 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Explainability: Towards Social Transparency in AI systems
Jan 12, 2021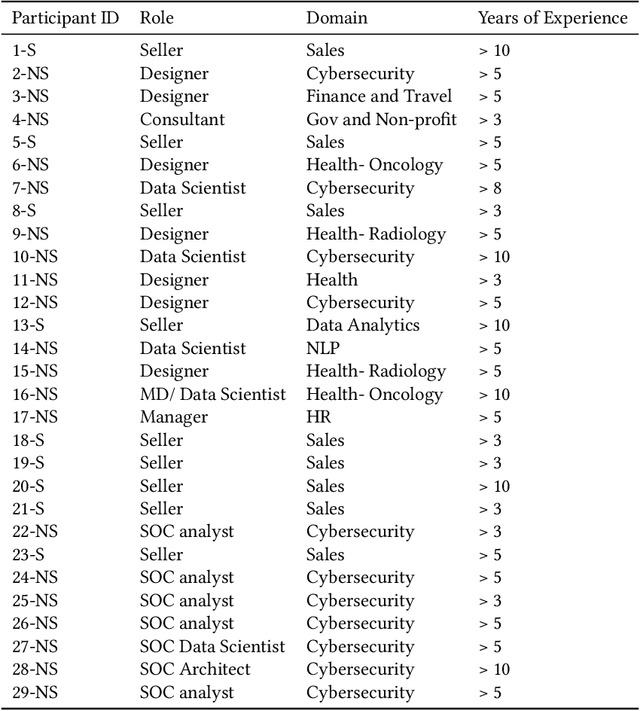
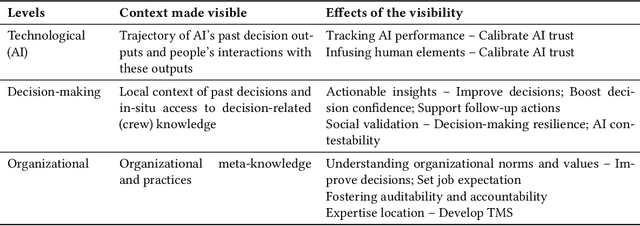

As AI-powered systems increasingly mediate consequential decision-making, their explainability is critical for end-users to take informed and accountable actions. Explanations in human-human interactions are socially-situated. AI systems are often socio-organizationally embedded. However, Explainable AI (XAI) approaches have been predominantly algorithm-centered. We take a developmental step towards socially-situated XAI by introducing and exploring Social Transparency (ST), a sociotechnically informed perspective that incorporates the socio-organizational context into explaining AI-mediated decision-making. To explore ST conceptually, we conducted interviews with 29 AI users and practitioners grounded in a speculative design scenario. We suggested constitutive design elements of ST and developed a conceptual framework to unpack ST's effect and implications at the technical, decision-making, and organizational level. The framework showcases how ST can potentially calibrate trust in AI, improve decision-making, facilitate organizational collective actions, and cultivate holistic explainability. Our work contributes to the discourse of Human-Centered XAI by expanding the design space of XAI.
How Much Automation Does a Data Scientist Want?
Jan 07, 2021

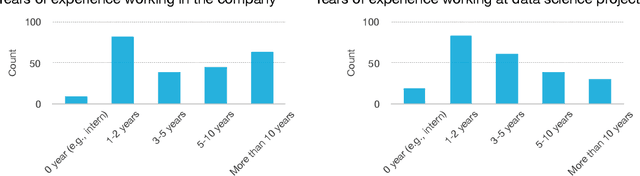
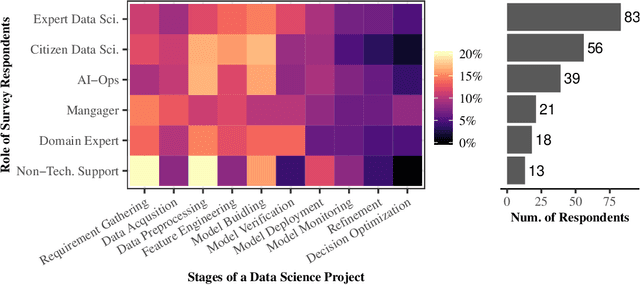
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.
