 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Attentive Memory Network for Click-through Rate Prediction with Long Sequences
Aug 08, 2022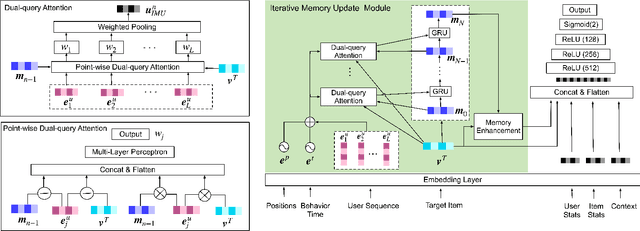
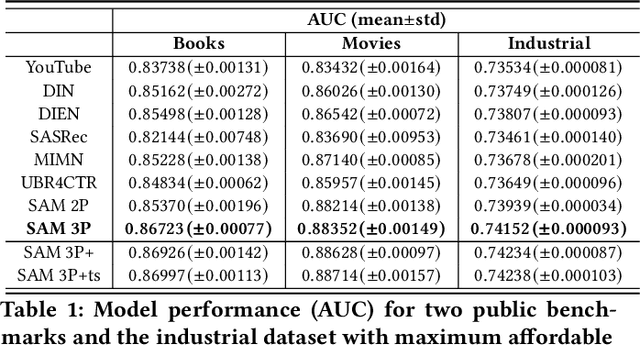
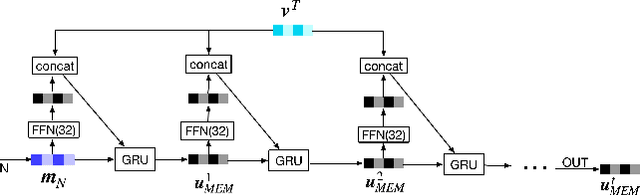
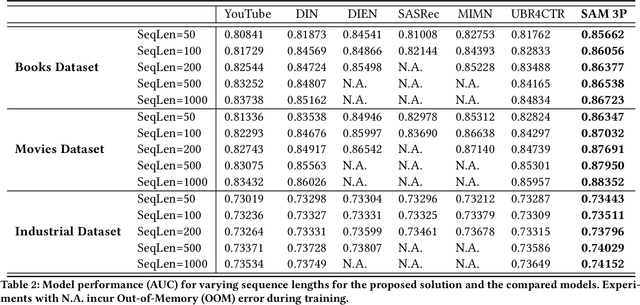
Sequential recommendation predicts users' next behaviors with their historical interactions. Recommending with longer sequences improves recommendation accuracy and increases the degree of personalization. As sequences get longer, existing works have not yet addressed the following two main challenges. Firstly, modeling long-range intra-sequence dependency is difficult with increasing sequence lengths. Secondly, it requires efficient memory and computational speeds. In this paper, we propose a Sparse Attentive Memory (SAM) network for long sequential user behavior modeling. SAM supports efficient training and real-time inference for user behavior sequences with lengths on the scale of thousands. In SAM, we model the target item as the query and the long sequence as the knowledge database, where the former continuously elicits relevant information from the latter. SAM simultaneously models target-sequence dependencies and long-range intra-sequence dependencies with O(L) complexity and O(1) number of sequential updates, which can only be achieved by the self-attention mechanism with O(L^2) complexity. Extensive empirical results demonstrate that our proposed solution is effective not only in long user behavior modeling but also on short sequences modeling. Implemented on sequences of length 1000, SAM is successfully deployed on one of the largest international E-commerce platforms. This inference time is within 30ms, with a substantial 7.30% click-through rate improvement for the online A/B test. To the best of our knowledge, it is the first end-to-end long user sequence modeling framework that models intra-sequence and target-sequence dependencies with the aforementioned degree of efficiency and successfully deployed on a large-scale real-time industrial recommender system.
