 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Accurate and Accessible Markerless Neuronavigation
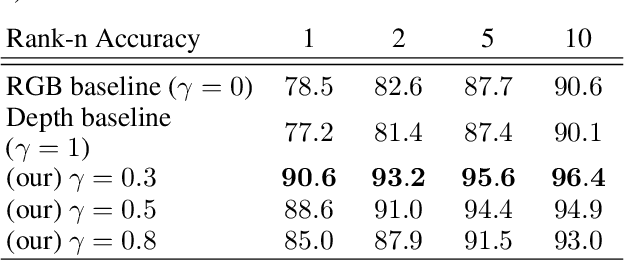
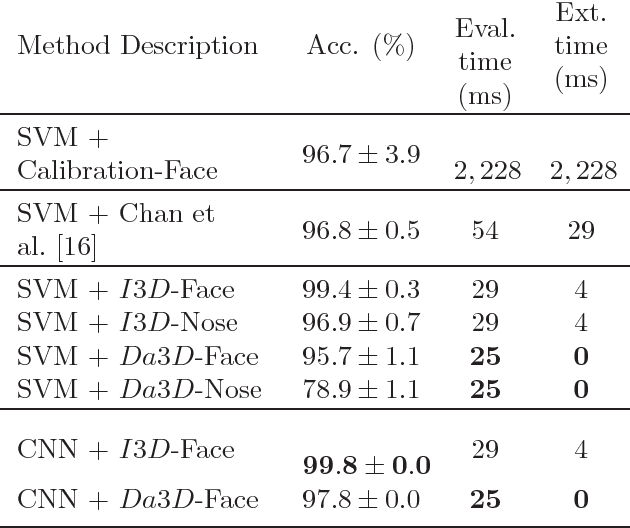
Feb 04, 2026Neuronavigation is widely used in biomedical research and interventions to guide the precise placement of instruments around the head to support procedures such as transcranial magnetic stimulation. Traditional systems, however, rely on subject-mounted markers that require manual registration, may shift during procedures, and can cause discomfort. We introduce and evaluate markerless approaches that replace expensive hardware and physical markers with low-cost visible and infrared light cameras incorporating stereo and depth sensing combined with algorithmic modeling of the facial geometry. Validation with $50$ human subjects yielded a median tracking discrepancy of only $2.32$ mm and $2.01°$ for the best markerless algorithms compared to a conventional marker-based system, which indicates sufficient accuracy for transcranial magnetic stimulation and a substantial improvement over prior markerless results. The results suggest that integration of the data from the various camera sensors can improve the overall accuracy further. The proposed markerless neuronavigation methods can reduce setup cost and complexity, improve patient comfort, and expand access to neuronavigation in clinical and research settings.
Chain-of-Image Generation: Toward Monitorable and Controllable Image Generation
Dec 09, 2025While state-of-the-art image generation models achieve remarkable visual quality, their internal generative processes remain a "black box." This opacity limits human observation and intervention, and poses a barrier to ensuring model reliability, safety, and control. Furthermore, their non-human-like workflows make them difficult for human observers to interpret. To address this, we introduce the Chain-of-Image Generation (CoIG) framework, which reframes image generation as a sequential, semantic process analogous to how humans create art. Similar to the advantages in monitorability and performance that Chain-of-Thought (CoT) brought to large language models (LLMs), CoIG can produce equivalent benefits in text-to-image generation. CoIG utilizes an LLM to decompose a complex prompt into a sequence of simple, step-by-step instructions. The image generation model then executes this plan by progressively generating and editing the image. Each step focuses on a single semantic entity, enabling direct monitoring. We formally assess this property using two novel metrics: CoIG Readability, which evaluates the clarity of each intermediate step via its corresponding output; and Causal Relevance, which quantifies the impact of each procedural step on the final generated image. We further show that our framework mitigates entity collapse by decomposing the complex generation task into simple subproblems, analogous to the procedural reasoning employed by CoT. Our experimental results indicate that CoIG substantially enhances quantitative monitorability while achieving competitive compositional robustness compared to established baseline models. The framework is model-agnostic and can be integrated with any image generation model.
