 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-uniform conformal and PAC prediction
Feb 06, 2026Given that machine learning algorithms are increasingly being deployed to aid in high stakes decision-making, uncertainty quantification methods that wrap around these black box models such as conformal prediction have received much attention in recent years. In sequential settings, where data are observed/generated in a streaming fashion, traditional conformal methods do not provide any guarantee without fixing the sample size. More importantly, traditional conformal methods cannot cope with sequentially updated predictions. As such, we develop an extension of the conformal prediction and related probably approximately correct (PAC) prediction frameworks to sequential settings where the number of data points is not fixed in advance. The resulting prediction sets are anytime-valid in that their expected coverage is at the required level at any time chosen by the analyst even if this choice depends on the data. We present theoretical guarantees for our proposed methods and demonstrate their validity and utility on simulated and real datasets.
Subsample Ridge Ensembles: Equivalences and Generalized Cross-Validation
Apr 25, 2023



We study subsampling-based ridge ensembles in the proportional asymptotics regime, where the feature size grows proportionally with the sample size such that their ratio converges to a constant. By analyzing the squared prediction risk of ridge ensembles as a function of the explicit penalty $\lambda$ and the limiting subsample aspect ratio $\phi_s$ (the ratio of the feature size to the subsample size), we characterize contours in the $(\lambda, \phi_s)$-plane at any achievable risk. As a consequence, we prove that the risk of the optimal full ridgeless ensemble (fitted on all possible subsamples) matches that of the optimal ridge predictor. In addition, we prove strong uniform consistency of generalized cross-validation (GCV) over the subsample sizes for estimating the prediction risk of ridge ensembles. This allows for GCV-based tuning of full ridgeless ensembles without sample splitting and yields a predictor whose risk matches optimal ridge risk.
Post-selection Inference for Conformal Prediction: Trading off Coverage for Precision
Apr 14, 2023



Conformal inference has played a pivotal role in providing uncertainty quantification for black-box ML prediction algorithms with finite sample guarantees. Traditionally, conformal prediction inference requires a data-independent specification of miscoverage level. In practical applications, one might want to update the miscoverage level after computing the prediction set. For example, in the context of binary classification, the analyst might start with a $95\%$ prediction sets and see that most prediction sets contain all outcome classes. Prediction sets with both classes being undesirable, the analyst might desire to consider, say $80\%$ prediction set. Construction of prediction sets that guarantee coverage with data-dependent miscoverage level can be considered as a post-selection inference problem. In this work, we develop uniform conformal inference with finite sample prediction guarantee with arbitrary data-dependent miscoverage levels using distribution-free confidence bands for distribution functions. This allows practitioners to trade freely coverage probability for the quality of the prediction set by any criterion of their choice (say size of prediction set) while maintaining the finite sample guarantees similar to traditional conformal inference.
Extrapolated cross-validation for randomized ensembles
Feb 27, 2023Ensemble methods such as bagging and random forests are ubiquitous in fields ranging from finance to genomics. However, the question of the efficient tuning of ensemble parameters has received relatively little attention. In this paper, we propose a cross-validation method, ECV (Extrapolated Cross-Validation), for tuning the ensemble and subsample sizes of randomized ensembles. Our method builds on two main ingredients: two initial estimators for small ensemble sizes using out-of-bag errors and a novel risk extrapolation technique leveraging the structure of the prediction risk decomposition. By establishing uniform consistency over ensemble and subsample sizes, we show that ECV yields $\delta$-optimal (with respect to the oracle-tuned risk) ensembles for squared prediction risk. Our theory accommodates general ensemble predictors, requires mild moment assumptions, and allows for high-dimensional regimes where the feature dimension grows with the sample size. As an illustrative example, we employ ECV to predict surface protein abundances from gene expressions in single-cell multiomics using random forests. Compared to sample-split cross-validation and K-fold cross-validation, ECV achieves higher accuracy avoiding sample splitting. Meanwhile, its computational cost is considerably lower owing to the use of the risk extrapolation technique. Further numerical results demonstrate the finite-sample accuracy of ECV for several common ensemble predictors.
