 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Extractor-Paraphraser based Abstractive Summarization
May 04, 2021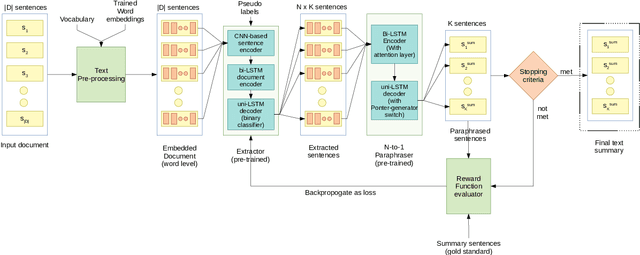
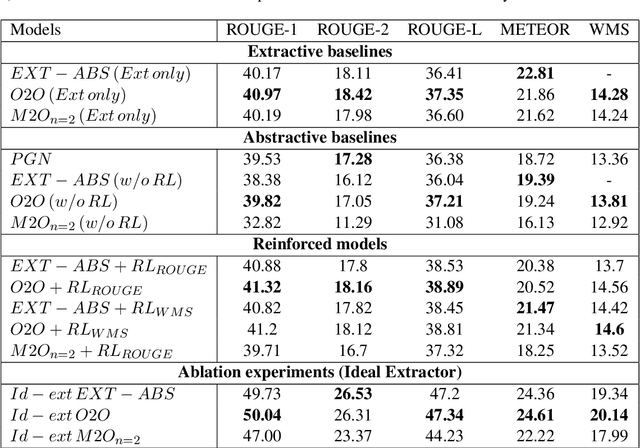
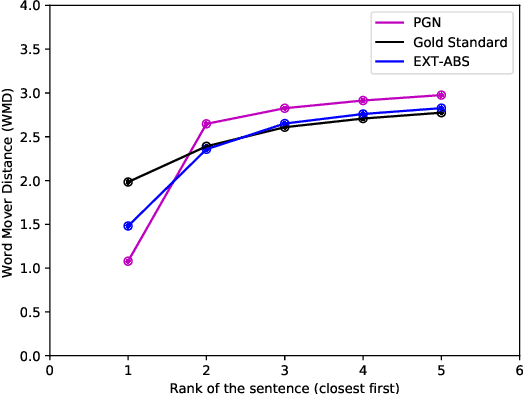

The anthology of spoken languages today is inundated with textual information, necessitating the development of automatic summarization models. In this manuscript, we propose an extractor-paraphraser based abstractive summarization system that exploits semantic overlap as opposed to its predecessors that focus more on syntactic information overlap. Our model outperforms the state-of-the-art baselines in terms of ROUGE, METEOR and word mover similarity (WMS), establishing the superiority of the proposed system via extensive ablation experiments. We have also challenged the summarization capabilities of the state of the art Pointer Generator Network (PGN), and through thorough experimentation, shown that PGN is more of a paraphraser, contrary to the prevailing notion of a summarizer; illustrating it's incapability to accumulate information across multiple sentences.
Techniques for Jointly Extracting Entities and Relations: A Survey
Mar 10, 2021
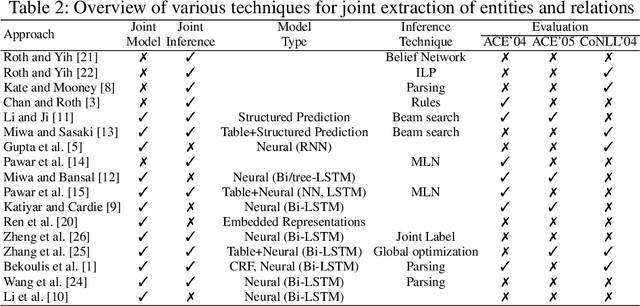
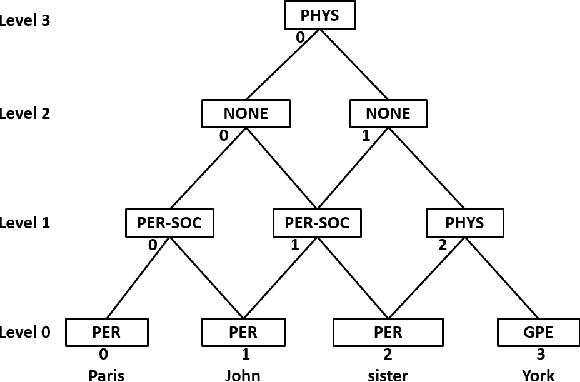
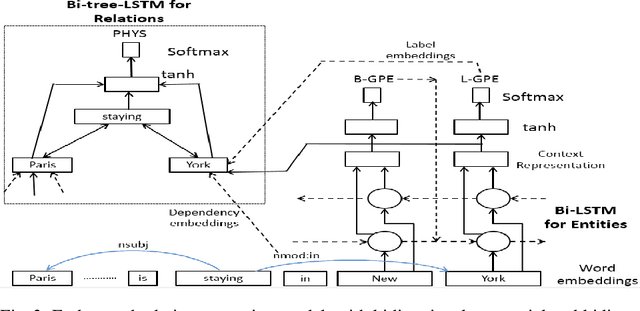
Relation Extraction is an important task in Information Extraction which deals with identifying semantic relations between entity mentions. Traditionally, relation extraction is carried out after entity extraction in a "pipeline" fashion, so that relation extraction only focuses on determining whether any semantic relation exists between a pair of extracted entity mentions. This leads to propagation of errors from entity extraction stage to relation extraction stage. Also, entity extraction is carried out without any knowledge about the relations. Hence, it was observed that jointly performing entity and relation extraction is beneficial for both the tasks. In this paper, we survey various techniques for jointly extracting entities and relations. We categorize techniques based on the approach they adopt for joint extraction, i.e. whether they employ joint inference or joint modelling or both. We further describe