 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decision Transformer
Feb 11, 2022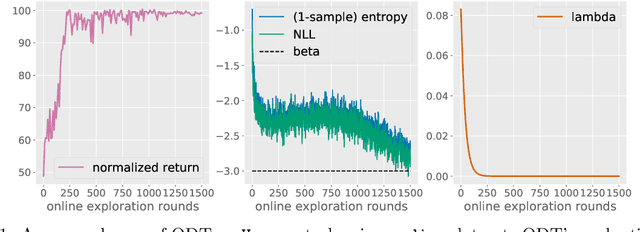
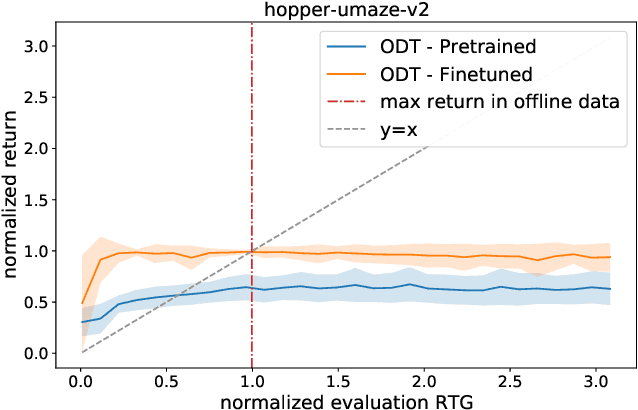
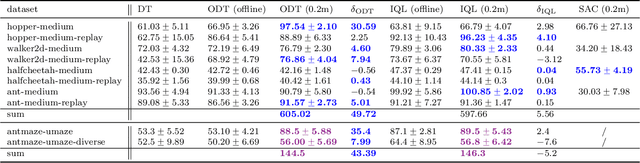
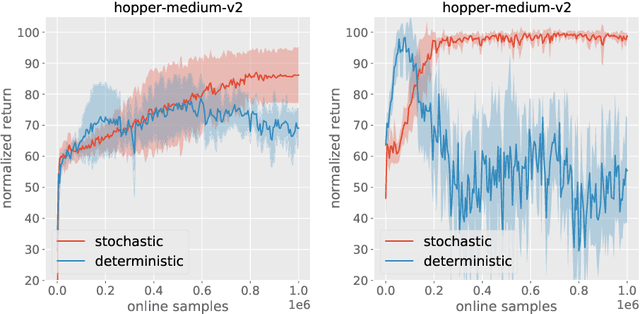
Recent work has shown that offline reinforcement learning (RL) can be formulated as a sequence modeling problem (Chen et al., 2021; Janner et al., 2021) and solved via approaches similar to large-scale language modeling. However, any practical instantiation of RL also involves an online component, where policies pretrained on passive offline datasets are finetuned via taskspecific interactions with the environment. We propose Online Decision Transformers (ODT), an RL algorithm based on sequence modeling that blends offline pretraining with online finetuning in a unified framework. Our framework uses sequence-level entropy regularizers in conjunction with autoregressive modeling objectives for sample-efficient exploration and finetuning. Empirically, we show that ODT is competitive with the state-of-the-art in absolute performance on the D4RL benchmark but shows much more significant gains during the finetuning procedure.
A Theorem of the Alternative for Personalized Federated Learning
Mar 02, 2021A widely recognized difficulty in federated learning arises from the statistical heterogeneity among clients: local datasets often come from different but not entirely unrelated distributions, and personalization is, therefore, necessary to achieve optimal results from each individual's perspective. In this paper, we show how the excess risks of personalized federated learning with a smooth, strongly convex loss depend on data heterogeneity from a minimax point of view. Our analysis reveals a surprising theorem of the alternative for personalized federated learning: there exists a threshold such that (a) if a certain measure of data heterogeneity is below this threshold, the FedAvg algorithm [McMahan et al., 2017] is minimax optimal; (b) when the measure of heterogeneity is above this threshold, then doing pure local training (i.e., clients solve empirical risk minimization problems on their local datasets without any communication) is minimax optimal. As an implication, our results show that the presumably difficult (infinite-dimensional) problem of adapting to client-wise heterogeneity can be reduced to a simple binary decision problem of choosing between the two baseline algorithms. Our analysis relies on a new notion of algorithmic stability that takes into account the nature of federated learning.
