 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
Mar 18, 2026Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
SalGaze: Personalizing Gaze Estimation Using Visual Saliency
Oct 23, 2019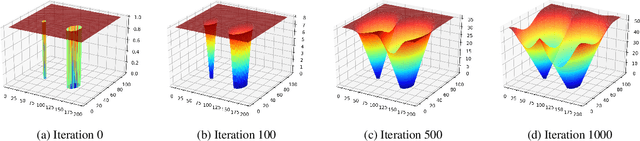
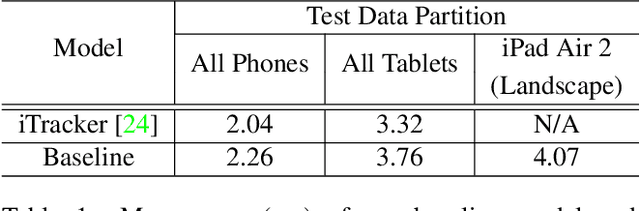
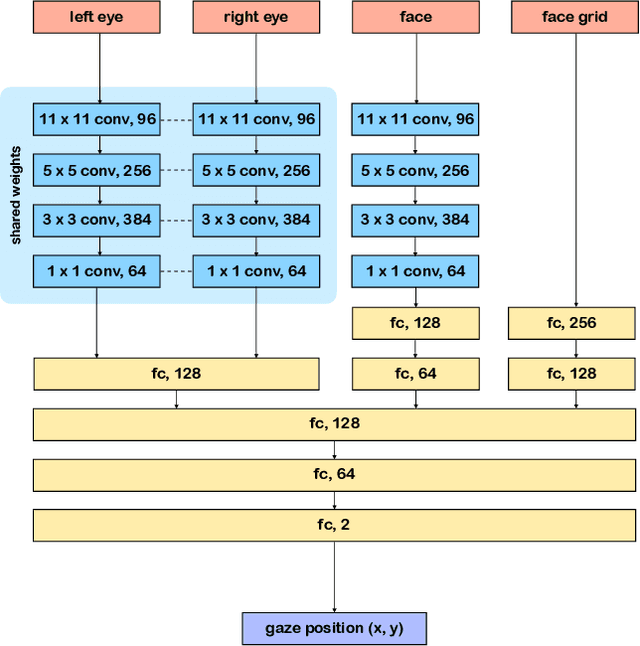
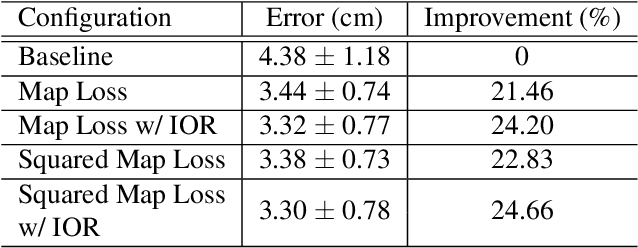
Traditional gaze estimation methods typically require explicit user calibration to achieve high accuracy. This process is cumbersome and recalibration is often required when there are changes in factors such as illumination and pose. To address this challenge, we introduce SalGaze, a framework that utilizes saliency information in the visual content to transparently adapt the gaze estimation algorithm to the user without explicit user calibration. We design an algorithm to transform a saliency map into a differentiable loss map that can be used for the optimization of CNN-based models. SalGaze is also able to greatly augment standard point calibration data with implicit video saliency calibration data using a unified framework. We show accuracy improvements over 24% using our technique on existing methods.