 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Scaling Laws for Large Language Models via Inverse Problems
Sep 09, 2025Large Language Models (LLMs) are large-scale pretrained models that have achieved remarkable success across diverse domains. These successes have been driven by unprecedented complexity and scale in both data and computations. However, due to the high costs of training such models, brute-force trial-and-error approaches to improve LLMs are not feasible. Inspired by the success of inverse problems in uncovering fundamental scientific laws, this position paper advocates that inverse problems can also efficiently uncover scaling laws that guide the building of LLMs to achieve the desirable performance with significantly better cost-effectiveness.
Group-robust Sample Reweighting for Subpopulation Shifts via Influence Functions
Mar 10, 2025



Machine learning models often have uneven performance among subpopulations (a.k.a., groups) in the data distributions. This poses a significant challenge for the models to generalize when the proportions of the groups shift during deployment. To improve robustness to such shifts, existing approaches have developed strategies that train models or perform hyperparameter tuning using the group-labeled data to minimize the worst-case loss over groups. However, a non-trivial amount of high-quality labels is often required to obtain noticeable improvements. Given the costliness of the labels, we propose to adopt a different paradigm to enhance group label efficiency: utilizing the group-labeled data as a target set to optimize the weights of other group-unlabeled data. We introduce Group-robust Sample Reweighting (GSR), a two-stage approach that first learns the representations from group-unlabeled data, and then tinkers the model by iteratively retraining its last layer on the reweighted data using influence functions. Our GSR is theoretically sound, practically lightweight, and effective in improving the robustness to subpopulation shifts. In particular, GSR outperforms the previous state-of-the-art approaches that require the same amount or even more group labels.
TETRIS: Optimal Draft Token Selection for Batch Speculative Decoding
Feb 21, 2025We propose TETRIS, a novel method that optimizes the total throughput of batch speculative decoding in multi-request settings. Unlike existing methods that optimize for a single request or a group of requests as a whole, TETRIS actively selects the most promising draft tokens (for every request in a batch) to be accepted when verified in parallel, resulting in fewer rejected tokens and hence less wasted computing resources. Such an effective resource utilization to achieve fast inference in large language models (LLMs) is especially important to service providers with limited inference capacity. Compared to baseline speculative decoding, TETRIS yields a consistently higher acceptance rate and more effective utilization of the limited inference capacity. We show theoretically and empirically that TETRIS outperforms baseline speculative decoding and existing methods that dynamically select draft tokens, leading to a more efficient batch inference in LLMs.
Paid with Models: Optimal Contract Design for Collaborative Machine Learning
Dec 15, 2024



Collaborative machine learning (CML) provides a promising paradigm for democratizing advanced technologies by enabling cost-sharing among participants. However, the potential for rent-seeking behaviors among parties can undermine such collaborations. Contract theory presents a viable solution by rewarding participants with models of varying accuracy based on their contributions. However, unlike monetary compensation, using models as rewards introduces unique challenges, particularly due to the stochastic nature of these rewards when contribution costs are privately held information. This paper formalizes the optimal contracting problem within CML and proposes a transformation that simplifies the non-convex optimization problem into one that can be solved through convex optimization algorithms. We conduct a detailed analysis of the properties that an optimal contract must satisfy when models serve as the rewards, and we explore the potential benefits and welfare implications of these contract-driven CML schemes through numerical experiments.
Data-Centric AI in the Age of Large Language Models
Jun 20, 2024
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Prompt Optimization with EASE? Efficient Ordering-aware Automated Selection of Exemplars
May 25, 2024



Large language models (LLMs) have shown impressive capabilities in real-world applications. The capability of in-context learning (ICL) allows us to adapt an LLM to downstream tasks by including input-label exemplars in the prompt without model fine-tuning. However, the quality of these exemplars in the prompt greatly impacts performance, highlighting the need for an effective automated exemplar selection method. Recent studies have explored retrieval-based approaches to select exemplars tailored to individual test queries, which can be undesirable due to extra test-time computation and an increased risk of data exposure. Moreover, existing methods fail to adequately account for the impact of exemplar ordering on the performance. On the other hand, the impact of the instruction, another essential component in the prompt given to the LLM, is often overlooked in existing exemplar selection methods. To address these challenges, we propose a novel method named EASE, which leverages the hidden embedding from a pre-trained language model to represent ordered sets of exemplars and uses a neural bandit algorithm to optimize the sets of exemplars while accounting for exemplar ordering. Our EASE can efficiently find an ordered set of exemplars that performs well for all test queries from a given task, thereby eliminating test-time computation. Importantly, EASE can be readily extended to jointly optimize both the exemplars and the instruction. Through extensive empirical evaluations (including novel tasks), we demonstrate the superiority of EASE over existing methods, and reveal practical insights about the impact of exemplar selection on ICL, which may be of independent interest. Our code is available at https://github.com/ZhaoxuanWu/EASE-Prompt-Optimization.
