 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023



Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.
Self-Supervised Pre-training for 3D Point Clouds via View-Specific Point-to-Image Translation
Dec 29, 2022



The past few years have witnessed the prevalence of self-supervised representation learning within the language and 2D vision communities. However, such advancements have not been fully migrated to the community of 3D point cloud learning. Different from previous pre-training pipelines for 3D point clouds that generally fall into the scope of either generative modeling or contrastive learning, in this paper, we investigate a translative pre-training paradigm, namely PointVST, driven by a novel self-supervised pretext task of cross-modal translation from an input 3D object point cloud to its diverse forms of 2D rendered images (e.g., silhouette, depth, contour). Specifically, we begin with deducing view-conditioned point-wise embeddings via the insertion of the viewpoint indicator, and then adaptively aggregate a view-specific global codeword, which is further fed into the subsequent 2D convolutional translation heads for image generation. We conduct extensive experiments on common task scenarios of 3D shape analysis, where our PointVST shows consistent and prominent performance superiority over current state-of-the-art methods under diverse evaluation protocols. Our code will be made publicly available.
Flattening-Net: Deep Regular 2D Representation for 3D Point Cloud Analysis
Dec 17, 2022



Point clouds are characterized by irregularity and unstructuredness, which pose challenges in efficient data exploitation and discriminative feature extraction. In this paper, we present an unsupervised deep neural architecture called Flattening-Net to represent irregular 3D point clouds of arbitrary geometry and topology as a completely regular 2D point geometry image (PGI) structure, in which coordinates of spatial points are captured in colors of image pixels. \mr{Intuitively, Flattening-Net implicitly approximates a locally smooth 3D-to-2D surface flattening process while effectively preserving neighborhood consistency.} \mr{As a generic representation modality, PGI inherently encodes the intrinsic property of the underlying manifold structure and facilitates surface-style point feature aggregation.} To demonstrate its potential, we construct a unified learning framework directly operating on PGIs to achieve \mr{diverse types of high-level and low-level} downstream applications driven by specific task networks, including classification, segmentation, reconstruction, and upsampling. Extensive experiments demonstrate that our methods perform favorably against the current state-of-the-art competitors. We will make the code and data publicly available at https://github.com/keeganhk/Flattening-Net.
Leveraging Single-View Images for Unsupervised 3D Point Cloud Completion
Dec 01, 2022Point clouds captured by scanning devices are often incomplete due to occlusion. Point cloud completion aims to predict the complete shape based on its partial input. Existing methods can be classified into supervised and unsupervised methods. However, both of them require a large number of 3D complete point clouds, which are difficult to capture. In this paper, we propose Cross-PCC, an unsupervised point cloud completion method without requiring any 3D complete point clouds. We only utilize 2D images of the complete objects, which are easier to capture than 3D complete and clean point clouds. Specifically, to take advantage of the complementary information from 2D images, we use a single-view RGB image to extract 2D features and design a fusion module to fuse the 2D and 3D features extracted from the partial point cloud. To guide the shape of predicted point clouds, we project the predicted points of the object to the 2D plane and use the foreground pixels of its silhouette maps to constrain the position of the projected points. To reduce the outliers of the predicted point clouds, we propose a view calibrator to move the points projected to the background into the foreground by the single-view silhouette image. To the best of our knowledge, our approach is the first point cloud completion method that does not require any 3D supervision. The experimental results of our method are superior to those of the state-of-the-art unsupervised methods by a large margin. Moreover, compared to some supervised methods, our method achieves similar performance. We will make the source code publicly available at https://github.com/ltwu6/cross-pcc.
