 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks with Low-rank Learnable Local Filters
Aug 04, 2020
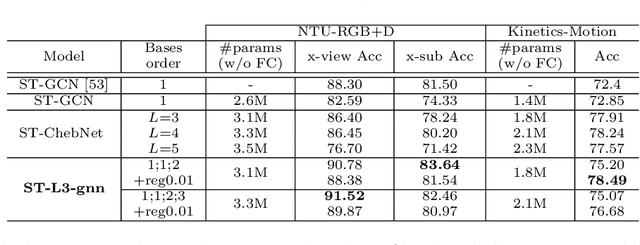
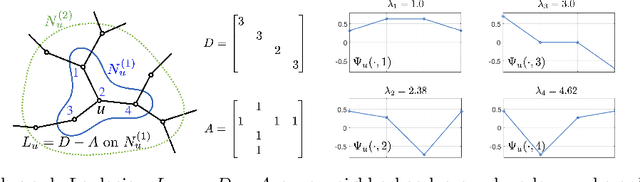
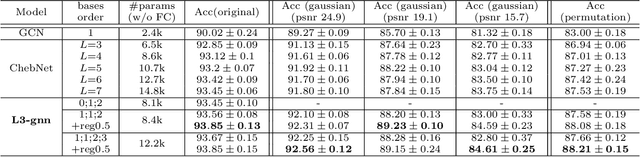
For the classification of graph data consisting of features sampled on an irregular coarse mesh like landmark points on face and human body, graph neural network (gnn) models based on global graph Laplacians may lack expressiveness to capture local features on graph. The current paper introduces a new gnn layer type with learnable low-rank local graph filters, which significantly reduces the complexity of traditional locally connected gnn. The architecture provides a unified framework for both spectral and spatial convolutional gnn constructions. The new gnn layer is provably more expressive than gnn based on global graph Laplacians, and to improve model robustness, regularization by local graph Laplacians is introduced. The representation stability against input graph data perturbation is theoretically proved, making use of the graph filter locality and the local graph regularization. Experiments on spherical mesh data, real-world facial expression recognition/skeleton-based action recognition data, and data with simulated graph noise show the empirical advantage of the proposed model.
Learning to Learn with Variational Information Bottleneck for Domain Generalization
Jul 15, 2020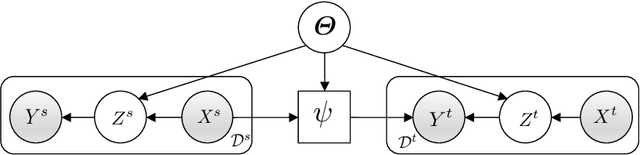
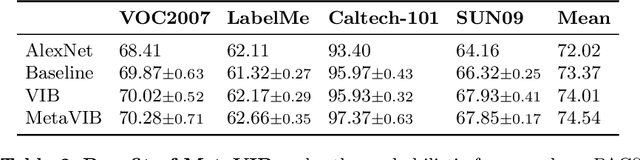

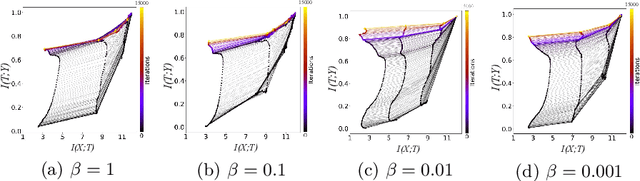
Domain generalization models learn to generalize to previously unseen domains, but suffer from prediction uncertainty and domain shift. In this paper, we address both problems. We introduce a probabilistic meta-learning model for domain generalization, in which classifier parameters shared across domains are modeled as distributions. This enables better handling of prediction uncertainty on unseen domains. To deal with domain shift, we learn domain-invariant representations by the proposed principle of meta variational information bottleneck, we call MetaVIB. MetaVIB is derived from novel variational bounds of mutual information, by leveraging the meta-learning setting of domain generalization. Through episodic training, MetaVIB learns to gradually narrow domain gaps to establish domain-invariant representations, while simultaneously maximizing prediction accuracy. We conduct experiments on three benchmarks for cross-domain visual recognition. Comprehensive ablation studies validate the benefits of MetaVIB for domain generalization. The comparison results demonstrate our method outperforms previous approaches consistently.