SPOT: Sparsification with Attention Dynamics via Token Relevance in Vision Transformers
Nov 13, 2025



While Vision Transformers (ViT) have demonstrated remarkable performance across diverse tasks, their computational demands are substantial, scaling quadratically with the number of processed tokens. Compact attention representations, reflecting token interaction distributions, can guide early detection and reduction of less salient tokens prior to attention computation. Motivated by this, we present SParsification with attentiOn dynamics via Token relevance (SPOT), a framework for early detection of redundant tokens within ViTs that leverages token embeddings, interactions, and attention dynamics across layers to infer token importance, resulting in a more context-aware and interpretable relevance detection process. SPOT informs token sparsification and facilitates the elimination of such tokens, improving computational efficiency without sacrificing performance. SPOT employs computationally lightweight predictors that can be plugged into various ViT architectures and learn to derive effective input-specific token prioritization across layers. Its versatile design supports a range of performance levels adaptable to varying resource constraints. Empirical evaluations demonstrate significant efficiency gains of up to 40% compared to standard ViTs, while maintaining or even improving accuracy. Code and models are available at https://github.com/odedsc/SPOT .
Differential 3D Facial Recognition: Adding 3D to Your State-of-the-Art 2D Method
Apr 03, 2020
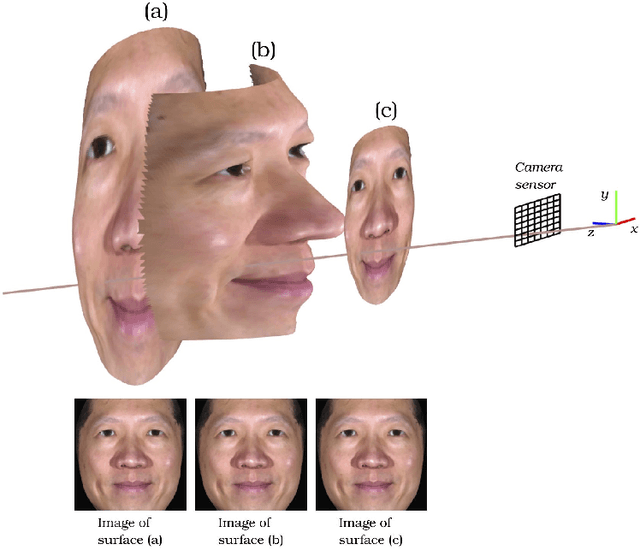
Active illumination is a prominent complement to enhance 2D face recognition and make it more robust, e.g., to spoofing attacks and low-light conditions. In the present work we show that it is possible to adopt active illumination to enhance state-of-the-art 2D face recognition approaches with 3D features, while bypassing the complicated task of 3D reconstruction. The key idea is to project over the test face a high spatial frequency pattern, which allows us to simultaneously recover real 3D information plus a standard 2D facial image. Therefore, state-of-the-art 2D face recognition solution can be transparently applied, while from the high frequency component of the input image, complementary 3D facial features are extracted. Experimental results on ND-2006 dataset show that the proposed ideas can significantly boost face recognition performance and dramatically improve the robustness to spoofing attacks.
Liveness Detection Using Implicit 3D Features
Apr 19, 2018


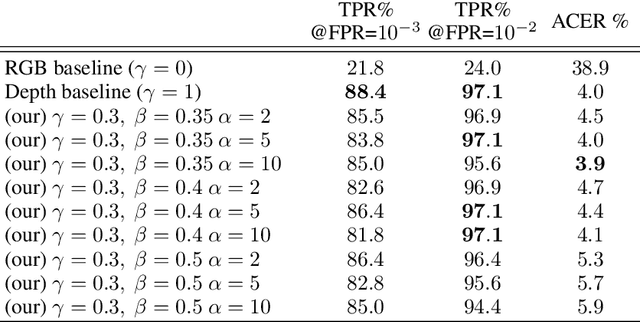
Spoofing attacks are a threat to modern face recognition systems. In this work we present a simple yet effective liveness detection approach to enhance 2D face recognition methods and make them robust against spoofing attacks. We show that the risk to spoofing attacks can be re- duced through the use of an additional source of light, for example a flash. From a pair of input images taken under different illumination, we define discriminative features that implicitly contain facial three-dimensional in- formation. Furthermore, we show that when multiple sources of light are considered, we are able to validate which one has been activated. This makes possible the design of a highly secure active-light authentication framework. Finally, further investigating the use of 3D features without 3D reconstruction, we introduce an approximated disparity-based implicit 3D feature obtained from an uncalibrated stereo-pair of cameras. Valida- tion experiments show that the proposed methods produce state-of-the-art results in challenging scenarios with nearly no feature extraction latency.