Multi-View Vision-to-Geometry Knowledge Transfer for 3D Point Cloud Shape Analysis
Jul 07, 2022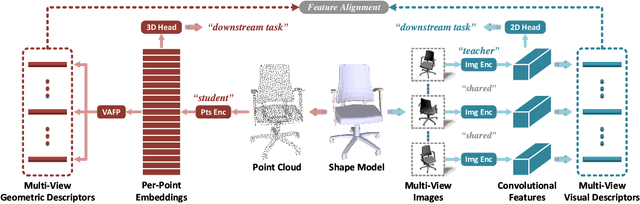
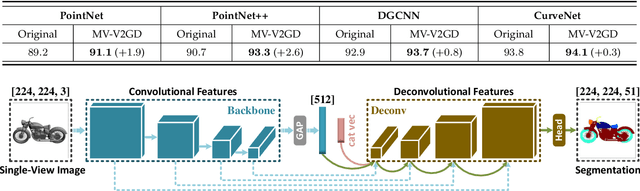


As two fundamental representation modalities of 3D objects, 2D multi-view images and 3D point clouds reflect shape information from different aspects of visual appearances and geometric structures. Unlike deep learning-based 2D multi-view image modeling, which demonstrates leading performances in various 3D shape analysis tasks, 3D point cloud-based geometric modeling still suffers from insufficient learning capacity. In this paper, we innovatively construct a unified cross-modal knowledge transfer framework, which distills discriminative visual descriptors of 2D images into geometric descriptors of 3D point clouds. Technically, under a classic teacher-student learning paradigm, we propose multi-view vision-to-geometry distillation, consisting of a deep 2D image encoder as teacher and a deep 3D point cloud encoder as student. To achieve heterogeneous feature alignment, we further propose visibility-aware feature projection, through which per-point embeddings can be aggregated into multi-view geometric descriptors. Extensive experiments on 3D shape classification, part segmentation, and unsupervised learning validate the superiority of our method. We will make the code and data publicly available.
GLENet: Boosting 3D Object Detectors with Generative Label Uncertainty Estimation
Jul 06, 2022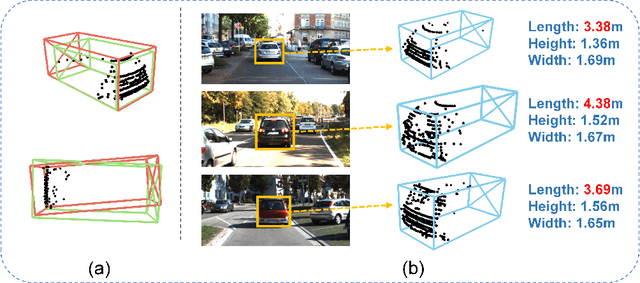
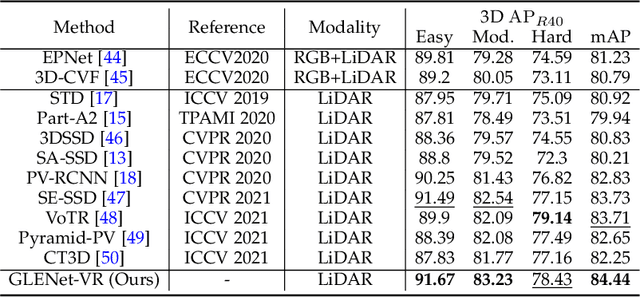
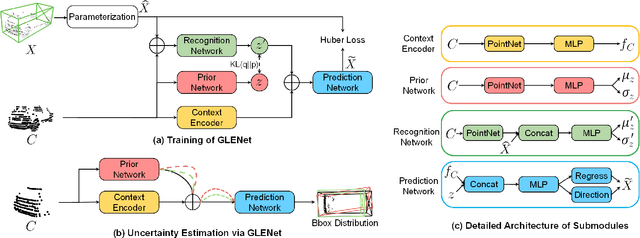
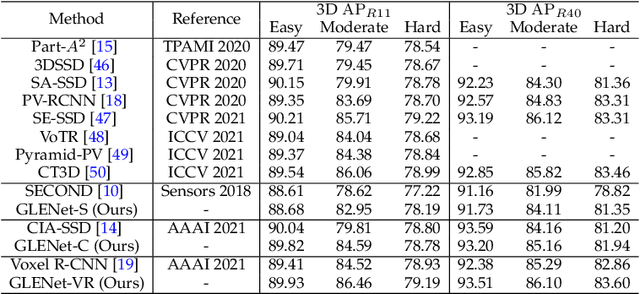
The inherent ambiguity in ground-truth annotations of 3D bounding boxes caused by occlusions, signal missing, or manual annotation errors can confuse deep 3D object detectors during training, thus deteriorating the detection accuracy. However, existing methods overlook such issues to some extent and treat the labels as deterministic. In this paper, we propose GLENet, a generative label uncertainty estimation framework adapted from conditional variational autoencoders, to model the one-to-many relationship between a typical 3D object and its potential ground-truth bounding boxes with latent variables. The label uncertainty generated by GLENet is a plug-and-play module and can be conveniently integrated into existing deep 3D detectors to build probabilistic detectors and supervise the learning of the localization uncertainty. Besides, we propose an uncertainty-aware quality estimator architecture in probabilistic detectors to guide the training of IoU-branch with predicted localization uncertainty. We incorporate the proposed methods into various popular base 3D detectors and observe that their performance is significantly boosted to the current state-of-the-art over the Waymo Open dataset and KITTI dataset.
WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
Mar 24, 2022We propose WarpingGAN, an effective and efficient 3D point cloud generation network. Unlike existing methods that generate point clouds by directly learning the mapping functions between latent codes and 3D shapes, Warping-GAN learns a unified local-warping function to warp multiple identical pre-defined priors (i.e., sets of points uniformly distributed on regular 3D grids) into 3D shapes driven by local structure-aware semantics. In addition, we also ingeniously utilize the principle of the discriminator and tailor a stitching loss to eliminate the gaps between different partitions of a generated shape corresponding to different priors for boosting quality. Owing to the novel generating mechanism, WarpingGAN, a single lightweight network after one-time training, is capable of efficiently generating uniformly distributed 3D point clouds with various resolutions. Extensive experimental results demonstrate the superiority of our WarpingGAN over state-of-the-art methods in terms of quantitative metrics, visual quality, and efficiency. The source code is publicly available at https://github.com/yztang4/WarpingGAN.git.
IDEA-Net: Dynamic 3D Point Cloud Interpolation via Deep Embedding Alignment
Mar 22, 2022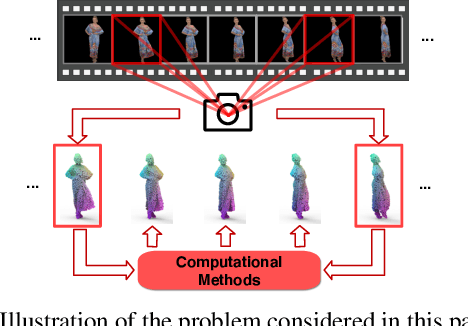
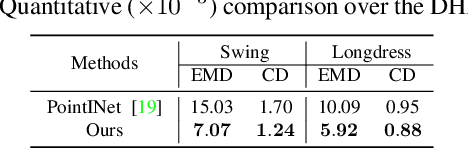
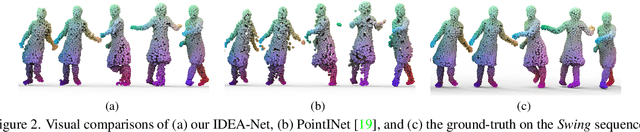
This paper investigates the problem of temporally interpolating dynamic 3D point clouds with large non-rigid deformation. We formulate the problem as estimation of point-wise trajectories (i.e., smooth curves) and further reason that temporal irregularity and under-sampling are two major challenges. To tackle the challenges, we propose IDEA-Net, an end-to-end deep learning framework, which disentangles the problem under the assistance of the explicitly learned temporal consistency. Specifically, we propose a temporal consistency learning module to align two consecutive point cloud frames point-wisely, based on which we can employ linear interpolation to obtain coarse trajectories/in-between frames. To compensate the high-order nonlinear components of trajectories, we apply aligned feature embeddings that encode local geometry properties to regress point-wise increments, which are combined with the coarse estimations. We demonstrate the effectiveness of our method on various point cloud sequences and observe large improvement over state-of-the-art methods both quantitatively and visually. Our framework can bring benefits to 3D motion data acquisition. The source code is publicly available at https://github.com/ZENGYIMING-EAMON/IDEA-Net.git.
