 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable Intelligent Surface-Enabled Array Radar for Interference Mitigation
Jan 28, 2024



Conventional active array radars often jointly design the transmit and receive beamforming for effectively suppressing interferences. To further promote the interference suppression performance, this paper introduces a reconfigurable intelligent surface (RIS) to assist the radar receiver because the RIS has the ability to bring plentiful additional degrees-of-freedom. To maximize the output signal-to-interference-plus-noise ratio (SINR) of receive array, we formulate the codesign of transmit beamforming and RIS-assisted receive beamforming into a nonconvex constrained fractional programming problem, and then propose an alternating minimization-based algorithm to jointly optimize the transmitor beamfmer, receive beamformer and RIS reflection coefficients. Concretely, we translate the RIS reflection coefficients design into a series of unimodular quadratic programming (UQP) subproblems by employing the Dinkelbach transform, and offer the closed-form optimal solutions of transmit and receive beamformers according to the minimum variance distortionless response principle. To tackle the UQP subproblems efficiently, we propose a second-order Riemannian Newton method (RNM) with improved Riemannian Newton direction, which avoids the line search and has better convergence speed than typical first-order Riemannian manifold optimization methods. Moreover, we derive the convergence of the proposed codesign algorithm by deducing the explicit convergence condition of RNM. We also analyze the computational complexity. Numerical results demonstrate that the proposed RIS-assisted array radar has superior performance of interference suppression to the RIS-free one, and the SINR improvement is proportional to the number of RIS elements.
Reflected Schrödinger Bridge for Constrained Generative Modeling
Jan 06, 2024



Diffusion models have become the go-to method for large-scale generative models in real-world applications. These applications often involve data distributions confined within bounded domains, typically requiring ad-hoc thresholding techniques for boundary enforcement. Reflected diffusion models (Lou23) aim to enhance generalizability by generating the data distribution through a backward process governed by reflected Brownian motion. However, reflected diffusion models may not easily adapt to diverse domains without the derivation of proper diffeomorphic mappings and do not guarantee optimal transport properties. To overcome these limitations, we introduce the Reflected Schrodinger Bridge algorithm: an entropy-regularized optimal transport approach tailored for generating data within diverse bounded domains. We derive elegant reflected forward-backward stochastic differential equations with Neumann and Robin boundary conditions, extend divergence-based likelihood training to bounded domains, and explore natural connections to entropic optimal transport for the study of approximate linear convergence - a valuable insight for practical training. Our algorithm yields robust generative modeling in diverse domains, and its scalability is demonstrated in real-world constrained generative modeling through standard image benchmarks.
Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability
Sep 30, 2023



Language learners should regularly engage in reading challenging materials as part of their study routine. Nevertheless, constantly referring to dictionaries is time-consuming and distracting. This paper presents a novel gaze-driven sentence simplification system designed to enhance reading comprehension while maintaining their focus on the content. Our system incorporates machine learning models tailored to individual learners, combining eye gaze features and linguistic features to assess sentence comprehension. When the system identifies comprehension difficulties, it provides simplified versions by replacing complex vocabulary and grammar with simpler alternatives via GPT-3.5. We conducted an experiment with 19 English learners, collecting data on their eye movements while reading English text. The results demonstrated that our system is capable of accurately estimating sentence-level comprehension. Additionally, we found that GPT-3.5 simplification improved readability in terms of traditional readability metrics and individual word difficulty, paraphrasing across different linguistic levels.
Pointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue
Sep 19, 2023



Effective communication between humans and intelligent agents has promising applications for solving complex problems. One such approach is visual dialogue, which leverages multimodal context to assist humans. However, real-world scenarios occasionally involve human mistakes, which can cause intelligent agents to fail. While most prior research assumes perfect answers from human interlocutors, we focus on a setting where the agent points out unintentional mistakes for the interlocutor to review, better reflecting real-world situations. In this paper, we show that human answer mistakes depend on question type and QA turn in the visual dialogue by analyzing a previously unused data collection of human mistakes. We demonstrate the effectiveness of those factors for the model's accuracy in a pointing-human-mistake task through experiments using a simple MLP model and a Visual Language Model.
Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation
Aug 24, 2023



Pre-captured immersive environments using omnidirectional cameras provide a wide range of virtual reality applications. Previous research has shown that manipulating the eye height in egocentric virtual environments can significantly affect distance perception and immersion. However, the influence of eye height in pre-captured real environments has received less attention due to the difficulty of altering the perspective after finishing the capture process. To explore this influence, we first propose a pilot study that captures real environments with multiple eye heights and asks participants to judge the egocentric distances and immersion. If a significant influence is confirmed, an effective image-based approach to adapt pre-captured real-world environments to the user's eye height would be desirable. Motivated by the study, we propose a learning-based approach for synthesizing novel views for omnidirectional images with altered eye heights. This approach employs a multitask architecture that learns depth and semantic segmentation in two formats, and generates high-quality depth and semantic segmentation to facilitate the inpainting stage. With the improved omnidirectional-aware layered depth image, our approach synthesizes natural and realistic visuals for eye height adaptation. Quantitative and qualitative evaluation shows favorable results against state-of-the-art methods, and an extensive user study verifies improved perception and immersion for pre-captured real-world environments.
Improving the Gap in Visual Speech Recognition Between Normal and Silent Speech Based on Metric Learning
May 23, 2023