some representative techniques for joint inference and joint modelling. We also describe two standard datasets, evaluation techniques and performance of the joint extraction approaches on these datasets. We present a brief analysis of application of a general domain joint extraction approach to a Biomedical dataset. This survey is useful for researchers as well as practitioners in the field of Information Extraction, by covering a broad landscape of joint extraction techniques.
Knowledge-based Extraction of Cause-Effect Relations from Biomedical Text
Mar 10, 2021


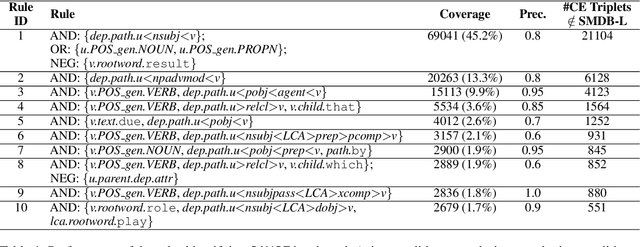
We propose a knowledge-based approach for extraction of Cause-Effect (CE) relations from biomedical text. Our approach is a combination of an unsupervised machine learning technique to discover causal triggers and a set of high-precision linguistic rules to identify cause/effect arguments of these causal triggers. We evaluate our approach using a corpus of 58,761 Leukaemia-related PubMed abstracts consisting of 568,528 sentences. We could extract 152,655 CE triplets from this corpus where each triplet consists of a cause phrase, an effect phrase and a causal trigger. As compared to the existing knowledge base - SemMedDB (Kilicoglu et al., 2012), the number of extractions are almost twice. Moreover, the proposed approach outperformed the existing technique SemRep (Rindflesch and Fiszman, 2003) on a dataset of 500 sentences.
Cognitively Aided Zero-Shot Automatic Essay Grading
Feb 22, 2021
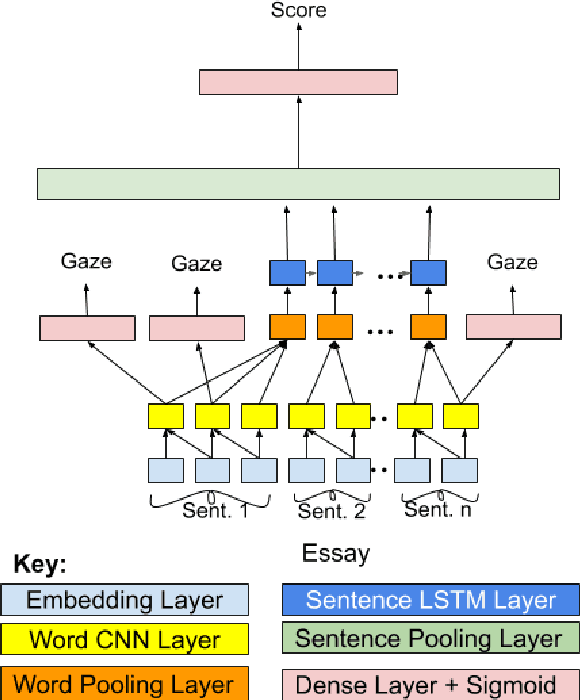
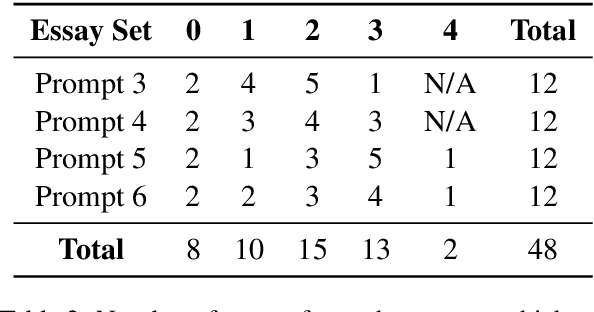
Automatic essay grading (AEG) is a process in which machines assign a grade to an essay written in response to a topic, called the prompt. Zero-shot AEG is when we train a system to grade essays written to a new prompt which was not present in our training data. In this paper, we describe a solution to the problem of zero-shot automatic essay grading, using cognitive information, in the form of gaze behaviour. Our experiments show that using gaze behaviour helps in improving the performance of AEG systems, especially when we provide a new essay written in response to a new prompt for scoring, by an average of almost 5 percentage points of QWK.