Low to High Dimensional Modality Hallucination using Aggregated Fields of View
Jul 13, 2020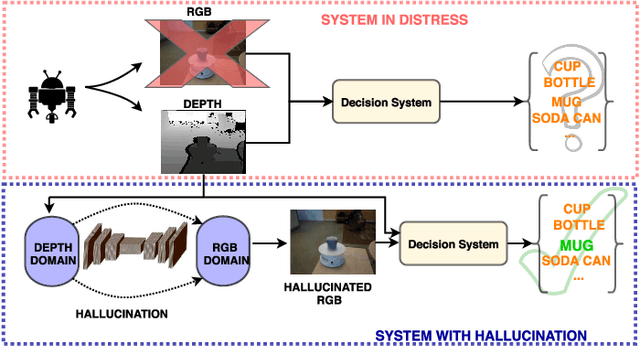



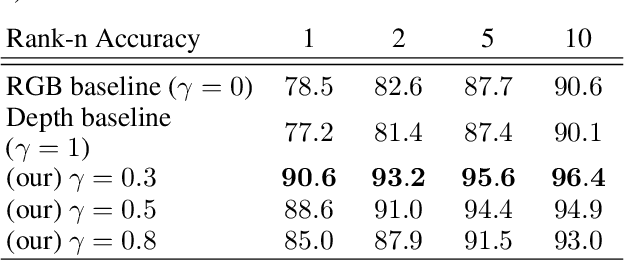
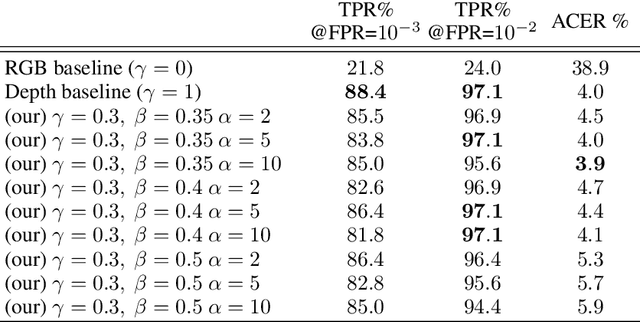
Real-world robotics systems deal with data from a multitude of modalities, especially for tasks such as navigation and recognition. The performance of those systems can drastically degrade when one or more modalities become inaccessible, due to factors such as sensors' malfunctions or adverse environments. Here, we argue modality hallucination as one effective way to ensure consistent modality availability and thereby reduce unfavorable consequences. While hallucinating data from a modality with richer information, e.g., RGB to depth, has been researched extensively, we investigate the more challenging low-to-high modality hallucination with interesting use cases in robotics and autonomous systems. We present a novel hallucination architecture that aggregates information from multiple fields of view of the local neighborhood to recover the lost information from the extant modality. The process is implemented by capturing a non-linear mapping between the data modalities and the learned mapping is used to aid the extant modality to mitigate the risk posed to the system in the adverse scenarios which involve modality loss. We also conduct extensive classification and segmentation experiments on UWRGBD and NYUD datasets and demonstrate that hallucination allays the negative effects of the modality loss. Implementation and models: https://github.com/kausic94/Hallucination
Differential 3D Facial Recognition: Adding 3D to Your State-of-the-Art 2D Method
Apr 03, 2020
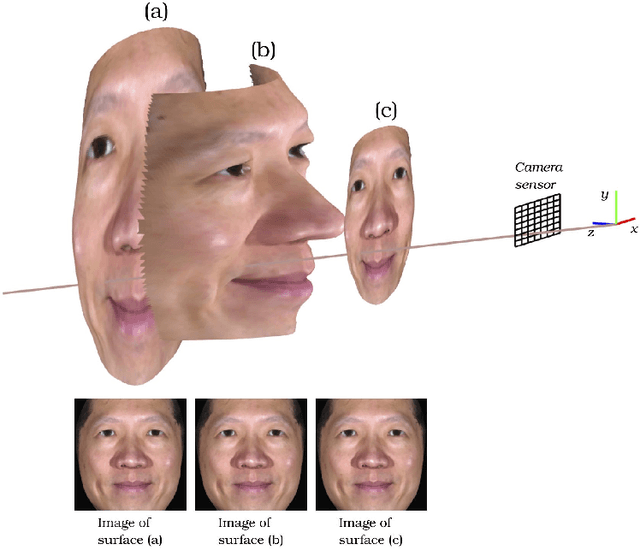
