 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine-Robust Distributed Online Learning: Taming Adversarial Participants in An Adversarial Environment
Jul 16, 2023



This paper studies distributed online learning under Byzantine attacks. The performance of an online learning algorithm is often characterized by (adversarial) regret, which evaluates the quality of one-step-ahead decision-making when an environment provides adversarial losses, and a sublinear bound is preferred. But we prove that, even with a class of state-of-the-art robust aggregation rules, in an adversarial environment and in the presence of Byzantine participants, distributed online gradient descent can only achieve a linear adversarial regret bound, which is tight. This is the inevitable consequence of Byzantine attacks, even though we can control the constant of the linear adversarial regret to a reasonable level. Interestingly, when the environment is not fully adversarial so that the losses of the honest participants are i.i.d. (independent and identically distributed), we show that sublinear stochastic regret, in contrast to the aforementioned adversarial regret, is possible. We develop a Byzantine-robust distributed online momentum algorithm to attain such a sublinear stochastic regret bound. Extensive numerical experiments corroborate our theoretical analysis.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023



Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.
Spectral Adversarial Training for Robust Graph Neural Network
Nov 20, 2022Recent studies demonstrate that Graph Neural Networks (GNNs) are vulnerable to slight but adversarially designed perturbations, known as adversarial examples. To address this issue, robust training methods against adversarial examples have received considerable attention in the literature. \emph{Adversarial Training (AT)} is a successful approach to learning a robust model using adversarially perturbed training samples. Existing AT methods on GNNs typically construct adversarial perturbations in terms of graph structures or node features. However, they are less effective and fraught with challenges on graph data due to the discreteness of graph structure and the relationships between connected examples. In this work, we seek to address these challenges and propose Spectral Adversarial Training (SAT), a simple yet effective adversarial training approach for GNNs. SAT first adopts a low-rank approximation of the graph structure based on spectral decomposition, and then constructs adversarial perturbations in the spectral domain rather than directly manipulating the original graph structure. To investigate its effectiveness, we employ SAT on three widely used GNNs. Experimental results on four public graph datasets demonstrate that SAT significantly improves the robustness of GNNs against adversarial attacks without sacrificing classification accuracy and training efficiency.
Lazy Queries Can Reduce Variance in Zeroth-order Optimization
Jun 14, 2022
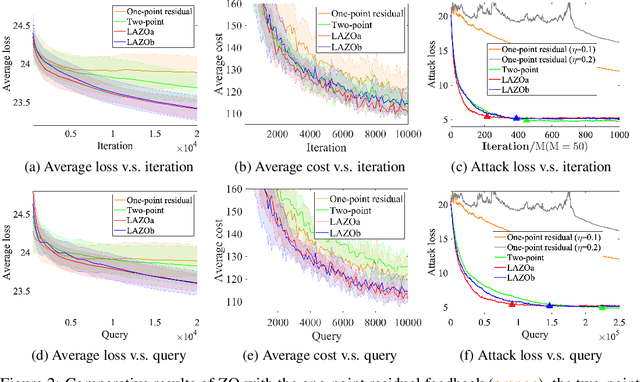

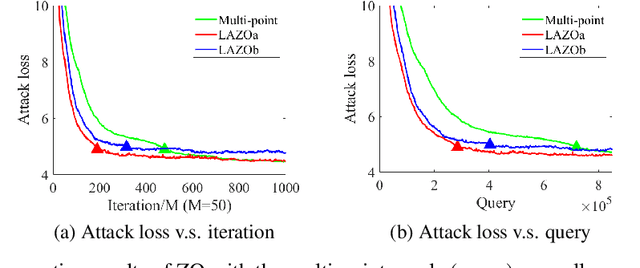
A major challenge of applying zeroth-order (ZO) methods is the high query complexity, especially when queries are costly. We propose a novel gradient estimation technique for ZO methods based on adaptive lazy queries that we term as LAZO. Different from the classic one-point or two-point gradient estimation methods, LAZO develops two alternative ways to check the usefulness of old queries from previous iterations, and then adaptively reuses them to construct the low-variance gradient estimates. We rigorously establish that through judiciously reusing the old queries, LAZO can reduce the variance of stochastic gradient estimates so that it not only saves queries per iteration but also achieves the regret bound for the symmetric two-point method. We evaluate the numerical performance of LAZO, and demonstrate the low-variance property and the performance gain of LAZO in both regret and query complexity relative to several existing ZO methods. The idea of LAZO is general, and can be applied to other variants of ZO methods.