Localized Zeroth-Order Prompt Optimization
Mar 05, 2024



The efficacy of large language models (LLMs) in understanding and generating natural language has aroused a wide interest in developing prompt-based methods to harness the power of black-box LLMs. Existing methodologies usually prioritize a global optimization for finding the global optimum, which however will perform poorly in certain tasks. This thus motivates us to re-think the necessity of finding a global optimum in prompt optimization. To answer this, we conduct a thorough empirical study on prompt optimization and draw two major insights. Contrasting with the rarity of global optimum, local optima are usually prevalent and well-performed, which can be more worthwhile for efficient prompt optimization (Insight I). The choice of the input domain, covering both the generation and the representation of prompts, affects the identification of well-performing local optima (Insight II). Inspired by these insights, we propose a novel algorithm, namely localized zeroth-order prompt optimization (ZOPO), which incorporates a Neural Tangent Kernel-based derived Gaussian process into standard zeroth-order optimization for an efficient search of well-performing local optima in prompt optimization. Remarkably, ZOPO outperforms existing baselines in terms of both the optimization performance and the query efficiency, which we demonstrate through extensive experiments.
Use Your INSTINCT: INSTruction optimization usIng Neural bandits Coupled with Transformers
Oct 02, 2023Large language models (LLMs) have shown remarkable instruction-following capabilities and achieved impressive performances in various applications. However, the performances of LLMs depend heavily on the instructions given to them, which are typically manually tuned with substantial human efforts. Recent work has used the query-efficient Bayesian optimization (BO) algorithm to automatically optimize the instructions given to black-box LLMs. However, BO usually falls short when optimizing highly sophisticated (e.g., high-dimensional) objective functions, such as the functions mapping an instruction to the performance of an LLM. This is mainly due to the limited expressive power of the Gaussian process (GP) model which is used by BO as a surrogate to model the objective function. Meanwhile, it has been repeatedly shown that neural networks (NNs), especially pre-trained transformers, possess strong expressive power and can model highly complex functions. So, we adopt a neural bandit algorithm which replaces the GP in BO by an NN surrogate to optimize instructions for black-box LLMs. More importantly, the neural bandit algorithm allows us to naturally couple the NN surrogate with the hidden representation learned by a pre-trained transformer (i.e., an open-source LLM), which significantly boosts its performance. These motivate us to propose our INSTruction optimization usIng Neural bandits Coupled with Transformers} (INSTINCT) algorithm. We perform instruction optimization for ChatGPT and use extensive experiments to show that our INSTINCT consistently outperforms the existing methods in different tasks, such as in various instruction induction tasks and the task of improving the zero-shot chain-of-thought instruction.