Active illumination is a prominent complement to enhance 2D face recognition and make it more robust, e.g., to spoofing attacks and low-light conditions. In the present work we show that it is possible to adopt active illumination to enhance state-of-the-art 2D face recognition approaches with 3D features, while bypassing the complicated task of 3D reconstruction. The key idea is to project over the test face a high spatial frequency pattern, which allows us to simultaneously recover real 3D information plus a standard 2D facial image. Therefore, state-of-the-art 2D face recognition solution can be transparently applied, while from the high frequency component of the input image, complementary 3D facial features are extracted. Experimental results on ND-2006 dataset show that the proposed ideas can significantly boost face recognition performance and dramatically improve the robustness to spoofing attacks.
SalGaze: Personalizing Gaze Estimation Using Visual Saliency
Oct 23, 2019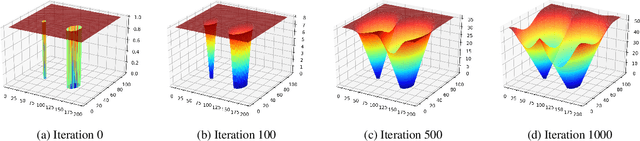
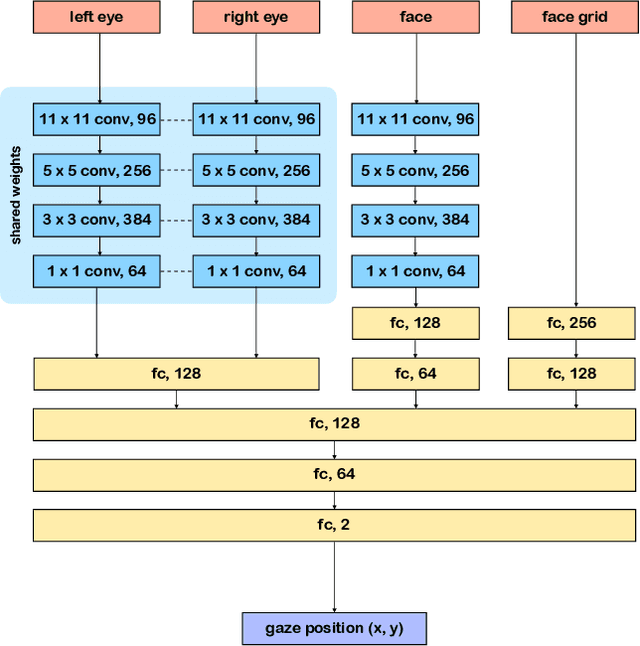
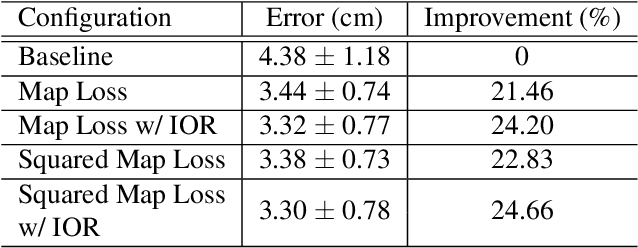
Traditional gaze estimation methods typically require explicit user calibration to achieve high accuracy. This process is cumbersome and recalibration is often required when there are changes in factors such as illumination and pose. To address this challenge, we introduce SalGaze, a framework that utilizes saliency information in the visual content to transparently adapt the gaze estimation algorithm to the user without explicit user calibration. We design an algorithm to transform a saliency map into a differentiable loss map that can be used for the optimization of CNN-based models. SalGaze is also able to greatly augment standard point calibration data with implicit video saliency calibration data using a unified framework. We show accuracy improvements over 24% using our technique on existing methods.