ParaNet: Deep Regular Representation for 3D Point Clouds
Dec 05, 2020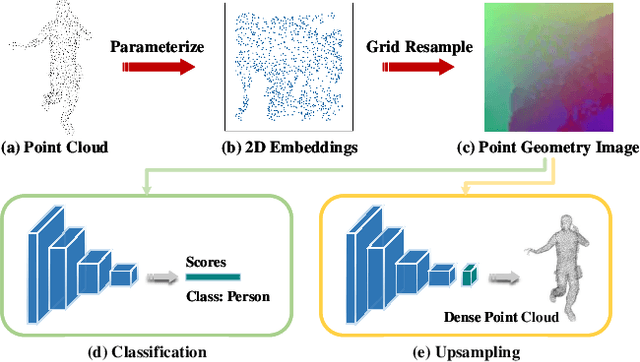
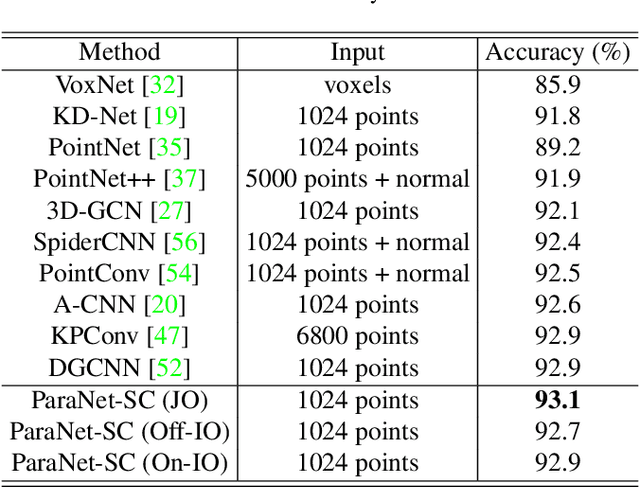
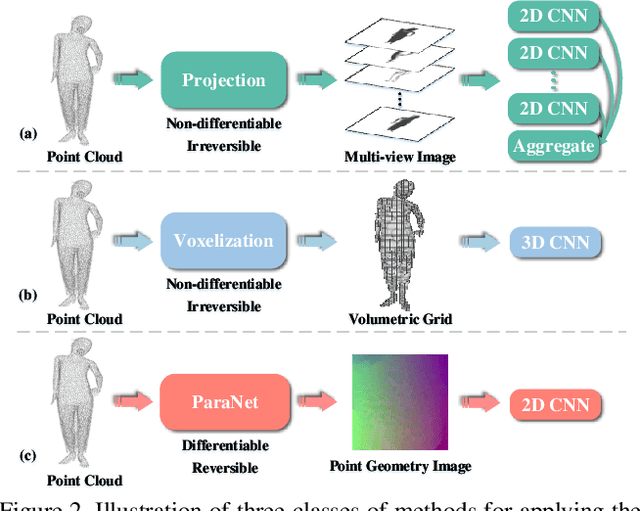

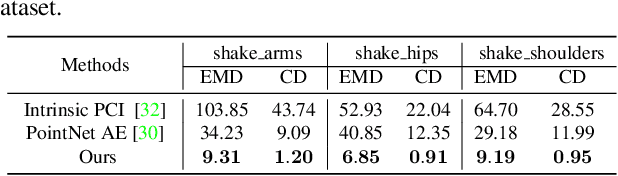
Although convolutional neural networks have achieved remarkable success in analyzing 2D images/videos, it is still non-trivial to apply the well-developed 2D techniques in regular domains to the irregular 3D point cloud data. To bridge this gap, we propose ParaNet, a novel end-to-end deep learning framework, for representing 3D point clouds in a completely regular and nearly lossless manner. To be specific, ParaNet converts an irregular 3D point cloud into a regular 2D color image, named point geometry image (PGI), where each pixel encodes the spatial coordinates of a point. In contrast to conventional regular representation modalities based on multi-view projection and voxelization, the proposed representation is differentiable and reversible. Technically, ParaNet is composed of a surface embedding module, which parameterizes 3D surface points onto a unit square, and a grid resampling module, which resamples the embedded 2D manifold over regular dense grids. Note that ParaNet is unsupervised, i.e., the training simply relies on reference-free geometry constraints. The PGIs can be seamlessly coupled with a task network established upon standard and mature techniques for 2D images/videos to realize a specific task for 3D point clouds. We evaluate ParaNet over shape classification and point cloud upsampling, in which our solutions perform favorably against the existing state-of-the-art methods. We believe such a paradigm will open up many possibilities to advance the progress of deep learning-based point cloud processing and understanding.