Many Hands Make Light Work: Using Essay Traits to Automatically Score Essays
Feb 01, 2021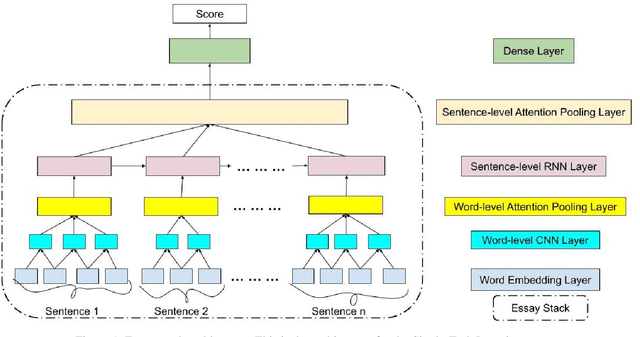
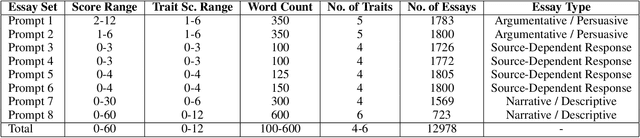
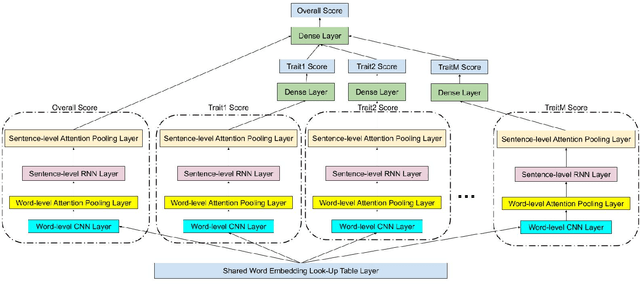
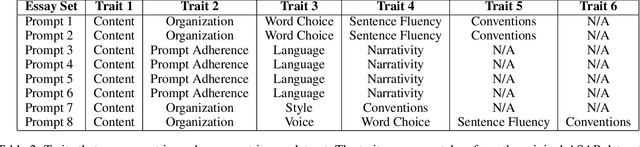
Most research in the area of automatic essay grading (AEG) is geared towards scoring the essay holistically while there has also been some work done on scoring individual essay traits. In this paper, we describe a way to score essays holistically using a multi-task learning (MTL) approach, where scoring the essay holistically is the primary task, and scoring the essay traits is the auxiliary task. We compare our results with a single-task learning (STL) approach, using both LSTMs and BiLSTMs. We also compare our results of the auxiliary task with such tasks done in other AEG systems. To find out which traits work best for different types of essays, we conduct ablation tests for each of the essay traits. We also report the runtime and number of training parameters for each system. We find that MTL-based BiLSTM system gives the best results for scoring the essay holistically, as well as performing well on scoring the essay traits.