Range Adaptation for 3D Object Detection in LiDAR
Sep 26, 2019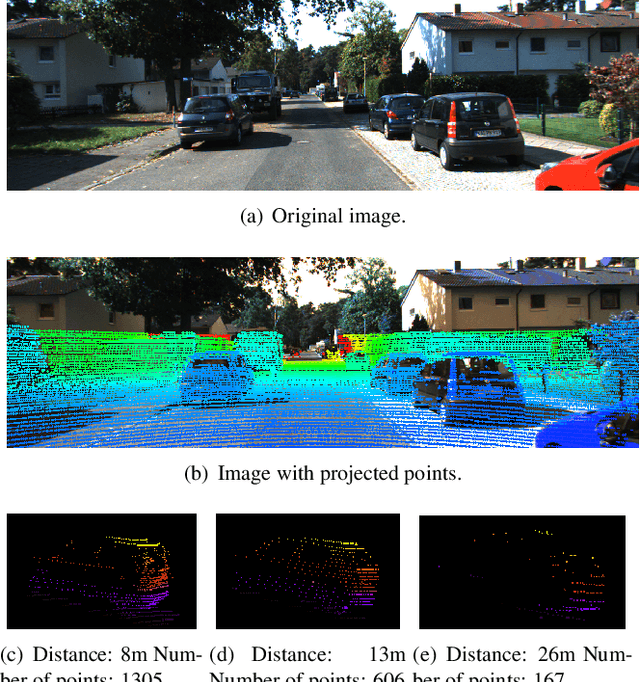
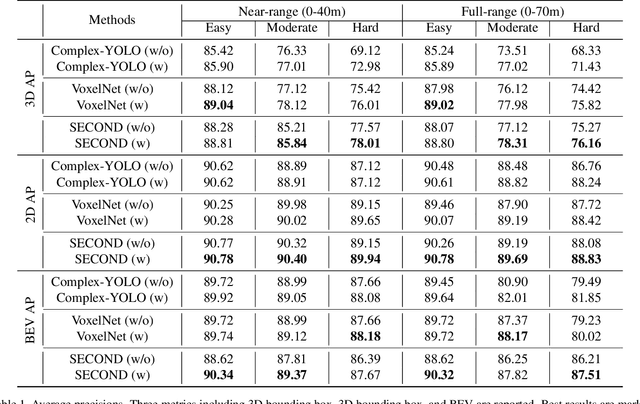
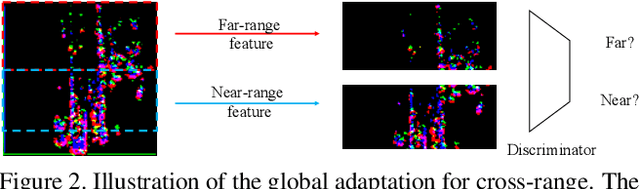

LiDAR-based 3D object detection plays a crucial role in modern autonomous driving systems. LiDAR data often exhibit severe changes in properties across different observation ranges. In this paper, we explore cross-range adaptation for 3D object detection using LiDAR, i.e., far-range observations are adapted to near-range. This way, far-range detection is optimized for similar performance to near-range one. We adopt a bird-eyes view (BEV) detection framework to perform the proposed model adaptation. Our model adaptation consists of an adversarial global adaptation, and a fine-grained local adaptation. The proposed cross range adaptation framework is validated on three state-of-the-art LiDAR based object detection networks, and we consistently observe performance improvement on the far-range objects, without adding any auxiliary parameters to the model. To the best of our knowledge, this paper is the first attempt to study cross-range LiDAR adaptation for object detection in point clouds. To demonstrate the generality of the proposed adaptation framework, experiments on more challenging cross-device adaptation are further conducted, and a new LiDAR dataset with high-quality annotated point clouds is released to promote future research.