Federated $f$-Differential Privacy
Feb 22, 2021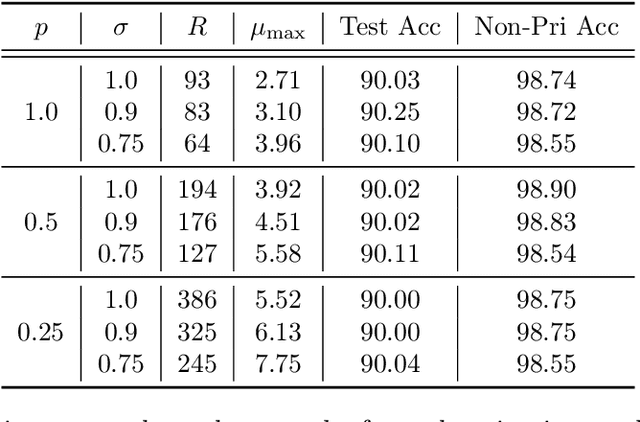
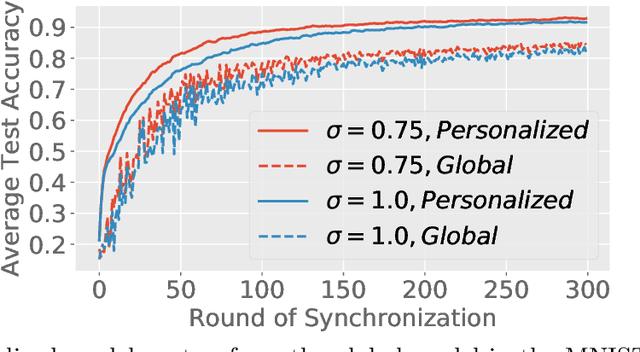
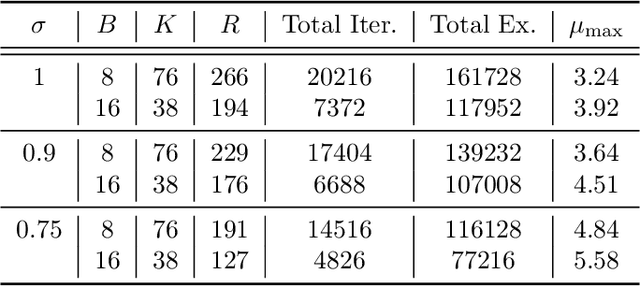
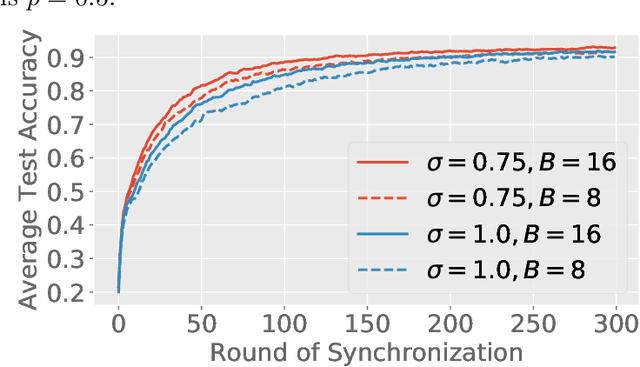
Federated learning (FL) is a training paradigm where the clients collaboratively learn models by repeatedly sharing information without compromising much on the privacy of their local sensitive data. In this paper, we introduce federated $f$-differential privacy, a new notion specifically tailored to the federated setting, based on the framework of Gaussian differential privacy. Federated $f$-differential privacy operates on record level: it provides the privacy guarantee on each individual record of one client's data against adversaries. We then propose a generic private federated learning framework {PriFedSync} that accommodates a large family of state-of-the-art FL algorithms, which provably achieves federated $f$-differential privacy. Finally, we empirically demonstrate the trade-off between privacy guarantee and prediction performance for models trained by {PriFedSync} in computer vision tasks.