Dense Attention Fluid Network for Salient Object Detection in Optical Remote Sensing Images
Nov 26, 2020

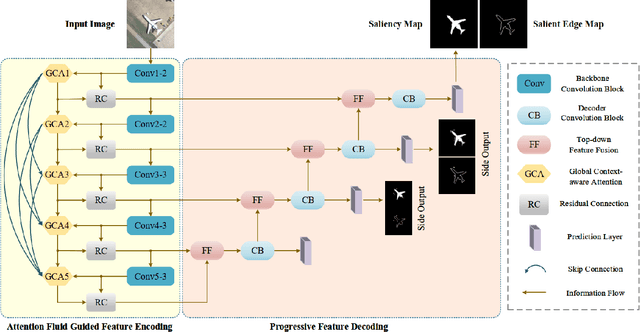
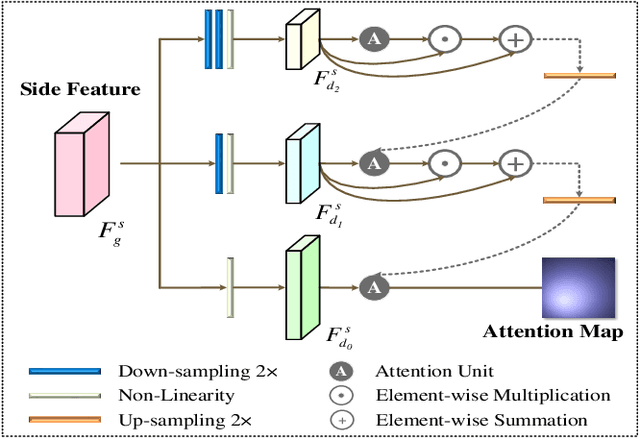
Despite the remarkable advances in visual saliency analysis for natural scene images (NSIs), salient object detection (SOD) for optical remote sensing images (RSIs) still remains an open and challenging problem. In this paper, we propose an end-to-end Dense Attention Fluid Network (DAFNet) for SOD in optical RSIs. A Global Context-aware Attention (GCA) module is proposed to adaptively capture long-range semantic context relationships, and is further embedded in a Dense Attention Fluid (DAF) structure that enables shallow attention cues flow into deep layers to guide the generation of high-level feature attention maps. Specifically, the GCA module is composed of two key components, where the global feature aggregation module achieves mutual reinforcement of salient feature embeddings from any two spatial locations, and the cascaded pyramid attention module tackles the scale variation issue by building up a cascaded pyramid framework to progressively refine the attention map in a coarse-to-fine manner. In addition, we construct a new and challenging optical RSI dataset for SOD that contains 2,000 images with pixel-wise saliency annotations, which is currently the largest publicly available benchmark. Extensive experiments demonstrate that our proposed DAFNet significantly outperforms the existing state-of-the-art SOD competitors. https://github.com/rmcong/DAFNet_TIP20