 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCut: A Spectral Analysis Framework for Reliable Detection of Byzantine Colluders
Nov 24, 2022



This paper proposes a general spectral analysis framework that thwarts a security risk in federated Learning caused by groups of malicious Byzantine attackers or colluders, who conspire to upload vicious model updates to severely debase global model performances. The proposed framework delineates the strong consistency and temporal coherence between Byzantine colluders' model updates from a spectral analysis lens, and, formulates the detection of Byzantine misbehaviours as a community detection problem in weighted graphs. The modified normalized graph cut is then utilized to discern attackers from benign participants. Moreover, the Spectral heuristics is adopted to make the detection robust against various attacks. The proposed Byzantine colluder resilient method, i.e., FedCut, is guaranteed to converge with bounded errors. Extensive experimental results under a variety of settings justify the superiority of FedCut, which demonstrates extremely robust model performance (MP) under various attacks. It was shown that FedCut's averaged MP is 2.1% to 16.5% better than that of the state of the art Byzantine-resilient methods. In terms of the worst-case model performance (MP), FedCut is 17.6% to 69.5% better than these methods.
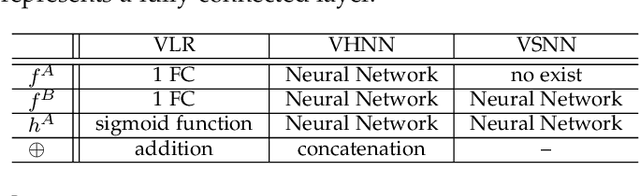
Vertical Federated Learning
Nov 24, 2022



Vertical Federated Learning (VFL) is a federated learning setting where multiple parties with different features about the same set of users jointly train machine learning models without exposing their raw data or model parameters. Motivated by the rapid growth in VFL research and real-world applications, we provide a comprehensive review of the concept and algorithms of VFL, as well as current advances and challenges in various aspects, including effectiveness, efficiency, and privacy. We provide an exhaustive categorization for VFL settings and privacy-preserving protocols and comprehensively analyze the privacy attacks and defense strategies for each protocol. In the end, we propose a unified framework, termed VFLow, which considers the VFL problem under communication, computation, privacy, and effectiveness constraints. Finally, we review the most recent advances in industrial applications, highlighting open challenges and future directions for VFL.
FedTracker: Furnishing Ownership Verification and Traceability for Federated Learning Model
Nov 14, 2022



Copyright protection of the Federated Learning (FL) model has become a major concern since malicious clients in FL can stealthily distribute or sell the FL model to other parties. In order to prevent such misbehavior, one must be able to catch the culprit by investigating trace evidence from the model in question. In this paper, we propose FedTracker, the first FL model protection framework that, on one hand, employs global watermarks to verify ownerships of the global model; and on the other hand, embed unique local fingerprints into respective local models to facilitate tracing the model back to the culprit. Furthermore, FedTracker introduces the intuition of Continual Learning (CL) into watermark embedding, and proposes a CL-based watermark mechanism to improve fidelity. Experimental results show that the proposed FedTracker is effective in ownership verification, traceability, fidelity, and robustness.
