 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivizing Truthfulness and Collaborative Fairness in Bayesian Learning
May 12, 2026Collaborative machine learning involves training high-quality models using datasets from a number of sources. To incentivize sources to share data, existing data valuation methods fairly reward each source based on its data submitted as is. However, as these methods do not verify nor incentivize data truthfulness, the sources can manipulate their data (e.g., by submitting duplicated or noisy data) to artificially increase their valuations and rewards or prevent others from benefiting. This paper presents the first mechanism that provably ensures (F) collaborative fairness and incentivizes (T) truthfulness at equilibrium for Bayesian models. Our mechanism combines semivalues (e.g., Shapley value), which ensure fairness, and a truthful data valuation function (DVF) based on a validation set that is unknown to the sources. As semivalues are influenced by others' data, we introduce an additional condition to prove that a source can maximize its expected data values in coalitions and semivalues by submitting a dataset that captures its true knowledge. Additionally, we discuss the implications and suitable relaxations of (F) and (T) when the mediator has a limited budget for rewards or lacks a validation set. Our theoretical findings are validated on synthetic and real-world datasets.
Is Data Shapley Not Better than Random in Data Selection? Ask NASH
May 11, 2026Data selection studies the problem of identifying high-quality subsets of training data. While some existing works have considered selecting the subset of data with top-$m$ Data Shapley or other semivalues as they account for the interaction among every subset of data, other works argue that Data Shapley can sometimes perform ineffectively in practice and select subsets that are no better than random. This raises the questions: (I) Are there certain "Shapley-informative" settings where Data Shapley consistently works well? (II) Can we strategically utilize these settings to select high-quality subsets consistently and efficiently? In this paper, we propose a novel data selection framework, NASH (Non-linear Aggregation of SHapley-informative components), which (I) decomposes the target utility function (e.g., validation accuracy) into simpler, Shapley-informative component functions, and selects data by optimizing an objective that (II) aggregates these components non-linearly. We demonstrate that NASH substantially boosts the effectiveness of Shapley/semivalue-based data selection with minimal additional runtime cost.
Uncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
WaterDrum: Watermarking for Data-centric Unlearning Metric
May 08, 2025Large language model (LLM) unlearning is critical in real-world applications where it is necessary to efficiently remove the influence of private, copyrighted, or harmful data from some users. However, existing utility-centric unlearning metrics (based on model utility) may fail to accurately evaluate the extent of unlearning in realistic settings such as when (a) the forget and retain set have semantically similar content, (b) retraining the model from scratch on the retain set is impractical, and/or (c) the model owner can improve the unlearning metric without directly performing unlearning on the LLM. This paper presents the first data-centric unlearning metric for LLMs called WaterDrum that exploits robust text watermarking for overcoming these limitations. We also introduce new benchmark datasets for LLM unlearning that contain varying levels of similar data points and can be used to rigorously evaluate unlearning algorithms using WaterDrum. Our code is available at https://github.com/lululu008/WaterDrum and our new benchmark datasets are released at https://huggingface.co/datasets/Glow-AI/WaterDrum-Ax.
DUPRE: Data Utility Prediction for Efficient Data Valuation
Feb 22, 2025Data valuation is increasingly used in machine learning (ML) to decide the fair compensation for data owners and identify valuable or harmful data for improving ML models. Cooperative game theory-based data valuation, such as Data Shapley, requires evaluating the data utility (e.g., validation accuracy) and retraining the ML model for multiple data subsets. While most existing works on efficient estimation of the Shapley values have focused on reducing the number of subsets to evaluate, our framework, \texttt{DUPRE}, takes an alternative yet complementary approach that reduces the cost per subset evaluation by predicting data utilities instead of evaluating them by model retraining. Specifically, given the evaluated data utilities of some data subsets, \texttt{DUPRE} fits a \emph{Gaussian process} (GP) regression model to predict the utility of every other data subset. Our key contribution lies in the design of our GP kernel based on the sliced Wasserstein distance between empirical data distributions. In particular, we show that the kernel is valid and positive semi-definite, encodes prior knowledge of similarities between different data subsets, and can be efficiently computed. We empirically verify that \texttt{DUPRE} introduces low prediction error and speeds up data valuation for various ML models, datasets, and utility functions.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Incentives in Private Collaborative Machine Learning
Apr 02, 2024Collaborative machine learning involves training models on data from multiple parties but must incentivize their participation. Existing data valuation methods fairly value and reward each party based on shared data or model parameters but neglect the privacy risks involved. To address this, we introduce differential privacy (DP) as an incentive. Each party can select its required DP guarantee and perturb its sufficient statistic (SS) accordingly. The mediator values the perturbed SS by the Bayesian surprise it elicits about the model parameters. As our valuation function enforces a privacy-valuation trade-off, parties are deterred from selecting excessive DP guarantees that reduce the utility of the grand coalition's model. Finally, the mediator rewards each party with different posterior samples of the model parameters. Such rewards still satisfy existing incentives like fairness but additionally preserve DP and a high similarity to the grand coalition's posterior. We empirically demonstrate the effectiveness and practicality of our approach on synthetic and real-world datasets.
DeRDaVa: Deletion-Robust Data Valuation for Machine Learning
Dec 18, 2023