Near-Optimal Confidence Sequences for Bounded Random Variables
Jun 09, 2020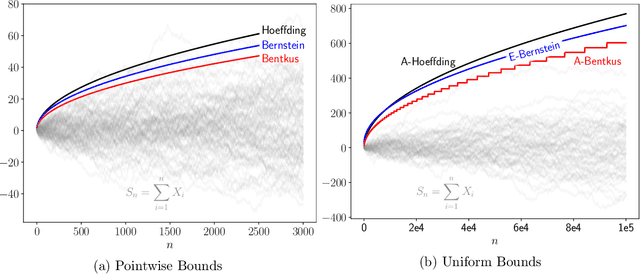
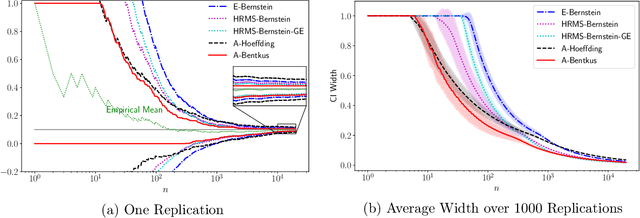
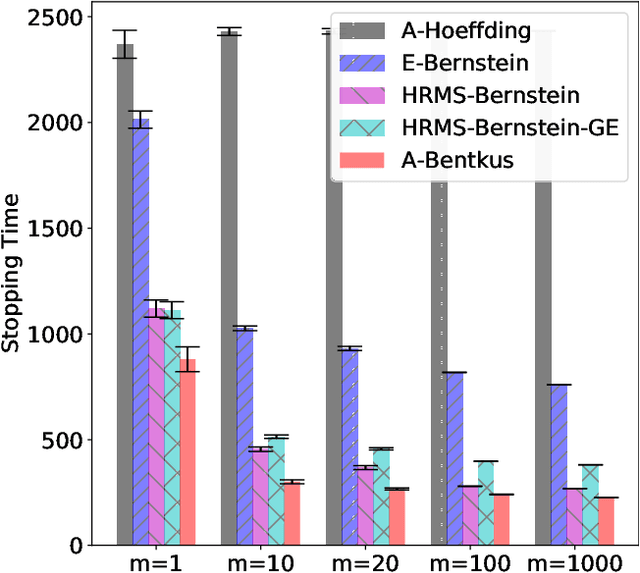
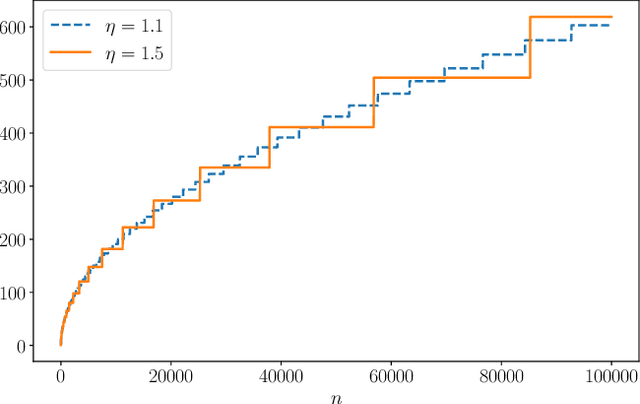
Many inference problems, such as sequential decision problems like A/B testing, adaptive sampling schemes like bandit selection, are often online in nature. The fundamental problem for online inference is to provide a sequence of confidence intervals that are valid uniformly over the growing-into-infinity sample sizes. To address this question, we provide a near-optimal confidence sequence for bounded random variables by utilizing Bentkus' concentration results. We show that it improves on the existing approaches that use the Cram{\'e}r-Chernoff technique such as the Hoeffding, Bernstein, and Bennett inequalities. The resulting confidence sequence is confirmed to be favorable in both synthetic coverage problems and an application to adaptive stopping algorithms.