Uncertainty as a Form of Transparency: Measuring, Communicating, and Using Uncertainty
Nov 15, 2020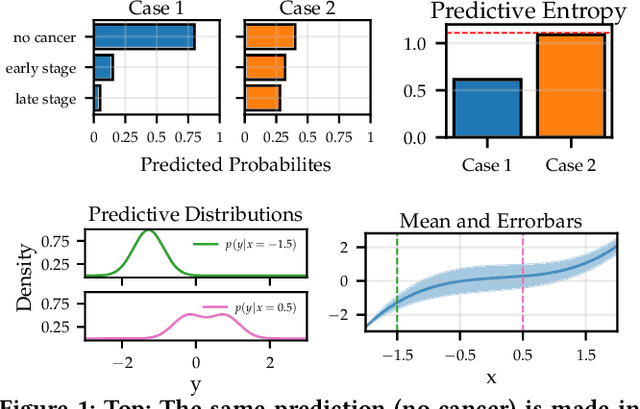

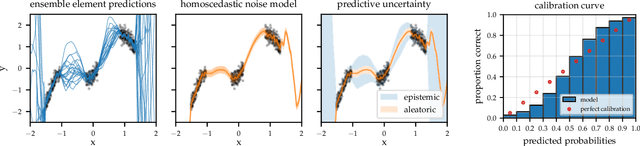
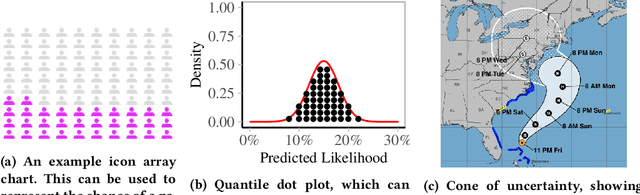
Transparency of algorithmic systems entails exposing system properties to various stakeholders for purposes that include understanding, improving, and/or contesting predictions. The machine learning (ML) community has mostly considered explainability as a proxy for transparency. With this work, we seek to encourage researchers to study uncertainty as a form of transparency and practitioners to communicate uncertainty estimates to stakeholders. First, we discuss methods for assessing uncertainty. Then, we describe the utility of uncertainty for mitigating model unfairness, augmenting decision-making, and building trustworthy systems. We also review methods for displaying uncertainty to stakeholders and discuss how to collect information required for incorporating uncertainty into existing ML pipelines. Our contribution is an interdisciplinary review to inform how to measure, communicate, and use uncertainty as a form of transparency.
Active Learning++: Incorporating Annotator's Rationale using Local Model Explanation
Sep 06, 2020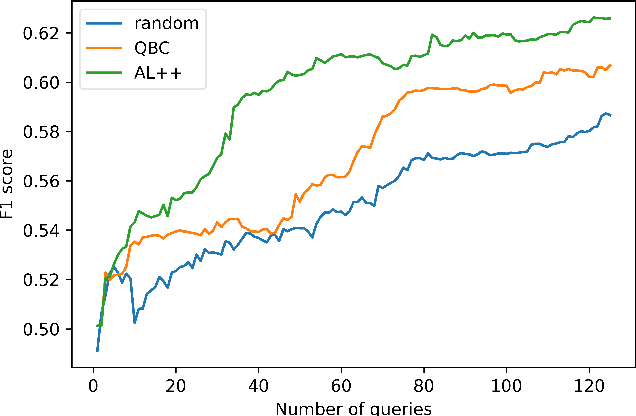
We propose a new active learning (AL) framework, Active Learning++, which can utilize an annotator's labels as well as its rationale. Annotators can provide their rationale for choosing a label by ranking input features based on their importance for a given query. To incorporate this additional input, we modified the disagreement measure for a bagging-based Query by Committee (QBC) sampling strategy. Instead of weighing all committee models equally to select the next instance, we assign higher weight to the committee model with higher agreement with the annotator's ranking. Specifically, we generated a feature importance-based local explanation for each committee model. The similarity score between feature rankings provided by the annotator and the local model explanation is used to assign a weight to each corresponding committee model. This approach is applicable to any kind of ML model using model-agnostic techniques to generate local explanation such as LIME. With a simulation study, we show that our framework significantly outperforms a QBC based vanilla AL framework.