Bagging in overparameterized learning: Risk characterization and risk monotonization
Oct 20, 2022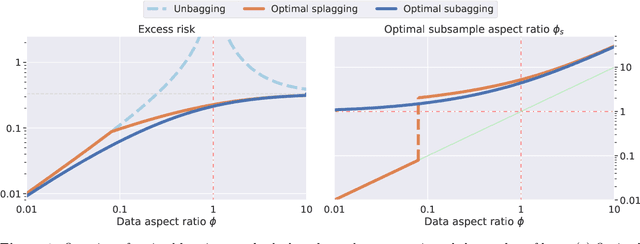

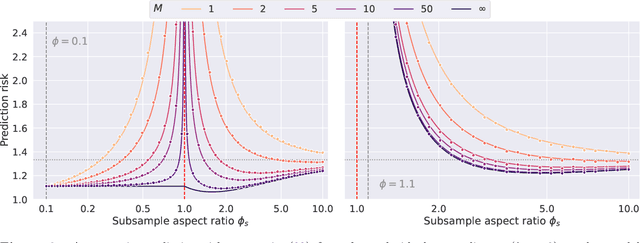
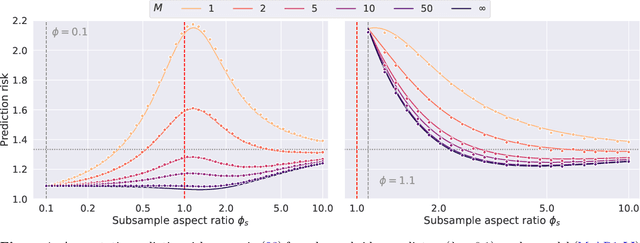
Bagging is a commonly used ensemble technique in statistics and machine learning to improve the performance of prediction procedures. In this paper, we study the prediction risk of variants of bagged predictors in the proportional asymptotics regime, in which the ratio of the number of features to the number of observations converges to a constant. Specifically, we propose a general strategy to analyze prediction risk under squared error loss of bagged predictors using classical results on simple random sampling. Specializing the strategy, we derive the exact asymptotic risk of the bagged ridge and ridgeless predictors with an arbitrary number of bags under a well-specified linear model with arbitrary feature covariance matrices and signal vectors. Furthermore, we prescribe a generic cross-validation procedure to select the optimal subsample size for bagging and discuss its utility to mitigate the non-monotonic behavior of the limiting risk in the sample size (i.e., double or multiple descents). In demonstrating the proposed procedure for bagged ridge and ridgeless predictors, we thoroughly investigate oracle properties of the optimal subsample size, and provide an in-depth comparison between different bagging variants.
Mitigating multiple descents: A model-agnostic framework for risk monotonization
May 25, 2022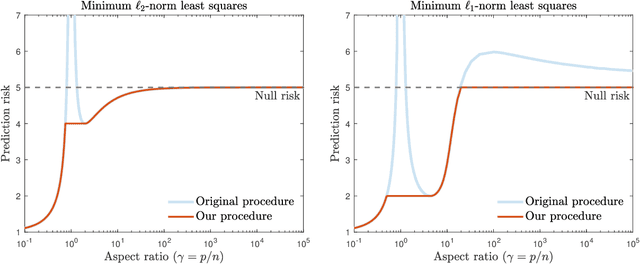
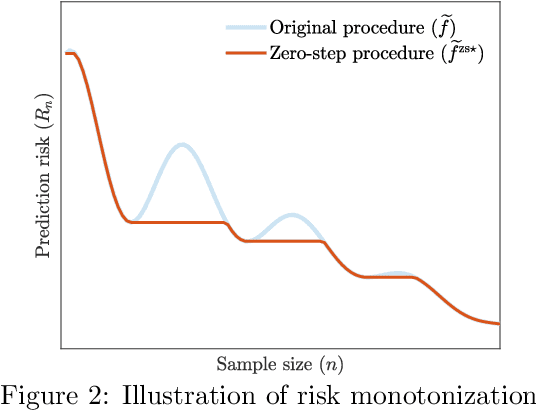
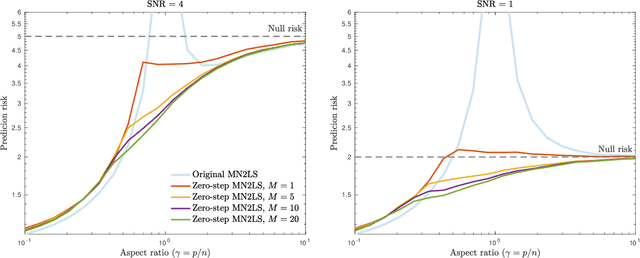
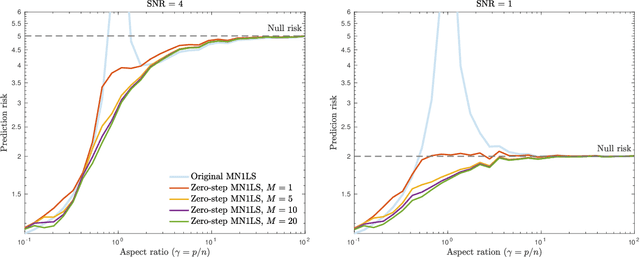
Recent empirical and theoretical analyses of several commonly used prediction procedures reveal a peculiar risk behavior in high dimensions, referred to as double/multiple descent, in which the asymptotic risk is a non-monotonic function of the limiting aspect ratio of the number of features or parameters to the sample size. To mitigate this undesirable behavior, we develop a general framework for risk monotonization based on cross-validation that takes as input a generic prediction procedure and returns a modified procedure whose out-of-sample prediction risk is, asymptotically, monotonic in the limiting aspect ratio. As part of our framework, we propose two data-driven methodologies, namely zero- and one-step, that are akin to bagging and boosting, respectively, and show that, under