Sharp Composition Bounds for Gaussian Differential Privacy via Edgeworth Expansion
Mar 25, 2020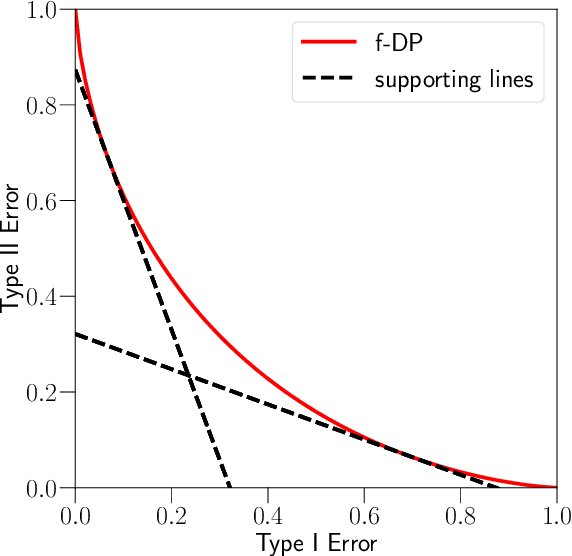
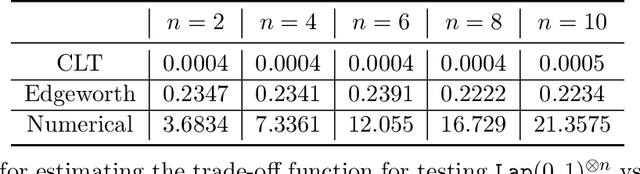
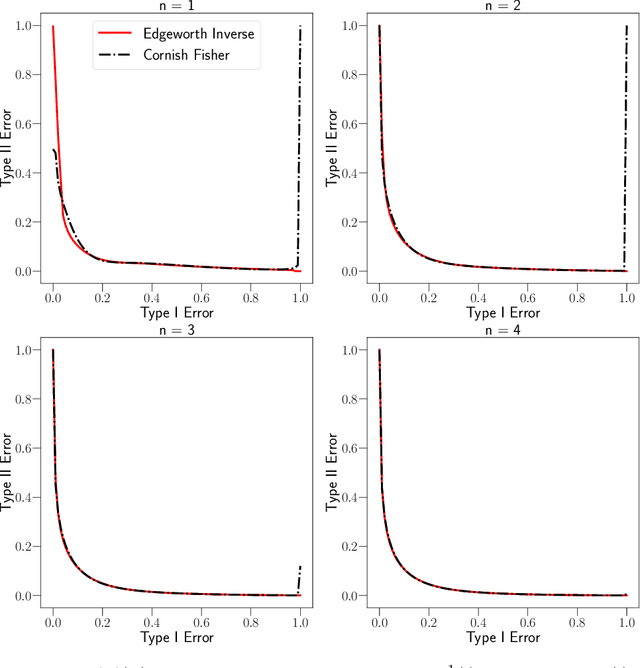
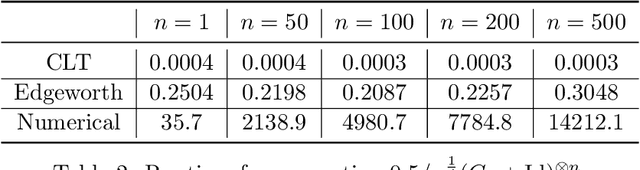
Datasets containing sensitive information are often sequentially analyzed by many algorithms. This raises a fundamental question in differential privacy regarding how the overall privacy bound degrades under composition. To address this question, we introduce a family of analytical and sharp privacy bounds under composition using the Edgeworth expansion in the framework of the recently proposed f-differential privacy. In contrast to the existing composition theorems using the central limit theorem, our new privacy bounds under composition gain improved tightness by leveraging the refined approximation accuracy of the Edgeworth expansion. Our approach is easy to implement and computationally efficient for any number of compositions. The superiority of these new bounds is confirmed by an asymptotic error analysis and an application to quantifying the overall privacy guarantees of noisy stochastic gradient descent used in training private deep neural networks.