A General Traffic Shaping Protocol in E-Commerce
Dec 30, 2021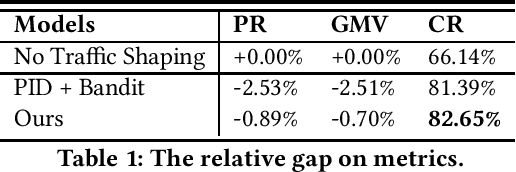
To approach different business objectives, online traffic shaping algorithms aim at improving exposures of a target set of items, such as boosting the growth of new commodities. Generally, these algorithms assume that the utility of each user-item pair can be accessed via a well-trained conversion rate prediction model. However, for real E-Commerce platforms, there are unavoidable factors preventing us from learning such an accurate model. In order to break the heavy dependence on accurate inputs of the utility, we propose a general online traffic shaping protocol for online E-Commerce applications. In our framework, we approximate the function mapping the bonus scores, which generally are the only method to influence the ranking result in the traffic shaping problem, to the numbers of exposures and purchases. Concretely, we approximate the above function by a class of the piece-wise linear function constructed on the convex hull of the explored data points. Moreover, we reformulate the online traffic shaping problem as linear programming where these piece-wise linear functions are embedded into both the objective and constraints. Our algorithm can straightforwardly optimize the linear programming in the prime space, and its solution can be simply applied by a stochastic strategy to fulfill the optimized objective and the constraints in expectation. Finally, the online A/B test shows our proposed algorithm steadily outperforms the previous industrial level traffic shaping algorithm.
Learning-To-Ensemble by Contextual Rank Aggregation in E-Commerce
Aug 10, 2021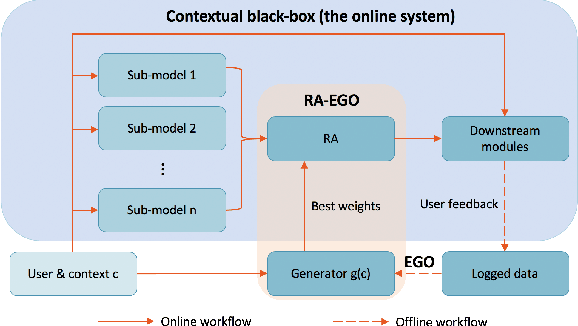
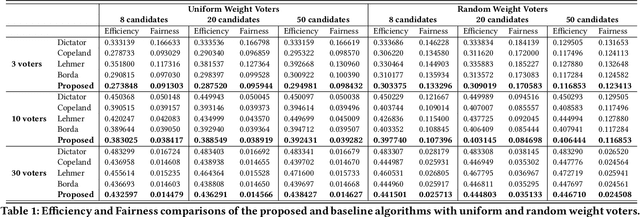
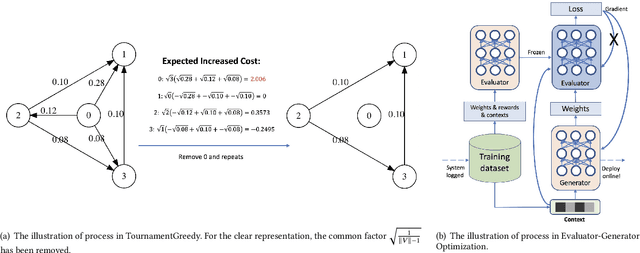

Ensemble models in E-commerce combine predictions from multiple sub-models for ranking and revenue improvement. Industrial ensemble models are typically deep neural networks, following the supervised learning paradigm to infer conversion rate given inputs from sub-models. However, this process has the following two problems. Firstly, the point-wise scoring approach disregards the relationships between items and leads to homogeneous displayed results, while diversified display benefits user experience and revenue. Secondly, the learning paradigm focuses on the ranking metrics and does not directly optimize the revenue. In our work, we propose a new Learning-To-Ensemble (LTE) framework RAEGO, which replaces the ensemble model with a contextual Rank Aggregator (RA) and explores the best weights of sub-models by the Evaluator-Generator Optimization (EGO). To achieve the best online performance, we propose a new rank aggregation algorithm TournamentGreedy as a refinement of classic rank aggregators, which also produces the best average weighted Kendall Tau Distance (KTD) amongst all the considered algorithms with quadratic time complexity. Under the assumption that the best output list should be Pareto Optimal on the KTD metric for sub-models, we show that our RA algorithm has higher efficiency and coverage in exploring the optimal weights. Combined with the idea of Bayesian Optimization and gradient descent, we solve the online contextual Black-Box Optimization task that finds the optimal weights for sub-models given a chosen RA model. RA-EGO has been deployed in our online system and has improved the revenue significantly.