Stochastic Conditional Generative Networks with Basis Decomposition
Sep 25, 2019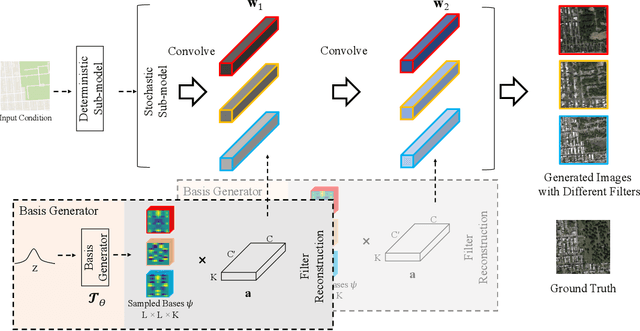
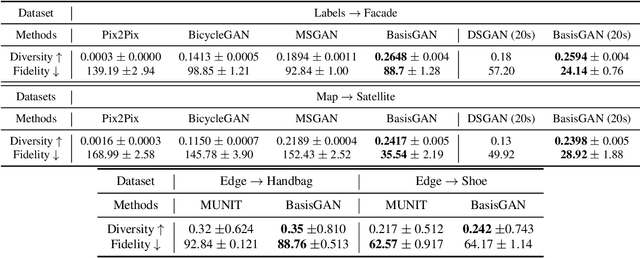


While generative adversarial networks (GANs) have revolutionized machine learning, a number of open questions remain to fully understand them and exploit their power. One of these questions is how to efficiently achieve proper diversity and sampling of the multi-mode data space. To address this, we introduce BasisGAN, a stochastic conditional multi-mode image generator. By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we learn a plug-and-played basis generator to stochastically generate basis elements, with just a few hundred of parameters, to fully embed stochasticity into convolutional filters. By sampling basis elements instead of filters, we dramatically reduce the cost of modeling the parameter space with no sacrifice on either image diversity or fidelity. To illustrate this proposed plug-and-play framework, we construct variants of BasisGAN based on state-of-the-art conditional image generation networks, and train the networks by simply plugging in a basis generator, without additional auxiliary components, hyperparameters, or training objectives. The experimental success is complemented with theoretical results indicating how the perturbations introduced by the proposed sampling of basis elements can propagate to the appearance of generated images.