ShadowSync: Performing Synchronization in the Background for Highly Scalable Distributed Training
Mar 07, 2020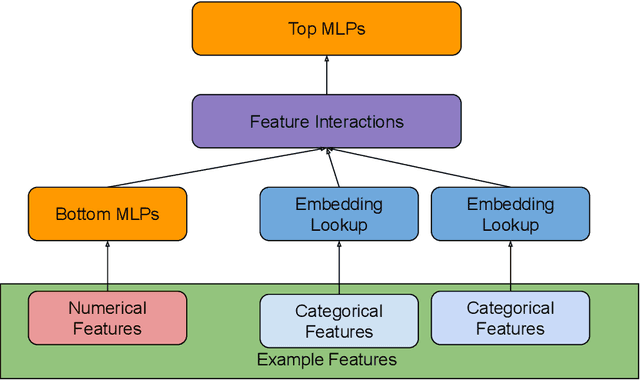
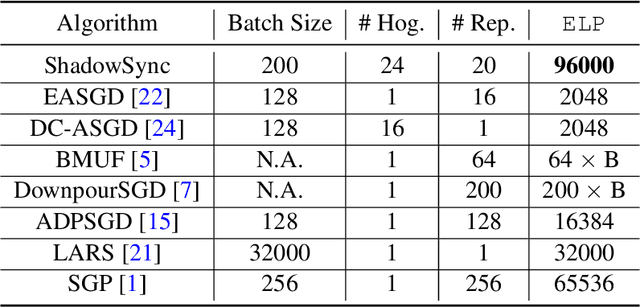
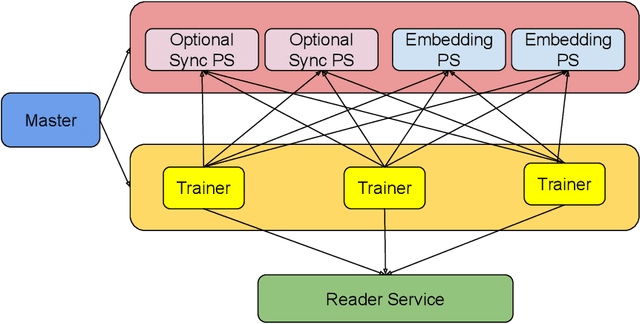
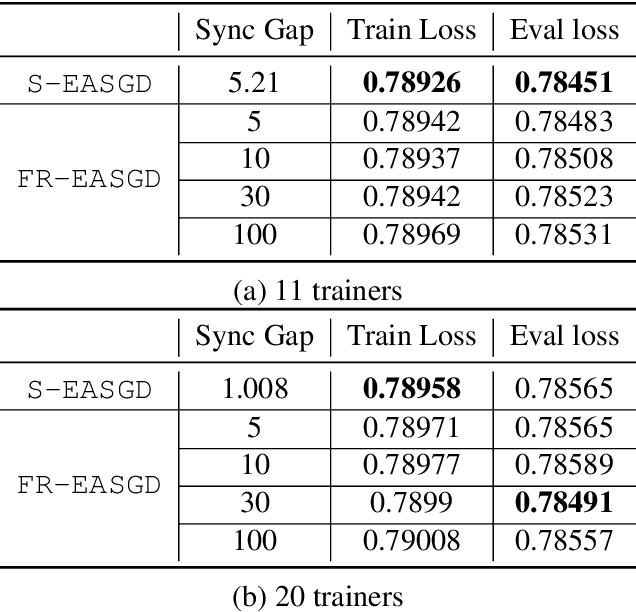
Distributed training is useful to train complicated models to shorten the training time. As each of the workers only sees a small fraction of data, workers need to synchronize on the parameter updates. One of the central questions in distributed training is how to parsimoniously synchronize parameters while preserving model quality. To address this problem, we propose the \textbf{ShadowSync} framework, in which we isolate synchronization from training and run it in the background. In contrast to common strategies including synchronous stochastic gradient descent (SGD), asynchronous SGD, and model averaging on independently trained sub-models, where synchronization happens in the foreground, ShadowSync synchronization is neither part of the backward pass, nor happens every $k$ iterations. Our framework is generic to host various types of synchronization algorithms, and we propose 3 approaches under this theme. The superiority of ShadowSync is confirmed by experiments on training deep neural networks for click-through-rate prediction. Our methods all succeed in making the training throughput linearly scale with the number of trainers. Comparing to their foreground counterparts, our methods exhibit neutral to better model quality and better scalability when we keep the number of parameter servers the same. In our training system which expresses both replication and Hogwild parallelism, ShadowSync also accomplishes the highest example level parallelism number comparing to the prior arts.