Measuring Social Biases of Crowd Workers using Counterfactual Queries
Apr 04, 2020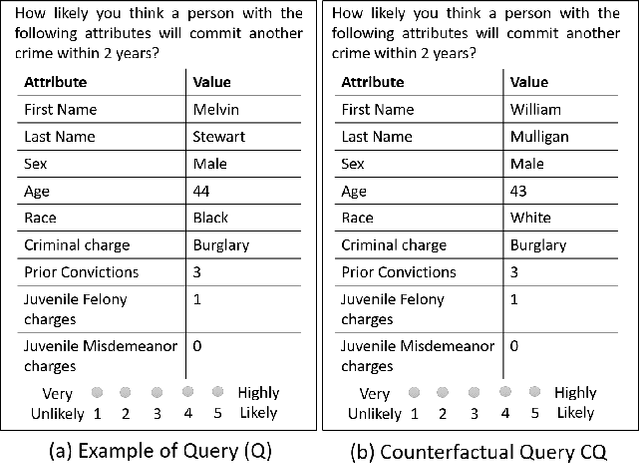
Social biases based on gender, race, etc. have been shown to pollute machine learning (ML) pipeline predominantly via biased training datasets. Crowdsourcing, a popular cost-effective measure to gather labeled training datasets, is not immune to the inherent social biases of crowd workers. To ensure such social biases aren't passed onto the curated datasets, it's important to know how biased each crowd worker is. In this work, we propose a new method based on counterfactual fairness to quantify the degree of inherent social bias in each crowd worker. This extra information can be leveraged together with individual worker responses to curate a less biased dataset.
Questioning the AI: Informing Design Practices for Explainable AI User Experiences
Feb 08, 2020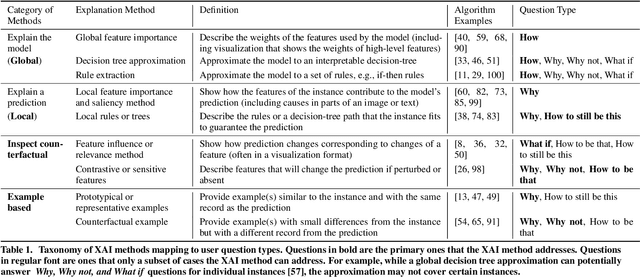

A surge of interest in explainable AI (XAI) has led to a vast collection of algorithmic work on the topic. While many recognize the necessity to incorporate explainability features in AI systems, how to address real-world user needs for understanding AI remains an open question. By interviewing 20 UX and design practitioners working on various AI products, we seek to identify gaps between the current XAI algorithmic work and practices to create explainable AI products. To do so, we develop an algorithm-informed XAI question bank in which user needs for explainability are represented as prototypical questions users might ask about the AI, and use it as a study probe. Our work contributes insights into the design space of XAI, informs efforts to support design practices in this space, and identifies opportunities for future XAI work. We also provide an extended XAI question bank and discuss how it can be used for creating user-centered XAI.
Explainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience
Jan 31, 2020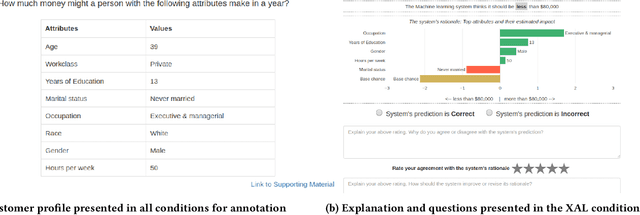
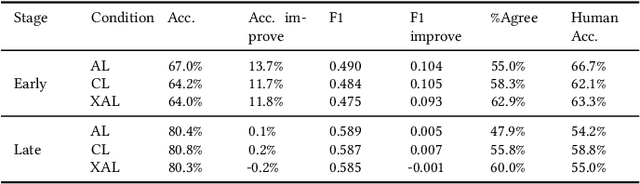
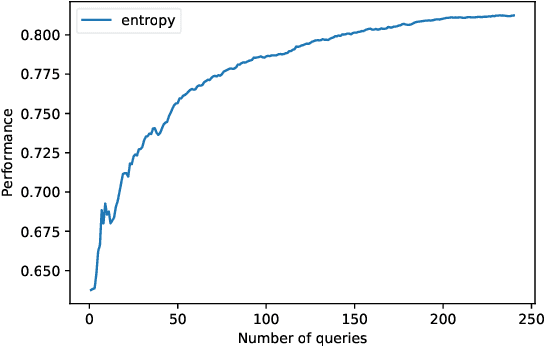
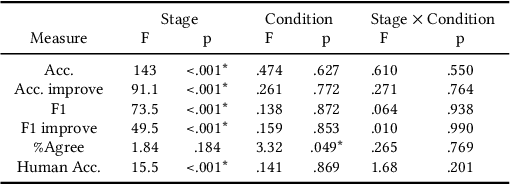
Active Learning (AL) is a human-in-the-loop Machine Learning paradigm favored for its ability to learn with fewer labeled instances, but the model's states and progress remain opaque to the annotators. Meanwhile, many recognize the benefits of model transparency for people interacting with ML models, as reflected by the surge of explainable AI (XAI) as a research field. However, explaining an evolving model introduces many open questions regarding its impact on the annotation quality and the annotator's experience. In this paper, we propose a novel paradigm of explainable active learning (XAL), by explaining the learning algorithm's prediction for the instance it wants to learn from and soliciting feedback from the annotator. We conduct an empirical study comparing the model learning outcome, human feedback content and the annotator experience with XAL, to that of traditional AL and coactive learning (providing the model's prediction without the explanation). Our study reveals benefits--supporting trust calibration and enabling additional forms of human feedback, and potential drawbacks--anchoring effect and frustration from transparent model limitations--of providing local explanations in AL. We conclude by suggesting directions for developing explanations that better support annotator experience in AL and interactive ML settings.
Effect of Confidence and Explanation on Accuracy and Trust Calibration in AI-Assisted Decision Making
Jan 07, 2020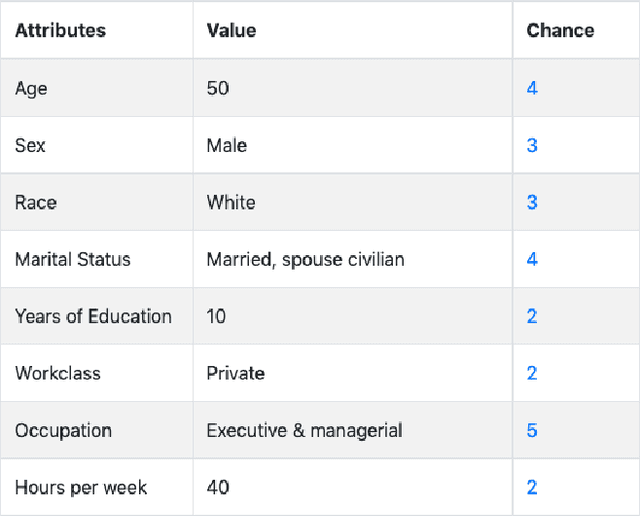
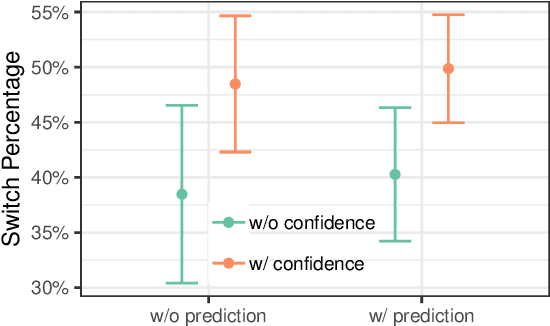