Domain-invariant Learning using Adaptive Filter Decomposition
Sep 25, 2019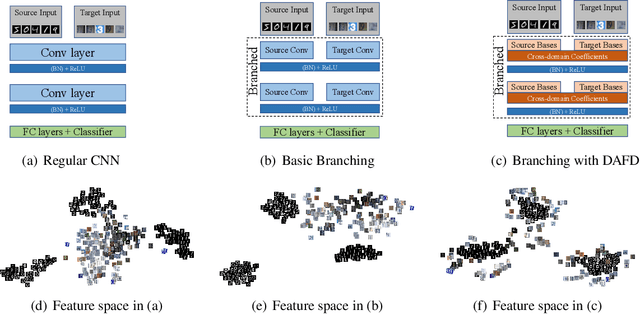
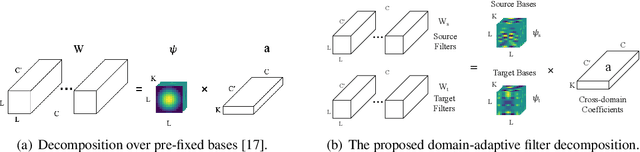

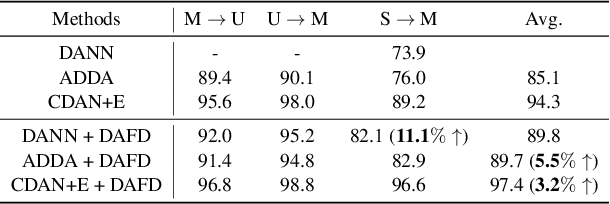
Domain shifts are frequently encountered in real-world scenarios. In this paper, we consider the problem of domain-invariant deep learning by explicitly modeling domain shifts with only a small amount of domain-specific parameters in a Convolutional Neural Network (CNN). By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we show for the first time, both empirically and theoretically, that domain shifts can be effectively handled by decomposing a regular convolutional layer into a domain-specific basis layer and a domain-shared basis coefficient layer, while both remain convolutional. An input channel will now first convolve spatially only with each respective domain-specific basis to "absorb" domain variations, and then output channels are linearly combined using common basis coefficients trained to promote shared semantics across domains. We use toy examples, rigorous analysis, and real-world examples to show the framework's effectiveness in cross-domain performance and domain adaptation. With the proposed architecture, we need only a small set of basis elements to model each additional domain, which brings a negligible amount of additional parameters, typically a few hundred.
Scale-Equivariant Neural Networks with Decomposed Convolutional Filters
Sep 24, 2019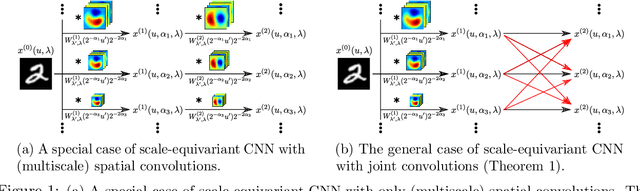
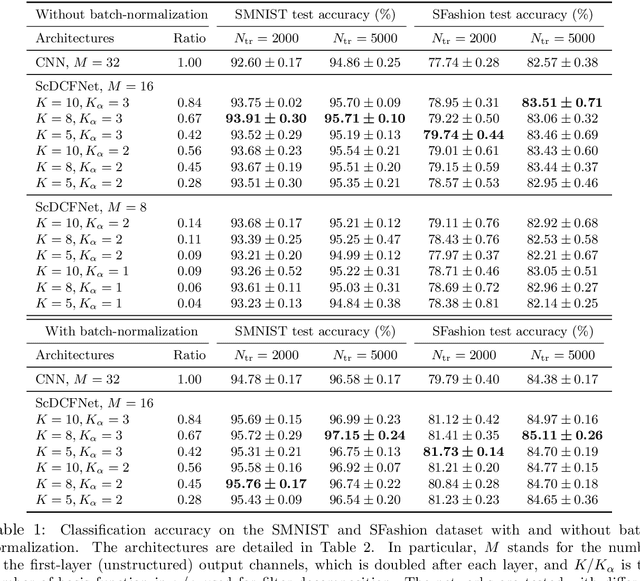
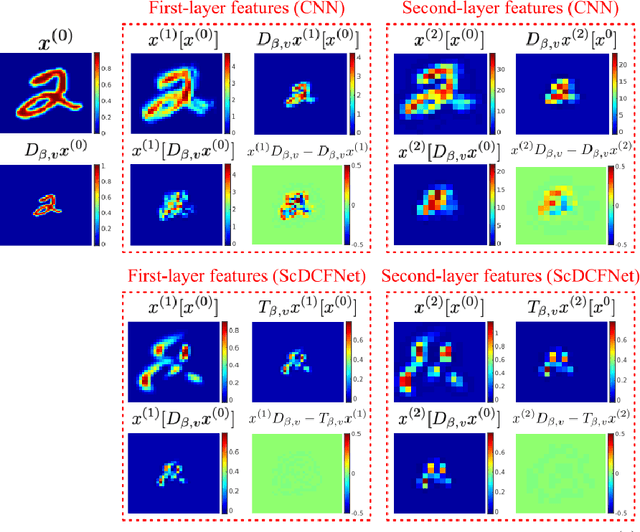
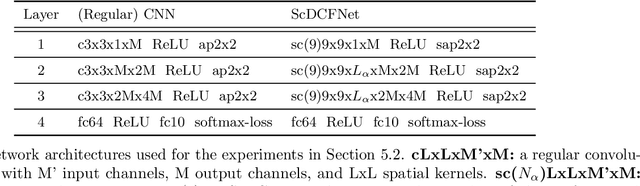