very mild assumptions, they provably achieve monotonic asymptotic risk behavior. Our results are applicable to a broad variety of prediction procedures and loss functions, and do not require a well-specified (parametric) model. We exemplify our framework with concrete analyses of the minimum $\ell_2$, $\ell_1$-norm least squares prediction procedures. As one of the ingredients in our analysis, we also derive novel additive and multiplicative forms of oracle risk inequalities for split cross-validation that are of independent interest.
Improving Fairness in Criminal Justice Algorithmic Risk Assessments Using Conformal Prediction Sets
Aug 26, 2020



Risk assessment algorithms have been correctly criticized for potential unfairness, and there is an active cottage industry trying to make repairs. In this paper, we adopt a framework from conformal prediction sets to remove unfairness from risk algorithms themselves and the covariates used for forecasting. From a sample of 300,000 offenders at their arraignments, we construct a confusion table and its derived measures of fairness that are effectively free any meaningful differences between Black and White offenders. We also produce fair forecasts for individual offenders coupled with valid probability guarantees that the forecasted outcome is the true outcome. We see our work as a demonstration of concept for application in a wide variety of criminal justice decisions. The procedures provided can be routinely implemented in jurisdictions with the usual criminal justice datasets used by administrators. The requisite procedures can be found in the scripting software R. However, whether stakeholders will accept our approach as a means to achieve risk assessment fairness is unknown. There also are legal issues that would need to be resolved although we offer a Pareto improvement.
Near-Optimal Confidence Sequences for Bounded Random Variables
Jun 09, 2020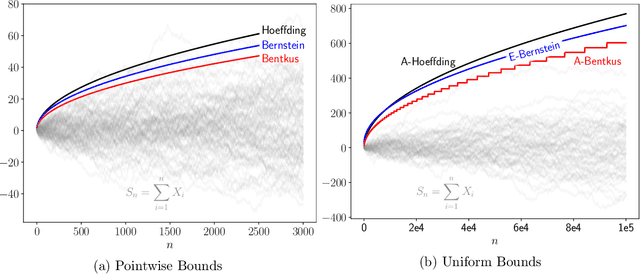
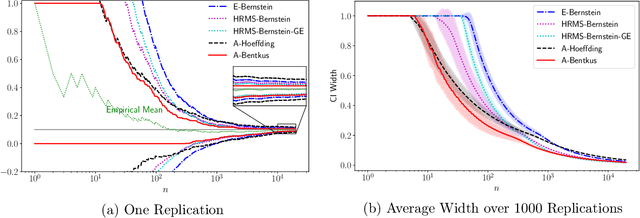
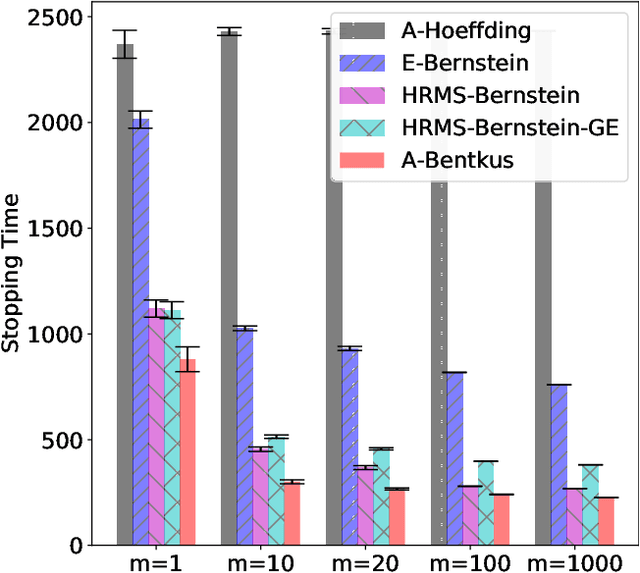
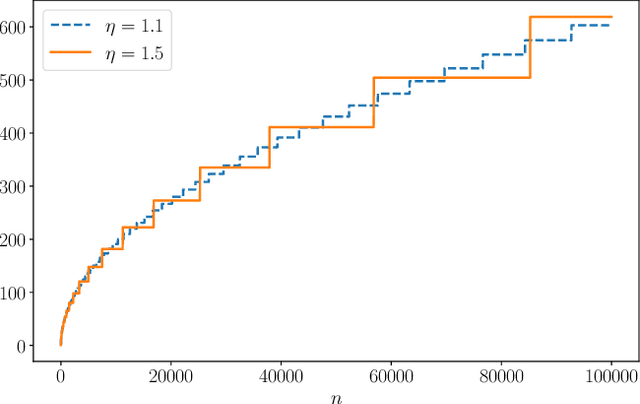
Many inference problems, such as sequential decision problems like A/B testing, adaptive sampling schemes like bandit selection, are often online in nature. The fundamental problem for online inference is to provide a sequence of confidence intervals that are valid uniformly over the growing-into-infinity sample sizes. To address this question, we provide a near-optimal confidence sequence for bounded random variables by utilizing Bentkus' concentration results. We show that it improves on the existing approaches that use the Cram{\'e}r-Chernoff technique such as the Hoeffding, Bernstein, and Bennett inequalities. The resulting confidence sequence is confirmed to be favorable in both synthetic coverage problems and an application to adaptive stopping algorithms.