Convergence Analysis for Rectangular Matrix Completion Using Burer-Monteiro Factorization and Gradient Descent
Nov 22, 2016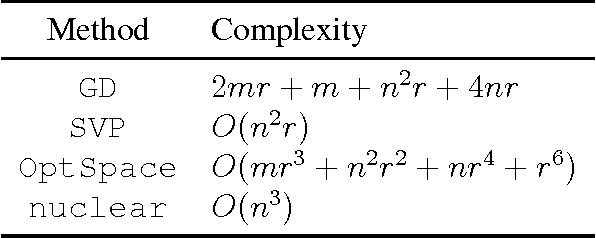
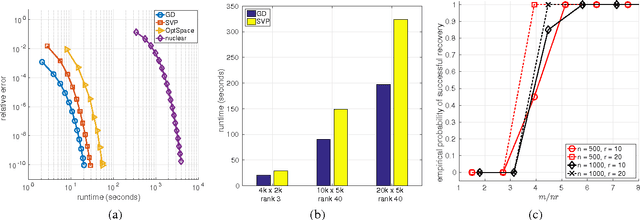
We address the rectangular matrix completion problem by lifting the unknown matrix to a positive semidefinite matrix in higher dimension, and optimizing a nonconvex objective over the semidefinite factor using a simple gradient descent scheme. With $O( \mu r^2 \kappa^2 n \max(\mu, \log n))$ random observations of a $n_1 \times n_2$ $\mu$-incoherent matrix of rank $r$ and condition number $\kappa$, where $n = \max(n_1, n_2)$, the algorithm linearly converges to the global optimum with high probability.
A Convergent Gradient Descent Algorithm for Rank Minimization and Semidefinite Programming from Random Linear Measurements
Mar 24, 2016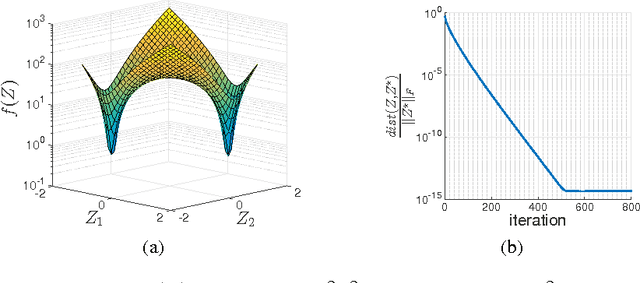

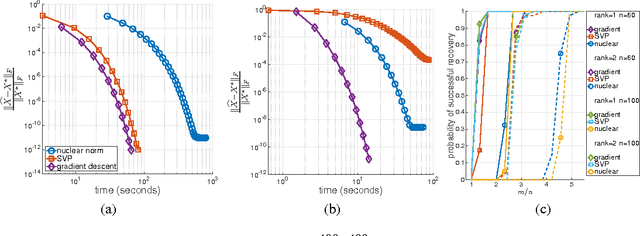
We propose a simple, scalable, and fast gradient descent algorithm to optimize a nonconvex objective for the rank minimization problem and a closely related family of semidefinite programs. With $O(r^3 \kappa^2 n \log n)$ random measurements of a positive semidefinite $n \times n$ matrix of rank $r$ and condition number $\kappa$, our method is guaranteed to converge linearly to the global optimum.
Interpolating Convex and Non-Convex Tensor Decompositions via the Subspace Norm
Oct 27, 2015
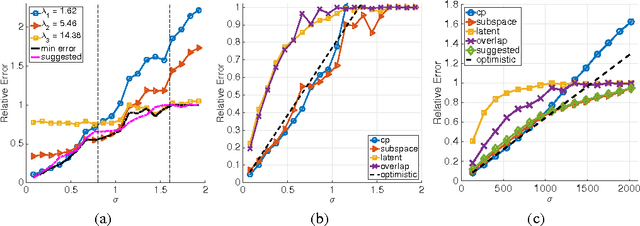
We consider the problem of recovering a low-rank tensor from its noisy observation. Previous work has shown a recovery guarantee with signal to noise ratio $O(n^{\lceil K/2 \rceil /2})$ for recovering a $K$th order rank one tensor of size $n\times \cdots \times n$ by recursive unfolding. In this paper, we first improve this bound to $O(n^{K/4})$ by a much simpler approach, but with a more careful analysis. Then we propose a new norm called the subspace norm, which is based on the Kronecker products of factors obtained by the proposed simple estimator. The imposed Kronecker structure allows us to show a nearly ideal $O(\sqrt{n}+\sqrt{H^{K-1}})$ bound, in which the parameter $H$ controls the blend from the non-convex estimator to mode-wise nuclear norm minimization. Furthermore, we empirically demonstrate that the subspace norm achieves the nearly ideal denoising performance even with $H=O(1)$.