A Survey on Heterogeneous Federated Learning
Oct 10, 2022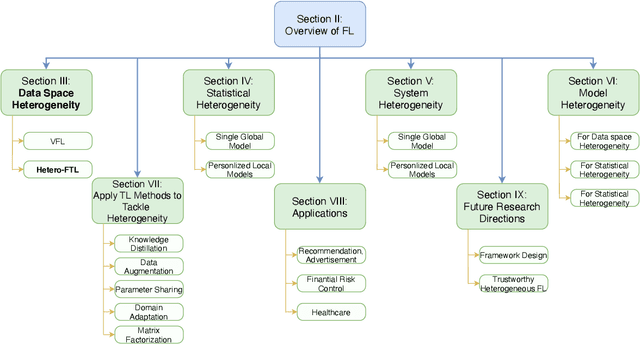
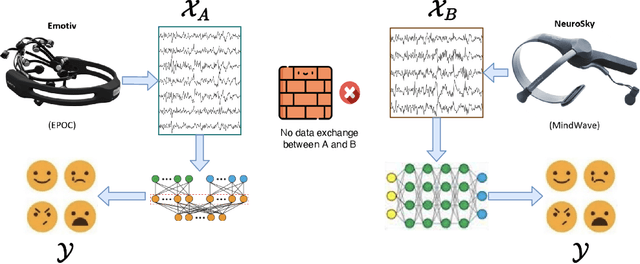
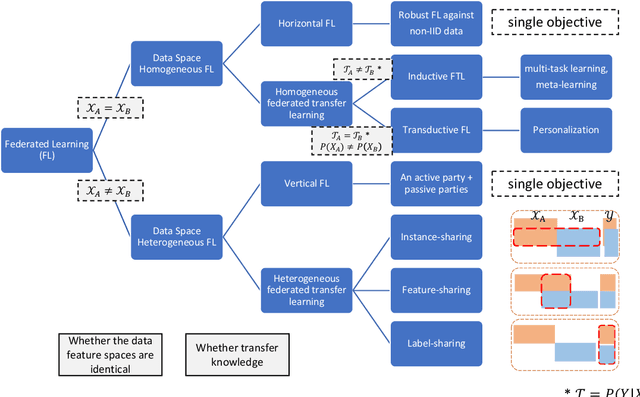
Federated learning (FL) has been proposed to protect data privacy and virtually assemble the isolated data silos by cooperatively training models among organizations without breaching privacy and security. However, FL faces heterogeneity from various aspects, including data space, statistical, and system heterogeneity. For example, collaborative organizations without conflict of interest often come from different areas and have heterogeneous data from different feature spaces. Participants may also want to train heterogeneous personalized local models due to non-IID and imbalanced data distribution and various resource-constrained devices. Therefore, heterogeneous FL is proposed to address the problem of heterogeneity in FL. In this survey, we comprehensively investigate the domain of heterogeneous FL in terms of data space, statistical, system, and model heterogeneity. We first give an overview of FL, including its definition and categorization. Then, We propose a precise taxonomy of heterogeneous FL settings for each type of heterogeneity according to the problem setting and learning objective. We also investigate the transfer learning methodologies to tackle the heterogeneity in FL. We further present the applications of heterogeneous FL. Finally, we highlight the challenges and opportunities and envision promising future research directions toward new framework design and trustworthy approaches.
A Framework for Evaluating Privacy-Utility Trade-off in Vertical Federated Learning
Sep 09, 2022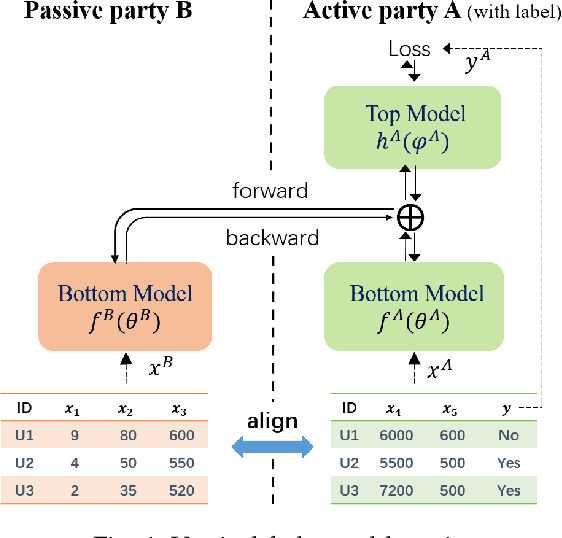

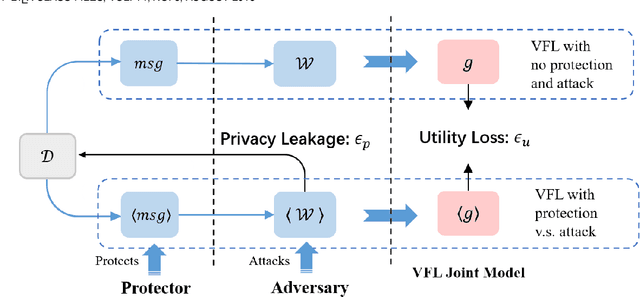
Federated learning (FL) has emerged as a practical solution to tackle data silo issues without compromising user privacy. One of its variants, vertical federated learning (VFL), has recently gained increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to build better machine learning models while preserving user privacy. Current works in VFL concentrate on developing a