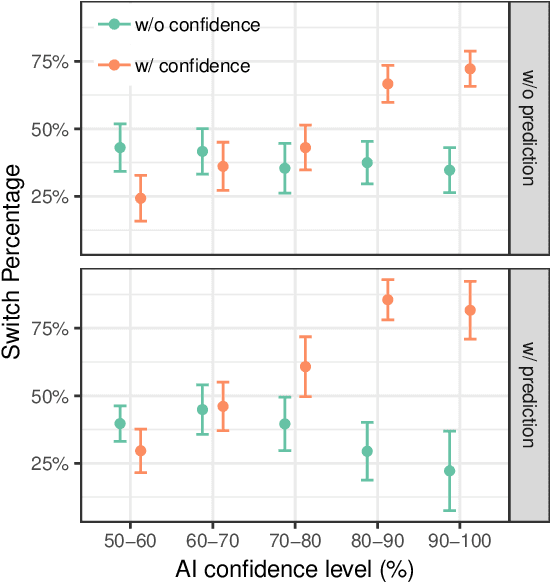
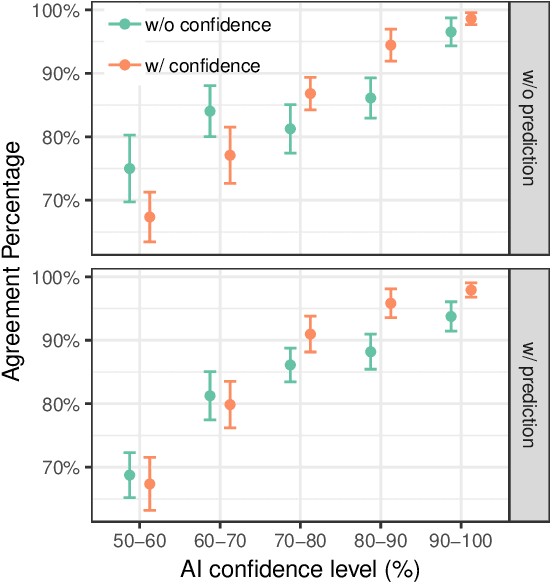
Today, AI is being increasingly used to help human experts make decisions in high-stakes scenarios. In these scenarios, full automation is often undesirable, not only due to the significance of the outcome, but also because human experts can draw on their domain knowledge complementary to the model's to ensure task success. We refer to these scenarios as AI-assisted decision making, where the individual strengths of the human and the AI come together to optimize the joint decision outcome. A key to their success is to appropriately \textit{calibrate} human trust in the AI on a case-by-case basis; knowing when to trust or distrust the AI allows the human expert to appropriately apply their knowledge, improving decision outcomes in cases where the model is likely to perform poorly. This research conducts a case study of AI-assisted decision making in which humans and AI have comparable performance alone, and explores whether features that reveal case-specific model information can calibrate trust and improve the joint performance of the human and AI. Specifically, we study the effect of showing confidence score and local explanation for a particular prediction. Through two human experiments, we show that confidence score can help calibrate people's trust in an AI model, but trust calibration alone is not sufficient to improve AI-assisted decision making, which may also depend on whether the human can bring in enough unique knowledge to complement the AI's errors. We also highlight the problems in using local explanation for AI-assisted decision making scenarios and invite the research community to explore new approaches to explainability for calibrating human trust in AI.