Confederated Learning: Federated Learning with Decentralized Edge Servers
May 30, 2022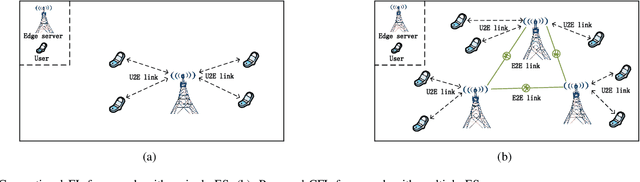
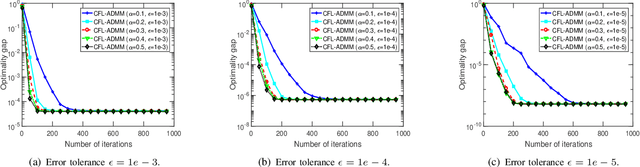
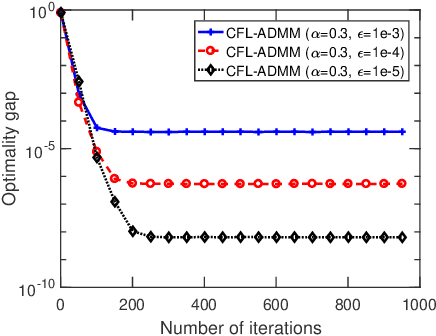
Federated learning (FL) is an emerging machine learning paradigm that allows to accomplish model training without aggregating data at a central server. Most studies on FL consider a centralized framework, in which a single server is endowed with a central authority to coordinate a number of devices to perform model training in an iterative manner. Due to stringent communication and bandwidth constraints, such a centralized framework has limited scalability as the number of devices grows. To address this issue, in this paper, we propose a ConFederated Learning (CFL) framework. The proposed CFL consists of multiple servers, in which each server is connected with an individual set of devices as in the conventional FL framework, and decentralized collaboration is leveraged among servers to make full use of the data dispersed throughout the network. We develop an alternating direction method of multipliers (ADMM) algorithm for CFL. The proposed algorithm employs a random scheduling policy which randomly selects a subset of devices to access their respective servers at each iteration, thus alleviating the need of uploading a huge amount of information from devices to servers. Theoretical analysis is presented to justify the proposed method. Numerical results show that the proposed method can converge to a decent solution significantly faster than gradient-based FL algorithms, thus boasting a substantial advantage in terms of communication efficiency.
Bridging Differential Privacy and Byzantine-Robustness via Model Aggregation
Apr 29, 2022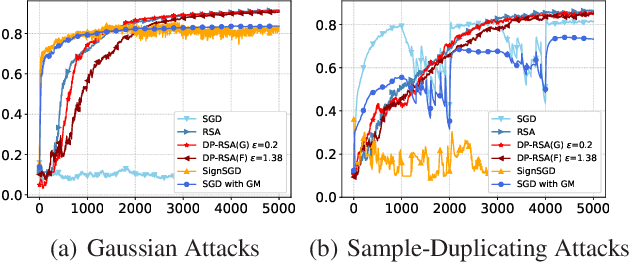
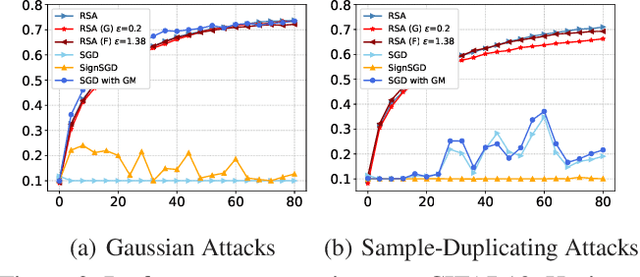
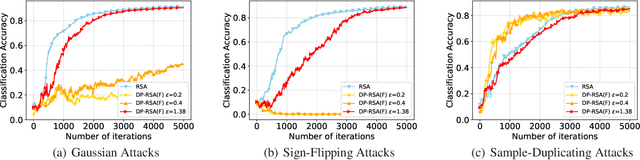
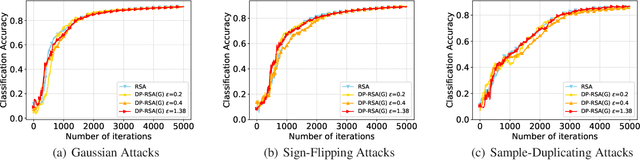
This paper aims at jointly addressing two seemly conflicting issues in federated learning: differential privacy (DP) and Byzantine-robustness, which are particularly challenging when the distributed data are non-i.i.d. (independent and identically distributed). The standard DP mechanisms add noise to the transmitted messages, and entangles with robust stochastic gradient aggregation to defend against Byzantine attacks. In this paper, we decouple the two issues via robust stochastic model aggregation, in the sense that our proposed DP mechanisms