specific protection or attack mechanism for a particular VFL algorithm. In this work, we propose an evaluation framework that formulates the privacy-utility evaluation problem. We then use this framework as a guide to comprehensively evaluate a broad range of protection mechanisms against most of the state-of-the-art privacy attacks for three widely-deployed VFL algorithms. These evaluations may help FL practitioners select appropriate protection mechanisms given specific requirements. Our evaluation results demonstrate that: the model inversion and most of the label inference attacks can be thwarted by existing protection mechanisms; the model completion (MC) attack is difficult to be prevented, which calls for more advanced MC-targeted protection mechanisms. Based on our evaluation results, we offer concrete advice on improving the privacy-preserving capability of VFL systems.
Cross-domain Cross-architecture Black-box Attacks on Fine-tuned Models with Transferred Evolutionary Strategies
Aug 28, 2022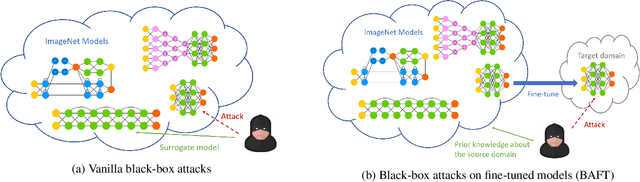
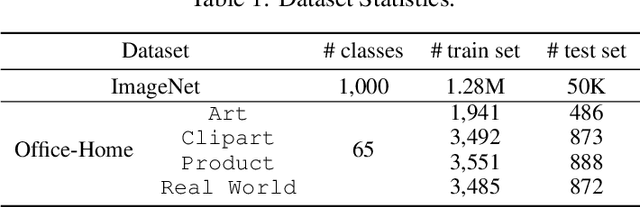
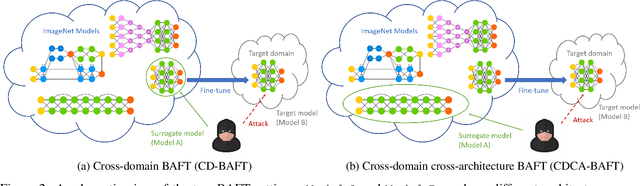

Fine-tuning can be vulnerable to adversarial attacks. Existing works about black-box attacks on fine-tuned models (BAFT) are limited by strong assumptions. To fill the gap, we propose two novel BAFT settings, cross-domain and cross-domain cross-architecture BAFT, which only assume that (1) the target model for attacking is a fine-tuned model, and (2) the source domain data is known and accessible. To successfully attack fine-tuned models under both settings, we propose to first train an adversarial generator against the source model, which adopts an encoder-decoder architecture and maps a clean input to an adversarial example. Then we search in the low-dimensional latent space produced by the encoder of the adversarial generator. The search is conducted under the guidance of the surrogate gradient obtained from the source model. Experimental results on different domains and different network architectures demonstrate that the proposed attack method can effectively and efficiently attack the fine-tuned models.