Enabling Value Sensitive AI Systems through Participatory Design Fictions
Dec 13, 2019Two general routes have been followed to develop artificial agents that are sensitive to human values---a top-down approach to encode values into the agents, and a bottom-up approach to learn from human actions, whether from real-world interactions or stories. Although both approaches have made exciting scientific progress, they may face challenges when applied to the current development practices of AI systems, which require the under-standing of the specific domains and specific stakeholders involved. In this work, we bring together perspectives from the human-computer interaction (HCI) community, where designing technologies sensitive to user values has been a longstanding focus. We highlight several well-established areas focusing on developing empirical methods for inquiring user values. Based on these methods, we propose participatory design fictions to study user values involved in AI systems and present preliminary results from a case study. With this paper, we invite the consideration of user-centered value inquiry and value learning.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019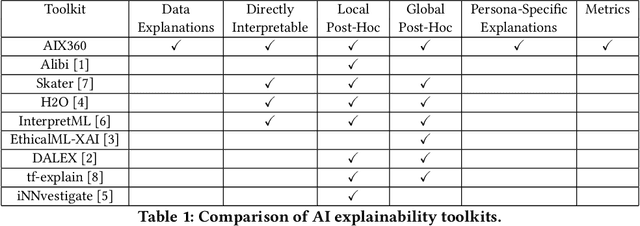
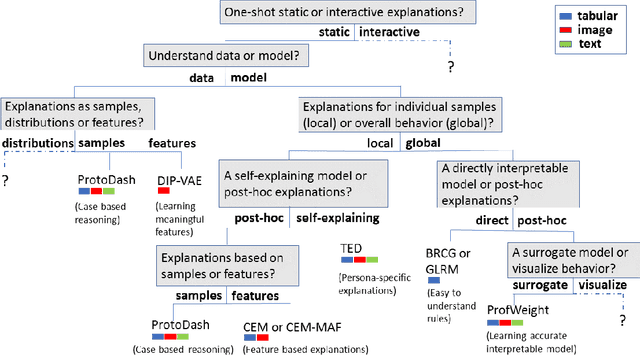
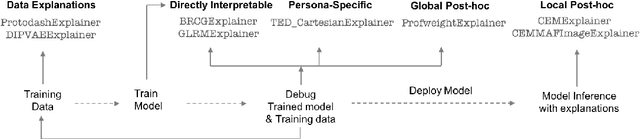
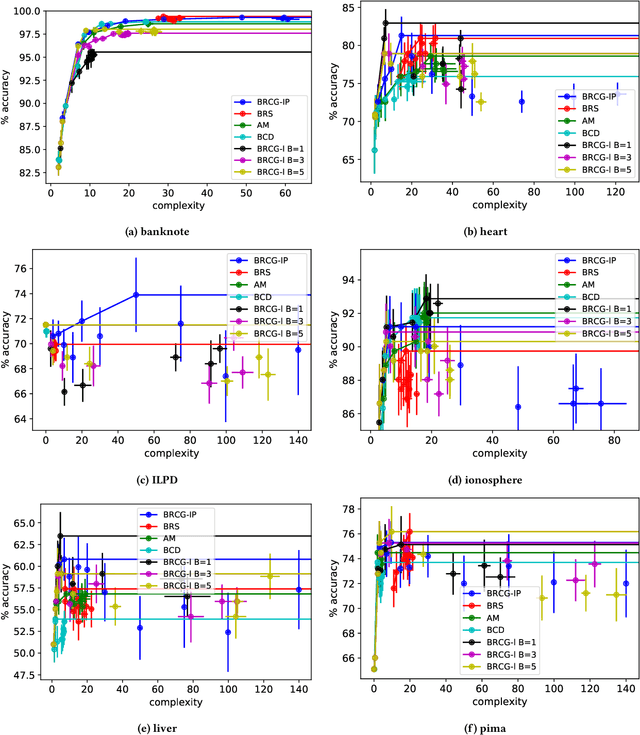
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.