and the defense against Byzantine attacks have separated influence on the learning performance. Leveraging robust stochastic model aggregation, at each iteration, each worker calculates the difference between the local model and the global one, followed by sending the element-wise signs to the master node, which enables robustness to Byzantine attacks. Further, we design two DP mechanisms to perturb the uploaded signs for the purpose of privacy preservation, and prove that they are $(\epsilon,0)$-DP by exploiting the properties of noise distributions. With the tools of Moreau envelop and proximal point projection, we establish the convergence of the proposed algorithm when the cost function is nonconvex. We analyze the trade-off between privacy preservation and learning performance, and show that the influence of our proposed DP mechanisms is decoupled with that of robust stochastic model aggregation. Numerical experiments demonstrate the effectiveness of the proposed algorithm.
Stochastic Alternating Direction Method of Multipliers for Byzantine-Robust Distributed Learning
Jun 13, 2021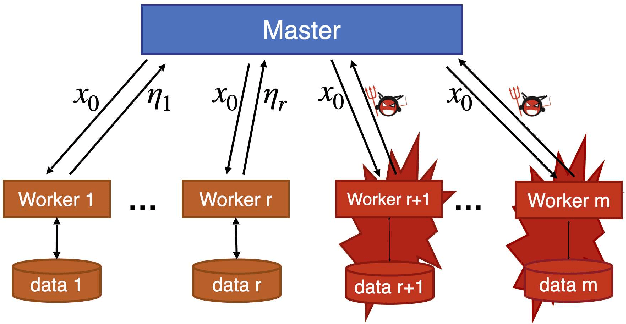
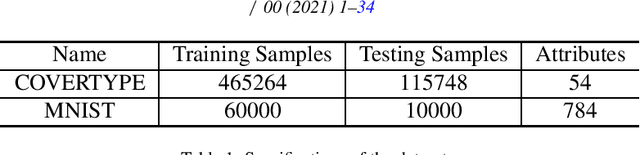
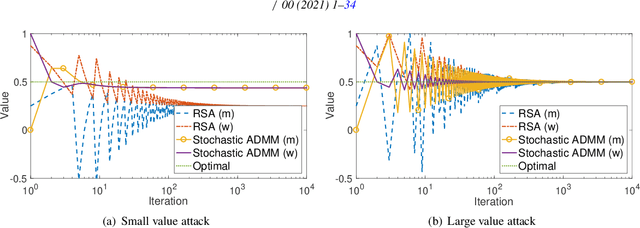
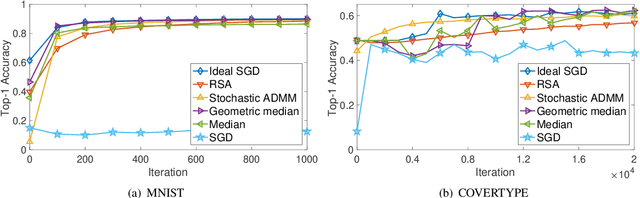
This paper aims to solve a distributed learning problem under Byzantine attacks. In the underlying distributed system, a number of unknown but malicious workers (termed as Byzantine workers) can send arbitrary messages to the master and bias the learning process, due to data corruptions, computation errors or malicious attacks. Prior work has considered a total variation (TV) norm-penalized approximation formulation to handle the Byzantine attacks, where the TV norm penalty forces the regular workers' local variables to be close, and meanwhile, tolerates the outliers sent by the Byzantine workers. To solve the TV norm-penalized approximation formulation, we propose a Byzantine-robust stochastic alternating direction method of multipliers (ADMM) that fully utilizes the separable problem structure. Theoretically, we prove that the proposed method converges to a bounded neighborhood of the optimal solution at a rate of O(1/k) under mild assumptions, where k is the number of iterations and the size of neighborhood is determined by the number of Byzantine workers. Numerical experiments on the MNIST and COVERTYPE datasets demonstrate the effectiveness of the proposed method to various Byzantine attacks.