A Hybrid Self-Supervised Learning Framework for Vertical Federated Learning
Aug 18, 2022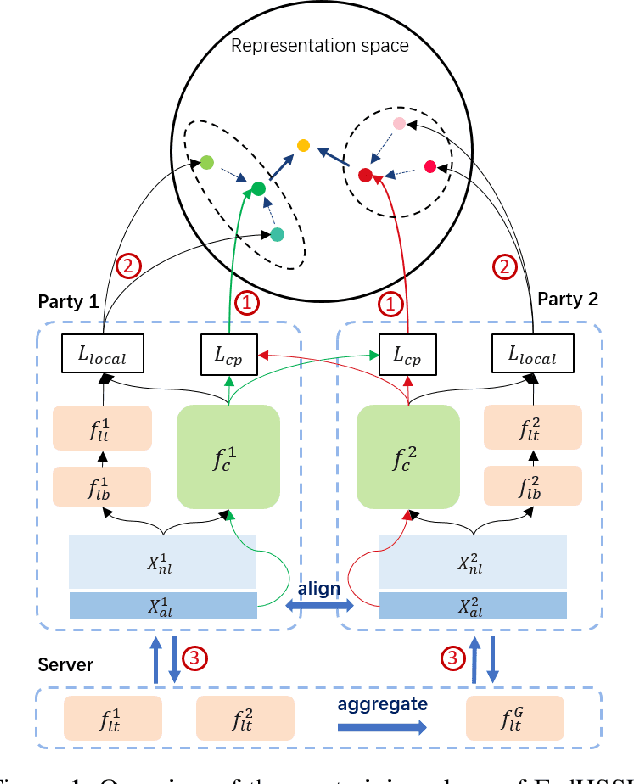

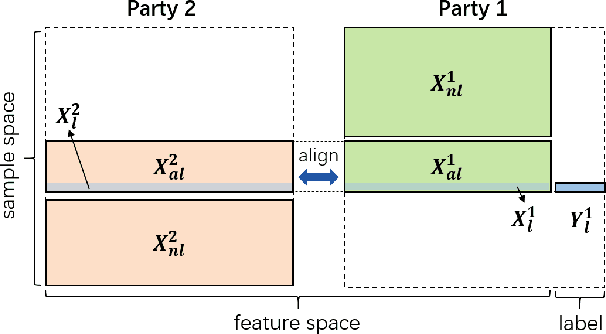
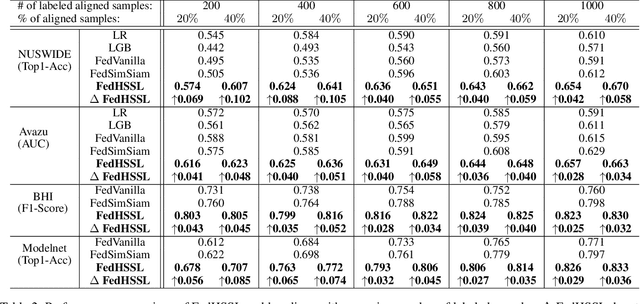
Federated learning (FL) enables independent parties to collaboratively build machine learning (ML) models while protecting data privacy. Vertical federated learning (VFL), a variant of FL, has recently drawn increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to achieve better model performance without jeopardizing data privacy. However, conventional VFL may run into data deficiency as it is only able to exploit aligned samples (belonging to different parties) with labels, leaving often the majority of unaligned and unlabeled samples unused. The data deficiency hampers the effort of the federation. In this work, we propose a Federated Hybrid Self-Supervised Learning framework, coined FedHSSL, to utilize all available data (including unaligned and unlabeled samples) of participants to train the joint VFL model. The core idea of FedHSSL is to utilize cross-party views (i.e., dispersed features) of samples aligned among parties and local views (i.e., augmentations) of samples within each party to improve the representation learning capability of the joint VFL model through SSL (e.g., SimSiam). FedHSSL further exploits generic features shared among parties to boost the performance of the joint model through partial model aggregation. We empirically demonstrate that our FedHSSL achieves significant performance gains compared with baseline methods, especially when the number of labeled samples is small. We provide an in-depth analysis of FedHSSL regarding privacy leakage, which is rarely discussed in existing self-supervised VFL works. We investigate the protection mechanism for FedHSSL. The results show our protection can thwart the state-of-the-art label inference attack.