Imitate TheWorld: A Search Engine Simulation Platform
Aug 10, 2021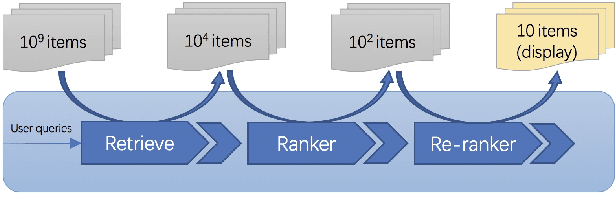
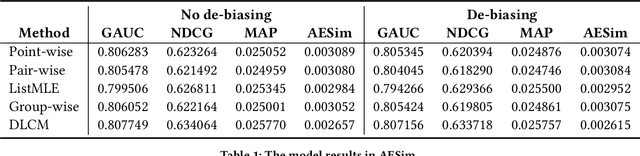
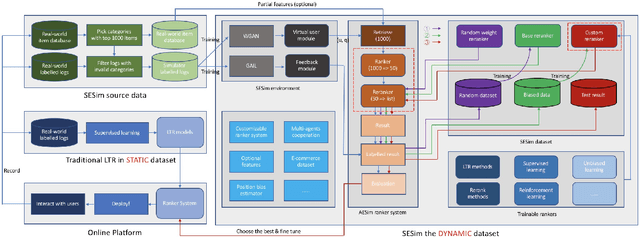

Recent E-commerce applications benefit from the growth of deep learning techniques. However, we notice that many works attempt to maximize business objectives by closely matching offline labels which follow the supervised learning paradigm. This results in models obtain high offline performance in terms of Area Under Curve (AUC) and Normalized Discounted Cumulative Gain (NDCG), but cannot consistently increase the revenue metrics such as purchases amount of users. Towards the issues, we build a simulated search engine AESim that can properly give feedback by a well-trained discriminator for generated pages, as a dynamic dataset. Different from previous simulation platforms which lose connection with the real world, ours depends on the real data in AliExpress Search: we use adversarial learning to generate virtual users and use Generative Adversarial Imitation Learning (GAIL) to capture behavior patterns of users. Our experiments also show AESim can better reflect the online performance of ranking models than classic ranking metrics, implying AESim can play a surrogate of AliExpress Search and evaluate models without going online.
Diversity Regularized Interests Modeling for Recommender Systems
Mar 23, 2021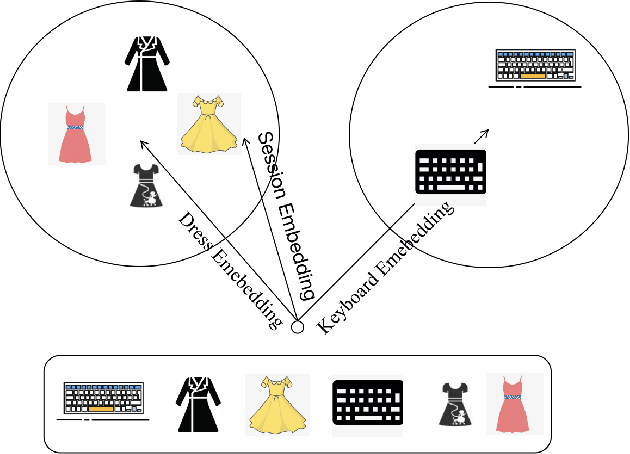

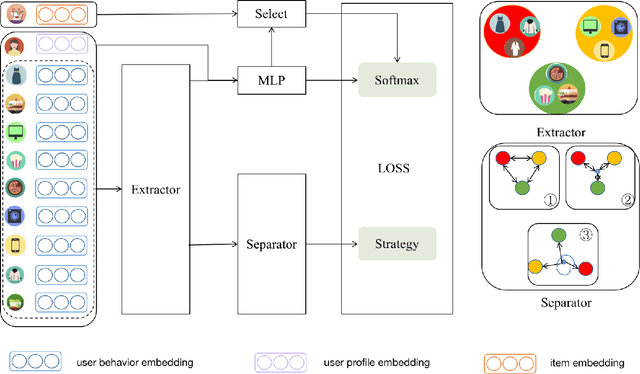

With the rapid development of E-commerce and the increase in the quantity of items, users are presented with more items hence their interests broaden. It is increasingly difficult to model user intentions with traditional methods, which model the user's preference for an item by combining a single user vector and an item vector. Recently, some methods are proposed to generate multiple user interest vectors and achieve better performance compared to traditional methods. However, empirical studies demonstrate that vectors generated from these multi-interests methods are sometimes homogeneous, which may lead to sub-optimal performance. In this paper, we propose a novel method of Diversity Regularized Interests Modeling (DRIM) for Recommender Systems. We apply a capsule network in a multi-interest extractor to generate