Encoding the input scale information explicitly into the representation learned by a convolutional neural network (CNN) is beneficial for many vision tasks especially when dealing with multiscale input signals. We study, in this paper, a scale-equivariant CNN architecture with joint convolutions across the space and the scaling group, which is shown to be both sufficient and necessary to achieve scale-equivariant representations. To reduce the model complexity and computational burden, we decompose the convolutional filters under two pre-fixed separable bases and truncate the expansion to low-frequency components. A further benefit of the truncated filter expansion is the improved deformation robustness of the equivariant representation. Numerical experiments demonstrate that the proposed scale-equivariant neural network with decomposed convolutional filters (ScDCFNet) achieves significantly improved performance in multiscale image classification and better interpretability than regular CNNs at a reduced model size.
Single-shot 3D shape reconstruction using deep convolutional neural networks
Sep 17, 2019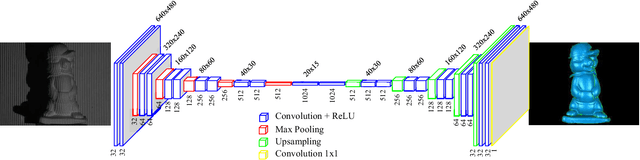
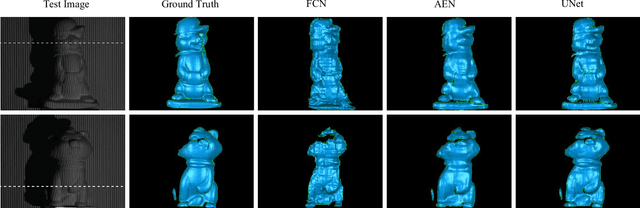
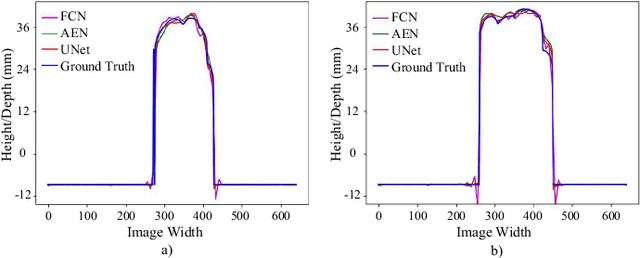

A robust single-shot 3D shape reconstruction technique integrating the fringe projection profilometry (FPP) technique with the deep convolutional neural networks (CNNs) is proposed in this letter. The input of the proposed technique is a single FPP image, and the training and validation data sets are prepared by using the conventional multi-frequency FPP technique. Unlike the conventional 3D shape reconstruction methods which involve complex algorithms and intensive computation, the proposed approach uses an end-to-end network architecture to directly carry out the transformation of a 2D images to its corresponding 3D shape. Experiments have been conducted to demonstrate the validity and robustness of the proposed technique. It is capable of satisfying various 3D shape reconstruction demands in scientific research and engineering applications.