An Efficient Industrial Federated Learning Framework for AIoT: A Face Recognition Application
Jun 30, 2022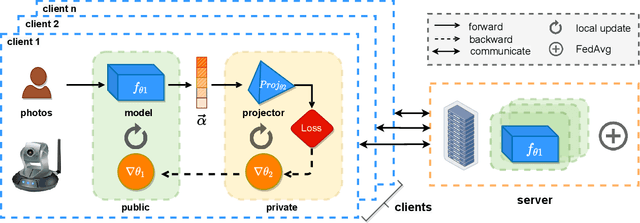



Recently, the artificial intelligence of things (AIoT) has been gaining increasing attention, with an intriguing vision of providing highly intelligent services through the network connection of things, leading to an advanced AI-driven ecology. However, recent regulatory restrictions on data privacy preclude uploading sensitive local data to data centers and utilizing them in a centralized approach. Directly applying federated learning algorithms in this scenario could hardly meet the industrial requirements of both efficiency and accuracy. Therefore, we propose an efficient industrial federated learning framework for AIoT in terms of a face recognition application. Specifically, we propose to utilize the concept of transfer learning to speed up federated training on devices and further present a novel design of a private projector that helps protect shared gradients without incurring additional memory consumption or computational cost. Empirical studies on a private Asian face dataset show that our approach can achieve high recognition accuracy in only 20 communication rounds, demonstrating its effectiveness in prediction and its efficiency in training.
WrapperFL: A Model Agnostic Plug-in for Industrial Federated Learning
Jun 21, 2022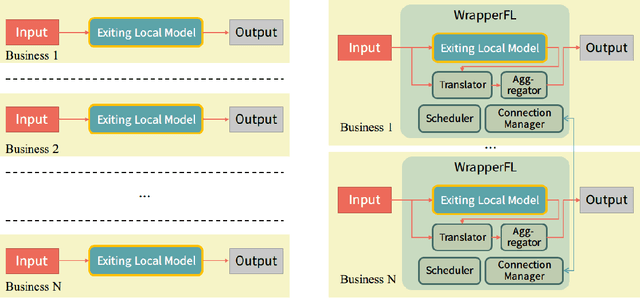

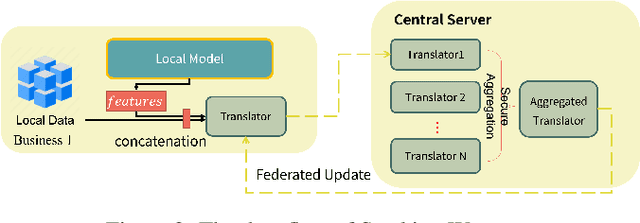

Federated learning, as a privacy-preserving collaborative machine learning paradigm, has been gaining more and more attention in the industry. With the huge rise in demand, there have been many federated learning platforms that allow federated participants to set up and build a federated model from scratch. However, exiting platforms are highly intrusive, complicated, and hard to integrate with built machine learning models. For many real-world businesses that already have mature serving models, existing federated learning platforms have high entry barriers and development costs. This paper presents a simple yet practical federated learning plug-in inspired by ensemble learning, dubbed WrapperFL, allowing participants to build/join a federated system with existing models at minimal costs. The WrapperFL works in a plug-and-play way by simply attaching to the input and output interfaces of an existing model, without the need of re-development, significantly reducing the overhead of manpower and resources. We verify our proposed method on diverse tasks under heterogeneous data distributions and heterogeneous models. The experimental results demonstrate that WrapperFL can be successfully applied to a wide range of applications under practical settings and improves the local model with federated learning at a low cost.