multiple user interest vectors. Each interest of the user should have a certain degree of distinction, thus we introduce three strategies as the diversity regularized separator to separate multiple user interest vectors. Experimental results on public and industrial data sets demonstrate the ability of the model to capture different interests of a user and the superior performance of the proposed approach.
Delayed Feedback Modeling for the Entire Space Conversion Rate Prediction
Nov 24, 2020
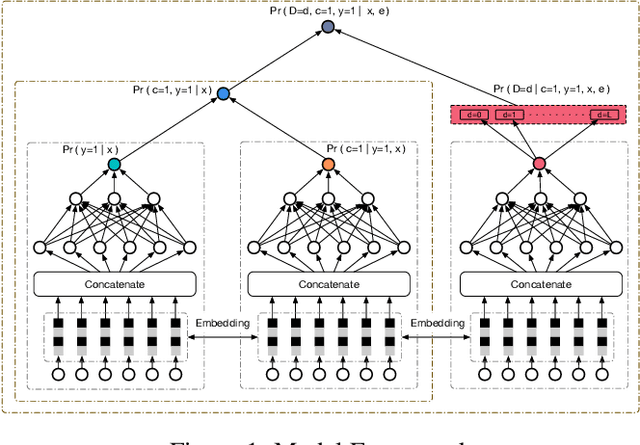
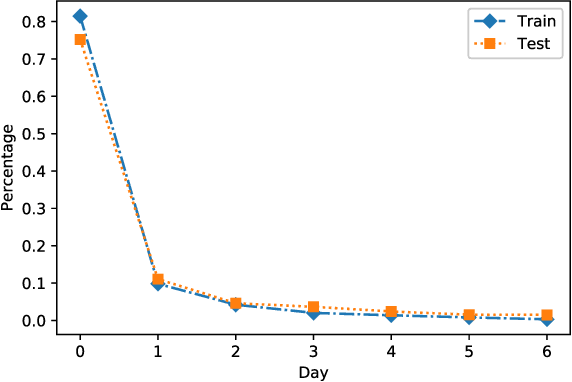

Estimating post-click conversion rate (CVR) accurately is crucial in E-commerce. However, CVR prediction usually suffers from three major challenges in practice: i) data sparsity: compared with impressions, conversion samples are often extremely scarce; ii) sample selection bias: conventional CVR models are trained with clicked impressions while making inference on the entire space of all impressions; iii) delayed feedback: many conversions can only be observed after a relatively long and random delay since clicks happened, resulting in many false negative labels during training. Previous studies mainly focus on one or two issues while ignoring the others. In this paper, we propose a novel neural network framework ESDF to tackle the above three challenges simultaneously. Unlike existing methods, ESDF models the CVR prediction from a perspective of entire space, and combines the advantage of user sequential behavior pattern and the time delay factor. Specifically, ESDF utilizes sequential behavior of user actions on the entire space with all impressions to alleviate the sample selection bias problem. By sharing the embedding parameters between CTR and CVR networks, data sparsity problem is greatly relieved. Different from conventional delayed feedback methods, ESDF does not make any special assumption about the delay distribution. We discretize the delay time by day slot and model the probability based on survival analysis with deep neural network, which is more practical and suitable for industrial situations. Extensive experiments are conducted to evaluate the effectiveness of our method. To the best of our knowledge, ESDF is the first attempt to unitedly solve the above three challenges in CVR prediction area.