Data valuation is concerned with determining a fair valuation of data from data sources to compensate them or to identify training examples that are the most or least useful for predictions. With the rising interest in personal data ownership and data protection regulations, model owners will likely have to fulfil more data deletion requests. This raises issues that have not been addressed by existing works: Are the data valuation scores still fair with deletions? Must the scores be expensively recomputed? The answer is no. To avoid recomputations, we propose using our data valuation framework DeRDaVa upfront for valuing each data source's contribution to preserving robust model performance after anticipated data deletions. DeRDaVa can be efficiently approximated and will assign higher values to data that are more useful or less likely to be deleted. We further generalize DeRDaVa to Risk-DeRDaVa to cater to risk-averse/seeking model owners who are concerned with the worst/best-cases model utility. We also empirically demonstrate the practicality of our solutions.
Probably Approximate Shapley Fairness with Applications in Machine Learning
Dec 01, 2022



The Shapley value (SV) is adopted in various scenarios in machine learning (ML), including data valuation, agent valuation, and feature attribution, as it satisfies their fairness requirements. However, as exact SVs are infeasible to compute in practice, SV estimates are approximated instead. This approximation step raises an important question: do the SV estimates preserve the fairness guarantees of exact SVs? We observe that the fairness guarantees of exact SVs are too restrictive for SV estimates. Thus, we generalise Shapley fairness to probably approximate Shapley fairness and propose fidelity score, a metric to measure the variation of SV estimates, that determines how probable the fairness guarantees hold. Our last theoretical contribution is a novel greedy active estimation (GAE) algorithm that will maximise the lowest fidelity score and achieve a better fairness guarantee than the de facto Monte-Carlo estimation. We empirically verify GAE outperforms several existing methods in guaranteeing fairness while remaining competitive in estimation accuracy in various ML scenarios using real-world datasets.
Collaborative Machine Learning with Incentive-Aware Model Rewards
Oct 24, 2020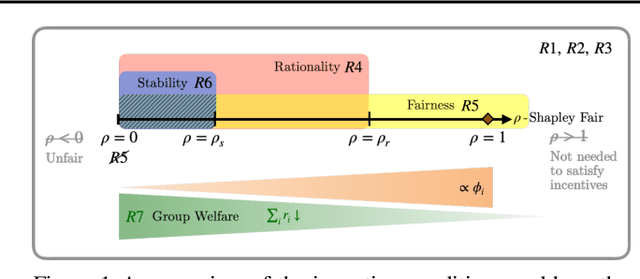
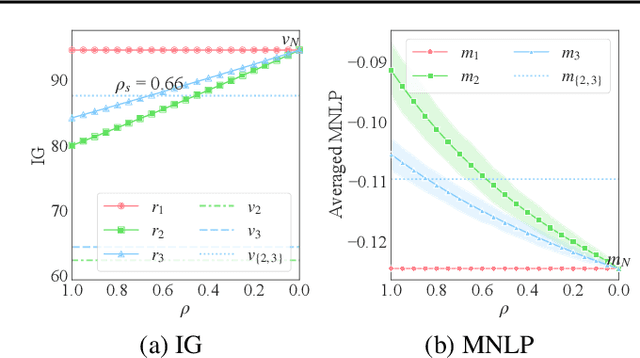
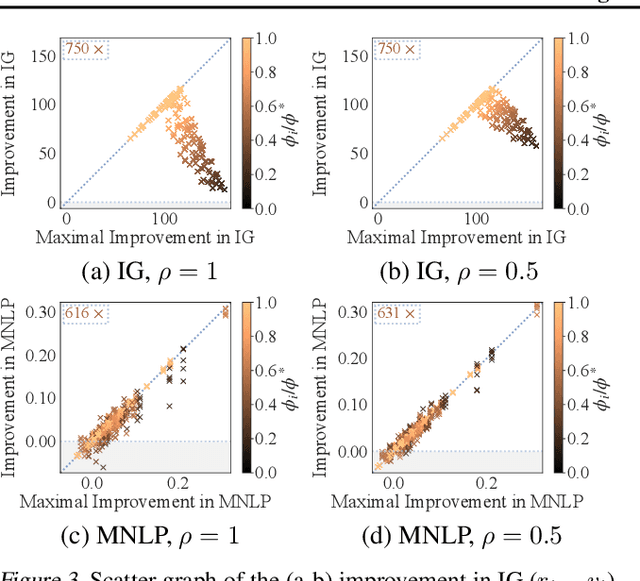

Collaborative machine learning (ML) is an appealing paradigm to build high-quality ML models by training on the aggregated data from many parties. However, these parties are only willing to share their data when given enough incentives, such as a guaranteed fair reward based on their contributions. This motivates the need for measuring a party's contribution and designing an incentive-aware reward scheme accordingly. This paper proposes to value a party's reward based on Shapley value and information gain on model parameters given its data. Subsequently, we give each party a model as a reward. To formally incentivize the collaboration, we define some desirable properties (e.g., fairness and stability) which are inspired by cooperative game theory but adapted for our model reward that is uniquely freely replicable. Then, we propose a novel model reward scheme to satisfy fairness and trade off between the desirable properties via an adjustable parameter. The value of each party's model reward determined by our scheme is attained by injecting Gaussian noise to the aggregated training data with an optimized noise variance. We empirically demonstrate interesting properties of our scheme and evaluate its performance using synthetic and real-world datasets.