FadMan: Federated Anomaly Detection across Multiple Attributed Networks
May 27, 2022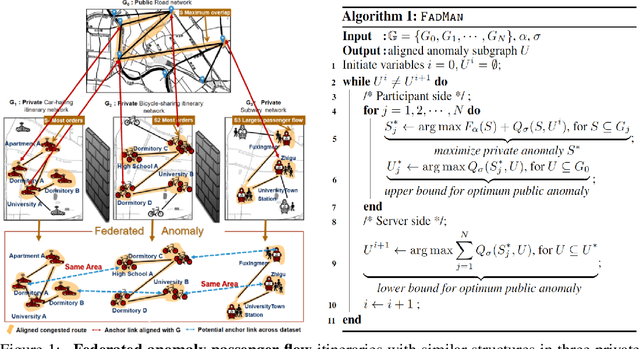
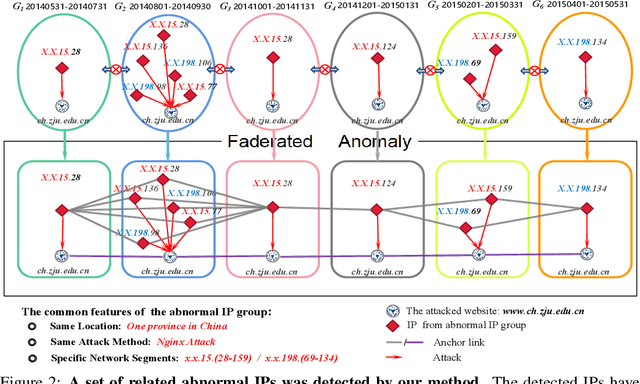
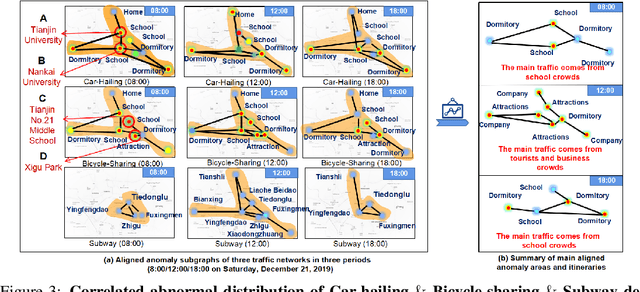
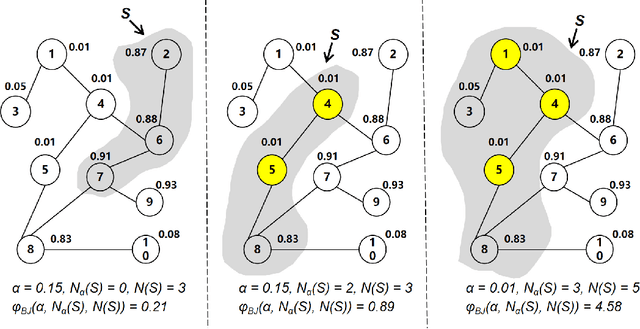
Anomaly subgraph detection has been widely used in various applications, ranging from cyber attack in computer networks to malicious activities in social networks. Despite an increasing need for federated anomaly detection across multiple attributed networks, only a limited number of approaches are available for this problem. Federated anomaly detection faces two major challenges. One is that isolated data in most industries are restricted share with others for data privacy and security. The other is most of the centralized approaches training based on data integration. The main idea of federated anomaly detection is aligning private anomalies from local data owners on the public anomalies from the attributed network in the server through public anomalies to federate local anomalies. In each private attributed network, the detected anomaly subgraph is aligned with an anomaly subgraph in the public attributed network. The significant public anomaly subgraphs are selected for federated private anomalies while preventing local private data leakage. The proposed algorithm FadMan is a vertical federated learning framework for public node aligned with many private nodes of different features, and is validated on two tasks correlated anomaly detection on multiple attributed networks and anomaly detection on an attributeless network using five real-world datasets. In the first scenario, FadMan outperforms competitive methods by at least 12% accuracy at 10% noise level. In the second scenario, by analyzing the distribution of abnormal nodes, we find that the nodes of traffic anomalies are associated with the event of postgraduate entrance examination on the same day.