Validation Set Evaluation can be Wrong: An Evaluator-Generator Approach for Maximizing Online Performance of Ranking in E-commerce
Mar 27, 2020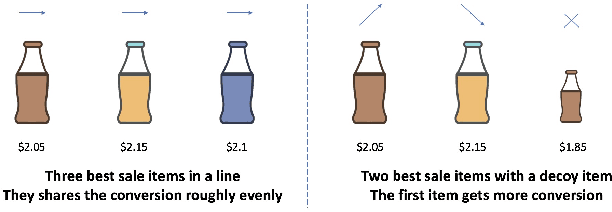
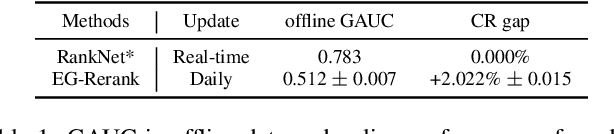
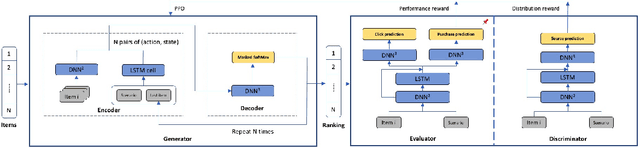
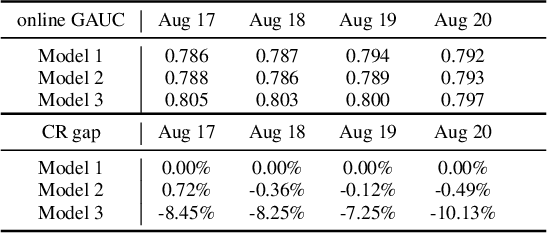
Learning-to-rank (LTR) has become a key technology in E-commerce applications. Previous LTR approaches followed the supervised learning paradigm so that learned models should match the labeled data point-wisely or pair-wisely. However, we have noticed that global context information, including the total order of items in the displayed webpage, can play an important role in interactions with the customers. Therefore, to approach the best global ordering, the exploration in a large combinatorial space of items is necessary, which requires evaluating orders that may not appear in the labeled data. In this scenario, we first show that the classical data-based metrics can be inconsistent with online performance, or even misleading. We then propose to learn an evaluator and search the best model guided by the evaluator, which forms the evaluator-generator framework for training the group-wise LTR model. The evaluator is learned from the labeled data, and is enhanced by incorporating the order context information. The generator is trained with the supervision of the evaluator by reinforcement learning to generate the best order in the combinatorial space. Our experiments in one of the world's largest retail platforms disclose that the learned evaluator is a much better indicator than classical data-based metrics. Moreover, our LTR model achieves a significant improvement ($\textgreater2\%$) from the current industrial-level pair-wise models in terms of both Conversion Rate (CR) and Gross Merchandise Volume (GMV) in online A/B tests.