BROADCAST: Reducing Both Stochastic and Compression Noise to Robustify Communication-Efficient Federated Learning
Apr 14, 2021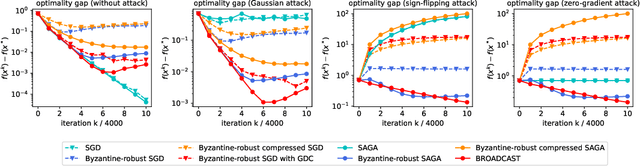
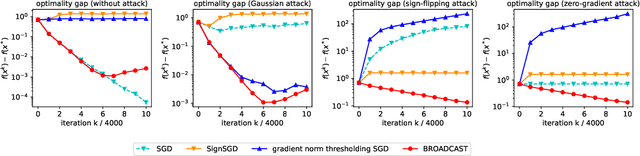
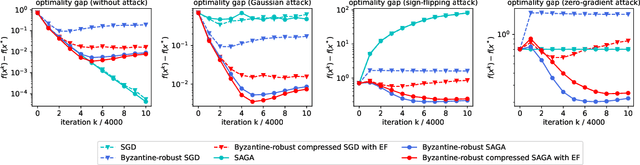
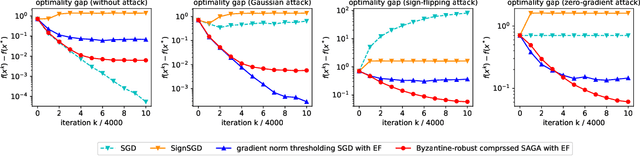
Communication between workers and the master node to collect local stochastic gradients is a key bottleneck in a large-scale federated learning system. Various recent works have proposed to compress the local stochastic gradients to mitigate the communication overhead. However, robustness to malicious attacks is rarely considered in such a setting. In this work, we investigate the problem of Byzantine-robust federated learning with compression, where the attacks from Byzantine workers can be arbitrarily malicious. We point out that a vanilla combination of compressed stochastic gradient descent (SGD) and geometric median-based robust aggregation suffers from both stochastic and compression noise in the presence of Byzantine attacks. In light of this observation, we propose to jointly reduce the stochastic and compression noise so as to improve the Byzantine-robustness. For the stochastic noise, we adopt the stochastic average gradient algorithm (SAGA) to gradually eliminate the inner variations of regular workers. For the compression noise, we apply the gradient difference compression and achieve compression for free. We theoretically prove that the proposed algorithm reaches a neighborhood of the optimal solution at a linear convergence rate, and the asymptotic learning error is in the same order as that of the state-of-the-art uncompressed method. Finally, numerical experiments demonstrate effectiveness of the proposed method.
Byzantine-Robust Variance-Reduced Federated Learning over Distributed Non-i.i.d. Data
Sep 17, 2020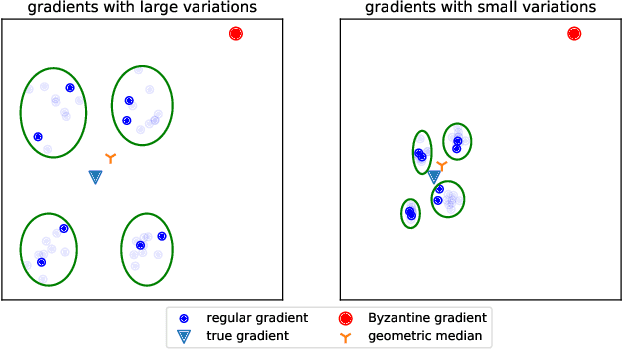

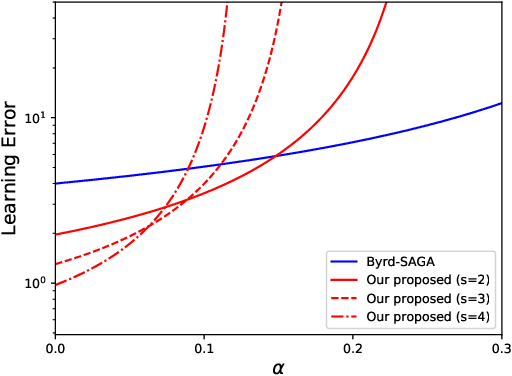
We propose a Byzantine-robust variance-reduced stochastic gradient descent (SGD) method to solve the distributed finite-sum minimization problem when the data on the workers are not independent and identically distributed (i.i.d.). During the learning process, an unknown number of Byzantine workers may send malicious messages to the master node, leading to remarkable learning error. Most of the Byzantine-robust methods address this issue by using robust aggregation rules to aggregate the received messages, but rely on the assumption that all the regular workers have i.i.d. data, which is not the case in many federated learning applications. In light of the significance of reducing stochastic gradient noise for mitigating the effect of Byzantine attacks, we use a resampling strategy to reduce the impact of both inner variation (that describes the sample heterogeneity on every regular worker) and outer variation (that describes the sample heterogeneity among the regular workers), along with a stochastic average gradient algorithm (SAGA) to fully eliminate the inner variation. The variance-reduced messages are then aggregated with a robust geometric median operator. Under certain conditions, we prove that the proposed method reaches a neighborhood of the optimal solution with linear convergence rate, and the learning error is much smaller than those given by the state-of-the-art methods in the non-i.i.d. setting. Numerical experiments corroborate the theoretical results and show satisfactory performance of the proposed method.