Exchangeability, Conformal Prediction, and Rank Tests
May 13, 2020
Conformal prediction has been a very popular method of distribution-free predictive inference in recent years in machine learning and statistics. The main reason for its popularity comes from the fact that it works as a wrapper around any prediction algorithm such as neural networks or random forests. Exchangeability is at the core of the validity of conformal prediction. The concept of exchangeability is also at the core of rank tests widely known in nonparametric statistics. In this paper, we review the concept of exchangeability and discuss its implications for rank tests and conformal prediction. Although written as an exposition, the main message of the paper is to show that similar to conformal prediction, rank tests can also be used as a wrapper around any dimension reduction algorithm.
Deterministic Inequalities for Smooth M-estimators
Sep 13, 2018Ever since the proof of asymptotic normality of maximum likelihood estimator by Cramer (1946), it has been understood that a basic technique of the Taylor series expansion suffices for asymptotics of $M$-estimators with smooth/differentiable loss function. Although the Taylor series expansion is a purely deterministic tool, the realization that the asymptotic normality results can also be made deterministic (and so finite sample) received far less attention. With the advent of big data and high-dimensional statistics, the need for finite sample results has increased. In this paper, we use the (well-known) Banach fixed point theorem to derive various deterministic inequalities that lead to the classical results when studied under randomness. In addition, we provide applications of these deterministic inequalities for crossvalidation/subsampling, marginal screening and uniform-in-submodel results that are very useful for post-selection inference and in the study of post-regularization estimators. Our results apply to many classical estimators, in particular, generalized linear models, non-linear regression and cox proportional hazards model. Extensions to non-smooth and constrained problems are also discussed.