Unifying and Boosting Gradient-Based Training-Free Neural Architecture Search
Jan 24, 2022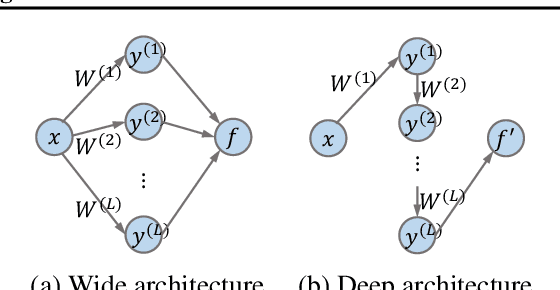
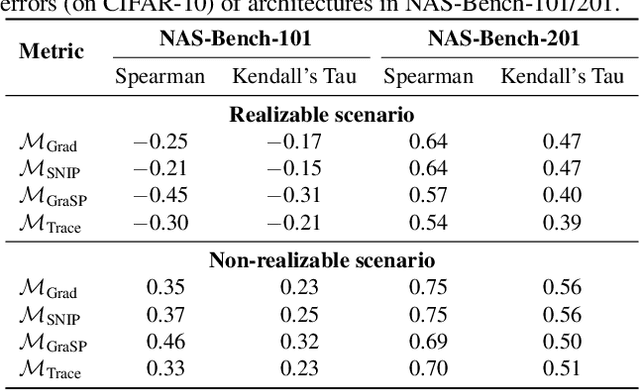
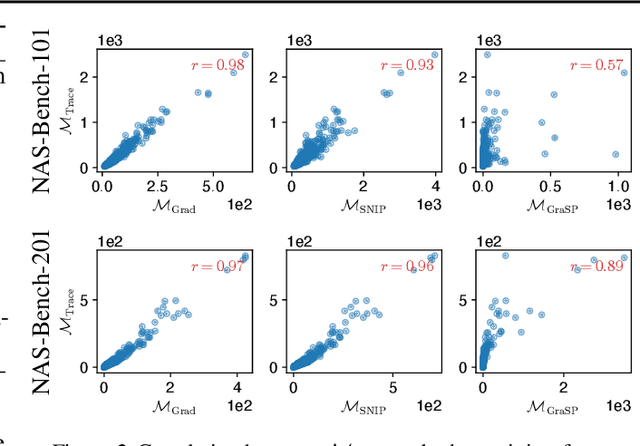
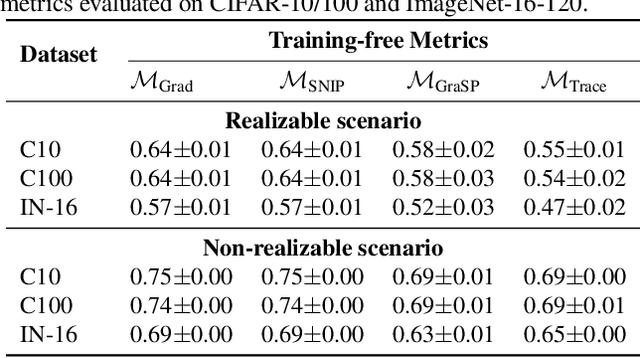
Neural architecture search (NAS) has gained immense popularity owing to its ability to automate neural architecture design. A number of training-free metrics are recently proposed to realize NAS without training, hence making NAS more scalable. Despite their competitive empirical performances, a unified theoretical understanding of these training-free metrics is lacking. As a consequence, (a) the relationships among these metrics are unclear, (b) there is no theoretical guarantee for their empirical performances and transferability, and (c) there may exist untapped potential in training-free NAS, which can be unveiled through a unified theoretical understanding. To this end, this paper presents a unified theoretical analysis of gradient-based training-free NAS, which allows us to (a) theoretically study their relationships, (b) theoretically guarantee their generalization performances and transferability, and (c) exploit our unified theoretical understanding to develop a novel framework named hybrid NAS (HNAS) which consistently boosts training-free NAS in a principled way. Interestingly, HNAS is able to enjoy the advantages of both training-free (i.e., superior search efficiency) and training-based (i.e., remarkable search effectiveness) NAS, which we have demonstrated through extensive experiments.