Byzantine-Robust Decentralized Stochastic Optimization over Static and Time-Varying Networks
May 12, 2020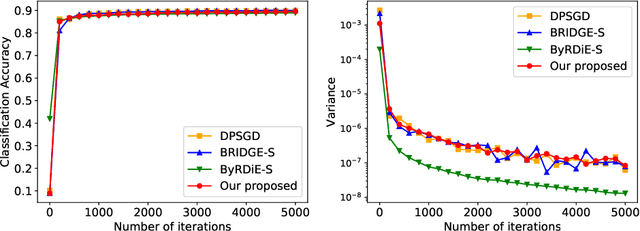
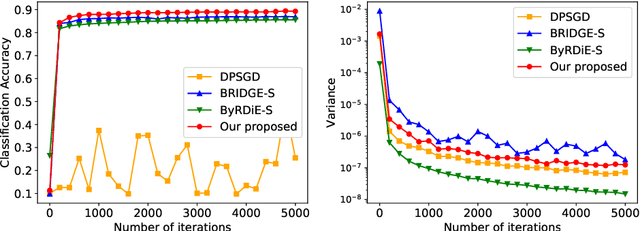
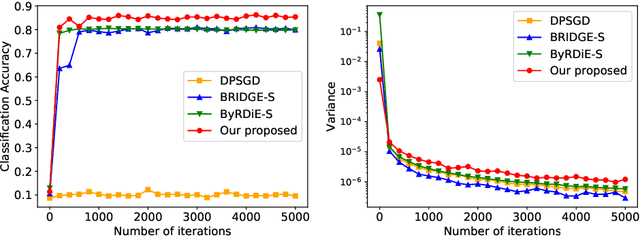
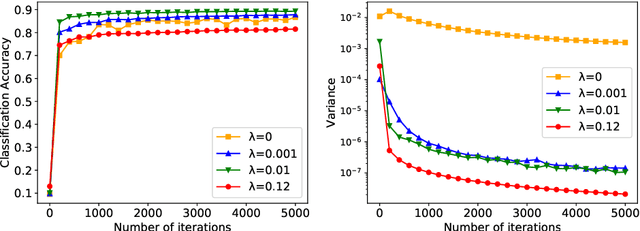
In this paper, we consider the Byzantine-robust stochastic optimization problem defined over decentralized static and time-varying networks, where the agents collaboratively minimize the summation of expectations of stochastic local cost functions, but some of the agents are unreliable due to data corruptions, equipment failures or cyber-attacks. The unreliable agents, which are called as Byzantine agents thereafter, can send faulty values to their neighbors and bias the optimization process. Our key idea to handle the Byzantine attacks is to formulate a total variation (TV) norm-penalized approximation of the Byzantine-free problem, where the penalty term forces the local models of regular agents to be close, but also allows the existence of outliers from the Byzantine agents. A stochastic subgradient method is applied to solve the penalized problem. We prove that the proposed method reaches a neighborhood of the Byzantine-free optimal solution, and the size of neighborhood is determined by the number of Byzantine agents and the network topology. Numerical experiments corroborate the theoretical analysis, as well as demonstrate the robustness of the proposed method to Byzantine attacks and its superior performance comparing to existing methods.