Policy Optimization with Model-based Explorations
Nov 18, 2018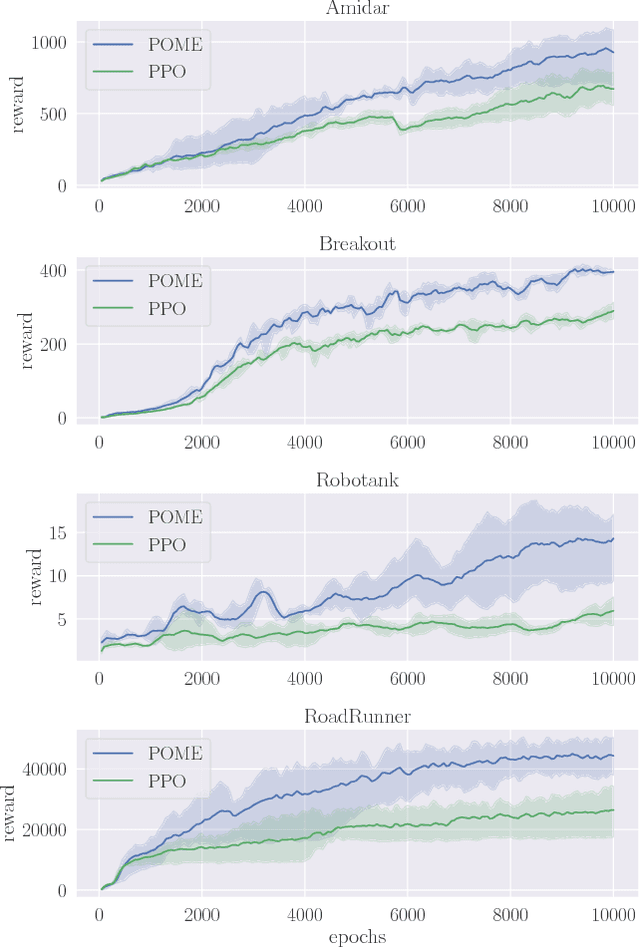
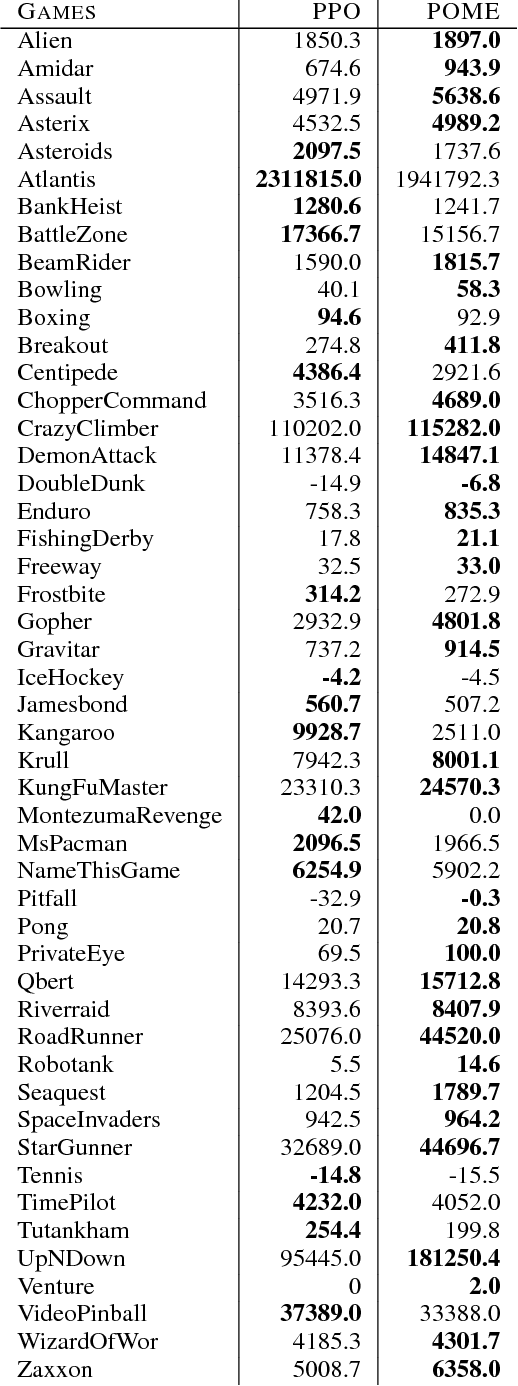
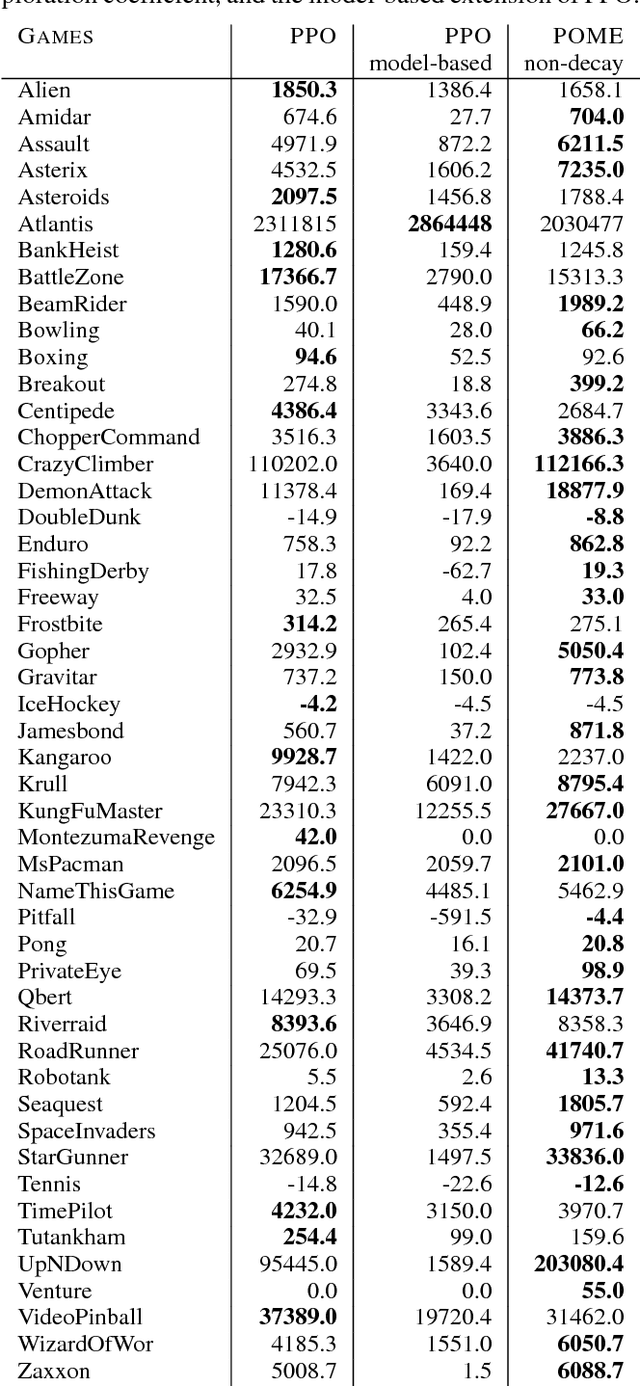
Model-free reinforcement learning methods such as the Proximal Policy Optimization algorithm (PPO) have successfully applied in complex decision-making problems such as Atari games. However, these methods suffer from high variances and high sample complexity. On the other hand, model-based reinforcement learning methods that learn the transition dynamics are more sample efficient, but they often suffer from the bias of the transition estimation. How to make use of both model-based and model-free learning is a central problem in reinforcement learning. In this paper, we present a new technique to address the trade-off between exploration and exploitation, which regards the difference between model-free and model-based estimations as a measure of exploration value. We apply this new technique to the PPO algorithm and arrive at a new policy optimization method, named Policy Optimization with Model-based Explorations (POME). POME uses two components to predict the actions' target values: a model-free one estimated by Monte-Carlo sampling and a model-based one which learns a transition model and predicts the value of the next state. POME adds the error of these two target estimations as the additional exploration value for each state-action pair, i.e, encourages the algorithm to explore the states with larger target errors which are hard to estimate. We compare POME with PPO on Atari 2600 games, and it shows that POME outperforms PPO on 33 games out of 49 games.