Trusted-Maximizers Entropy Search for Efficient Bayesian Optimization
Jul 30, 2021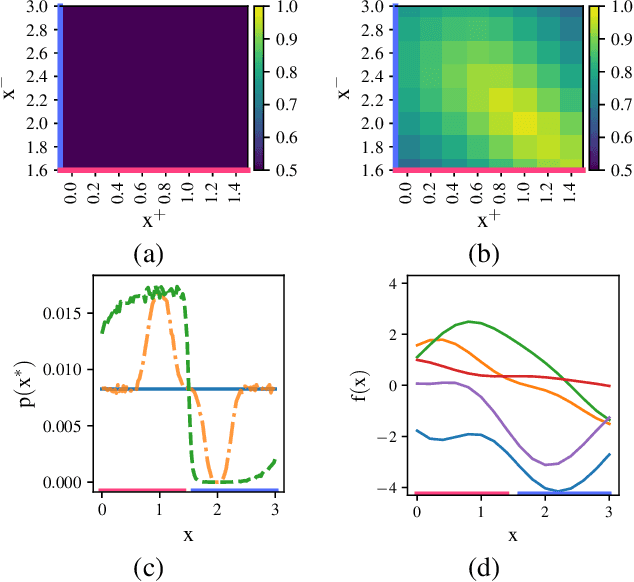
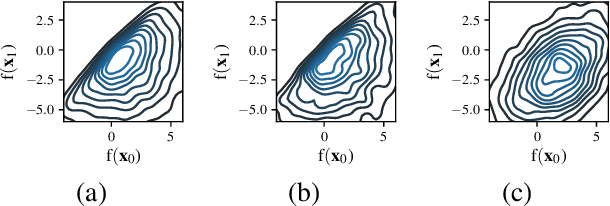
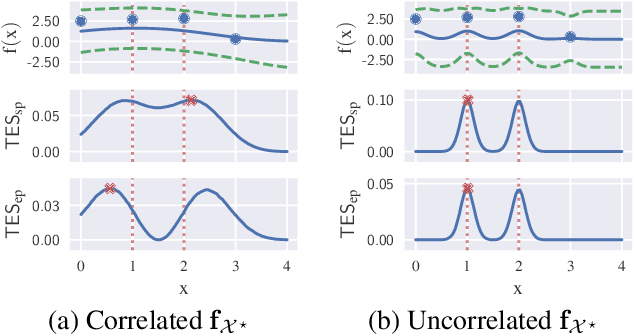
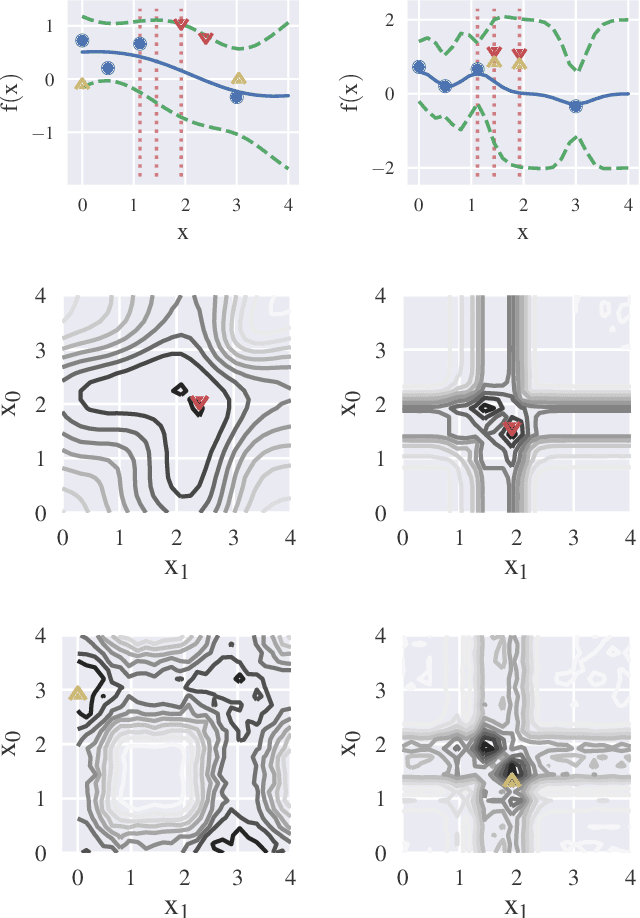
Information-based Bayesian optimization (BO) algorithms have achieved state-of-the-art performance in optimizing a black-box objective function. However, they usually require several approximations or simplifying assumptions (without clearly understanding their effects on the BO performance) and/or their generalization to batch BO is computationally unwieldy, especially with an increasing batch size. To alleviate these issues, this paper presents a novel trusted-maximizers entropy search (TES) acquisition function: It measures how much an input query contributes to the information gain on the maximizer over a finite set of trusted maximizers, i.e., inputs optimizing functions that are sampled from the Gaussian process posterior belief of the objective function. Evaluating TES requires either only a stochastic approximation with sampling or a deterministic approximation with expectation propagation, both of which are investigated and empirically evaluated using synthetic benchmark objective functions and real-world optimization problems, e.g., hyperparameter tuning of a convolutional neural network and synthesizing 'physically realizable' faces to fool a black-box face recognition system. Though TES can naturally be generalized to a batch variant with either approximation, the latter is amenable to be scaled to a much larger batch size in our experiments.