This paper presents a novel metric learning approach to address the performance gap between normal and silent speech in visual speech recognition (VSR). The difference in lip movements between the two poses a challenge for existing VSR models, which exhibit degraded accuracy when applied to silent speech. To solve this issue and tackle the scarcity of training data for silent speech, we propose to leverage the shared literal content between normal and silent speech and present a metric learning approach based on visemes. Specifically, we aim to map the input of two speech types close to each other in a latent space if they have similar viseme representations. By minimizing the Kullback-Leibler divergence of the predicted viseme probability distributions between and within the two speech types, our model effectively learns and predicts viseme identities. Our evaluation demonstrates that our method improves the accuracy of silent VSR, even when limited training data is available.
The 7th AI City Challenge
Apr 15, 2023



The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Deep Signature Algorithm for Path-Dependent American option pricing
Nov 21, 2022



In this work, we study the deep signature algorithms for path-dependent FBSDEs with reflections. We follow the backward scheme in [Hur\'e-Pham-Warin. Mathematics of Computation 89, no. 324 (2020)] for state-dependent FBSDEs with reflections, and combine it with the signature layer to solve American type option pricing problems while the payoff function depends on the whole paths of the underlying forward stock process. We prove the convergence analysis of our numerical algorithm and provide numerical example for Amerasian option under the Black-Scholes model.
Non-reversible Parallel Tempering for Deep Posterior Approximation
Nov 20, 2022



Parallel tempering (PT), also known as replica exchange, is the go-to workhorse for simulations of multi-modal distributions. The key to the success of PT is to adopt efficient swap schemes. The popular deterministic even-odd (DEO) scheme exploits the non-reversibility property and has successfully reduced the communication cost from $O(P^2)$ to $O(P)$ given sufficiently many $P$ chains. However, such an innovation largely disappears in big data due to the limited chains and few bias-corrected swaps. To handle this issue, we generalize the DEO scheme to promote non-reversibility and propose a few solutions to tackle the underlying bias caused by the geometric stopping time. Notably, in big data scenarios, we obtain an appealing communication cost $O(P\log P)$ based on the optimal window size. In addition, we also adopt stochastic gradient descent (SGD) with large and constant learning rates as exploration kernels. Such a user-friendly nature enables us to conduct approximation tasks for complex posteriors without much tuning costs.
Efficient CNN Architecture Design Guided by Visualization
Jul 21, 2022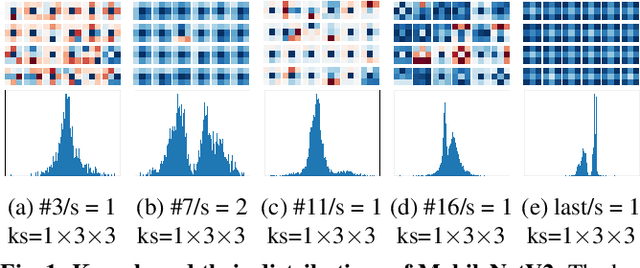
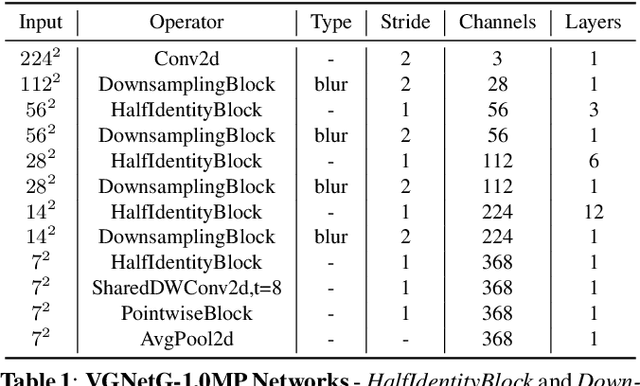


Modern efficient Convolutional Neural Networks(CNNs) always use Depthwise Separable Convolutions(DSCs) and Neural Architecture Search(NAS) to reduce the number of parameters and the computational complexity. But some inherent characteristics of networks are overlooked. Inspired by visualizing feature maps and N$\times$N(N$>$1) convolution kernels, several guidelines are introduced in this paper to further improve parameter efficiency and inference speed. Based on these guidelines, our parameter-efficient CNN architecture, called \textit{VGNetG}, achieves better accuracy and lower latency than previous networks with about 30%$\thicksim$50% parameters reduction. Our VGNetG-1.0MP achieves 67.7% top-1 accuracy with 0.99M parameters and 69.2% top-1 accuracy with 1.14M parameters on ImageNet classification dataset. Furthermore, we demonstrate that edge detectors can replace learnable depthwise convolution layers to mix features by replacing the N$\times$N kernels with fixed edge detection kernels. And our VGNetF-1.5MP archives 64.4%(-3.2%) top-1 accuracy and 66.2%(-1.4%) top-1 accuracy with additional Gaussian kernels.