Speeding up the Metabolism in E-commerce by Reinforcement Mechanism Design
Jul 02, 2018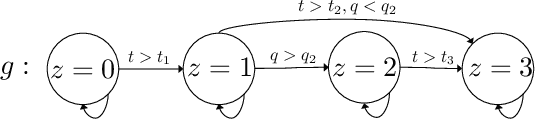

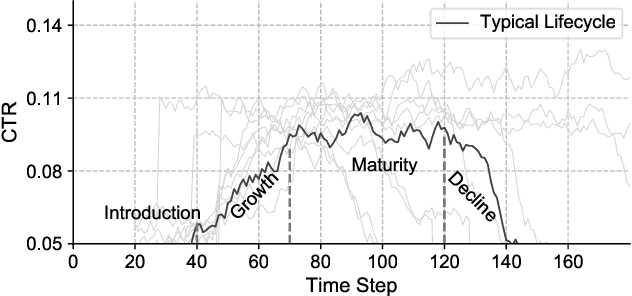
In a large E-commerce platform, all the participants compete for impressions under the allocation mechanism of the platform. Existing methods mainly focus on the short-term return based on the current observations instead of the long-term return. In this paper, we formally establish the lifecycle model for products, by defining the introduction, growth, maturity and decline stages and their transitions throughout the whole life period. Based on such model, we further propose a reinforcement learning based mechanism design framework for impression allocation, which incorporates the first principal component based permutation and the novel experiences generation method, to maximize short-term as well as long-term return of the platform. With the power of trial-and-error, it is possible to optimize impression allocation strategies globally which is contribute to the healthy development of participants and the platform itself. We evaluate our algorithm on a simulated environment built based on one of the largest E-commerce platforms, and a significant improvement has been achieved in comparison with the baseline solutions.
Virtual-Taobao: Virtualizing Real-world Online Retail Environment for Reinforcement Learning
May 25, 2018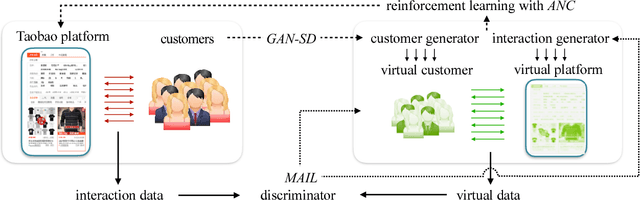
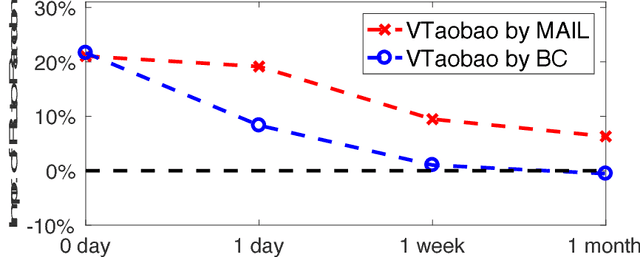
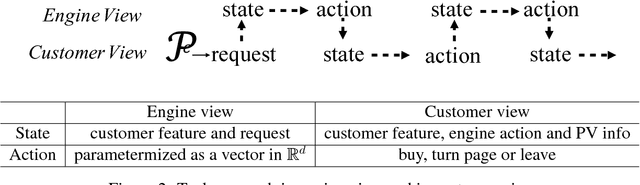

Applying reinforcement learning in physical-world tasks is extremely challenging. It is commonly infeasible to sample a large number of trials, as required by current reinforcement learning methods, in a physical environment. This paper reports our project on using reinforcement learning for better commodity search in Taobao, one of the largest online retail platforms and meanwhile a physical environment with a high sampling cost. Instead of training reinforcement learning in Taobao directly, we present our approach: first we build Virtual Taobao, a simulator learned from historical customer behavior data through the proposed GAN-SD (GAN for Simulating Distributions) and MAIL (multi-agent adversarial imitation learning), and then we train policies in Virtual Taobao with no physical costs in which ANC (Action Norm Constraint) strategy is proposed to reduce over-fitting. In experiments, Virtual Taobao is trained from hundreds of millions of customers' records, and its properties are compared with the real environment. The results disclose that Virtual Taobao faithfully recovers important properties of the real environment. We also show that the policies trained in Virtual Taobao can have significantly superior online performance to the traditional supervised approaches. We hope our work could shed some light on reinforcement learning applications in complex physical environments.