprehensive survey of advances in texture representation over the last two decades. More than 200 major publications are cited in this survey covering different aspects of the research, which includes (i) problem description; (ii) recent advances in the broad categories of BoW-based, CNN-based and attribute-based methods; and (iii) evaluation issues, specifically benchmark datasets and state of the art results. In retrospect of what has been achieved so far, the survey discusses open challenges and directions for future research.