Can Taxonomy Help? Improving Semantic Question Matching using Question Taxonomy
Jan 20, 2021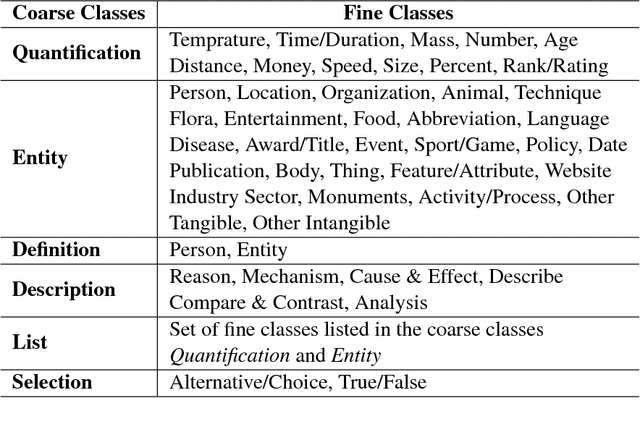
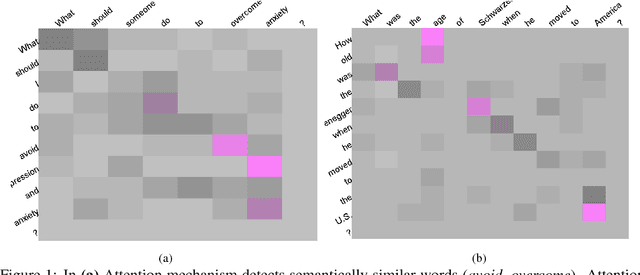
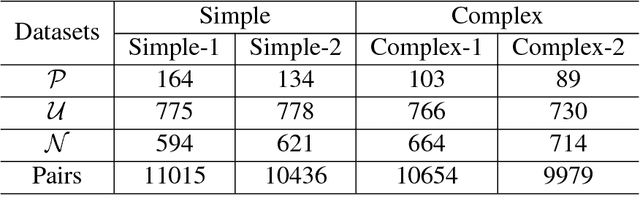
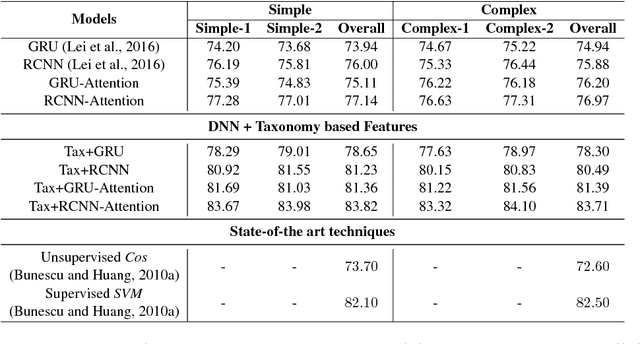
In this paper, we propose a hybrid technique for semantic question matching. It uses our proposed two-layered taxonomy for English questions by augmenting state-of-the-art deep learning models with question classes obtained from a deep learning based question classifier. Experiments performed on three open-domain datasets demonstrate the effectiveness of our proposed approach. We achieve state-of-the-art results on partial ordering question ranking (POQR) benchmark dataset. Our empirical analysis shows that coupling standard distributional features (provided by the question encoder) with knowledge from taxonomy is more effective than either deep learning (DL) or taxonomy-based knowledge alone.
Divide and Conquer: An Ensemble Approach for Hostile Post Detection in Hindi
Jan 20, 2021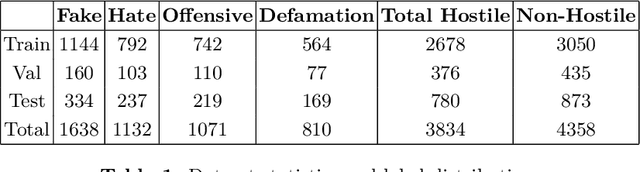
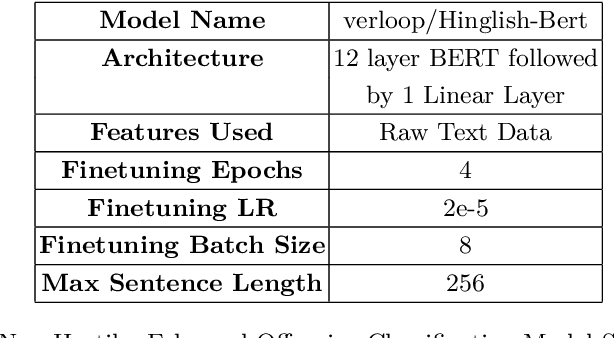


Recently the NLP community has started showing interest towards the challenging task of Hostile Post Detection. This paper present our system for Shared Task at Constraint2021 on "Hostile Post Detection in Hindi". The data for this shared task is provided in Hindi Devanagari script which was collected from Twitter and Facebook. It is a multi-label multi-class classification problem where each data instance is annotated into one or more of the five classes: fake, hate, offensive, defamation, and non-hostile. We propose a two level architecture which is made up of BERT based classifiers and statistical classifiers to solve this problem. Our team 'Albatross', scored 0.9709 Coarse grained hostility F1 score measure on Hostile Post Detection in Hindi subtask and secured 2nd rank out of 45 teams for the task. Our submission is ranked 2nd and 3rd out of a total of 156 submissions with Coarse grained hostility F1 score of 0.9709 and 0.9703 respectively. Our fine grained scores are also very encouraging and can be improved with further finetuning. The code is publicly available.
EmotionGIF-IITP-AINLPML: Ensemble-based Automated Deep Neural System for predicting category(ies) of a GIF response
Dec 23, 2020
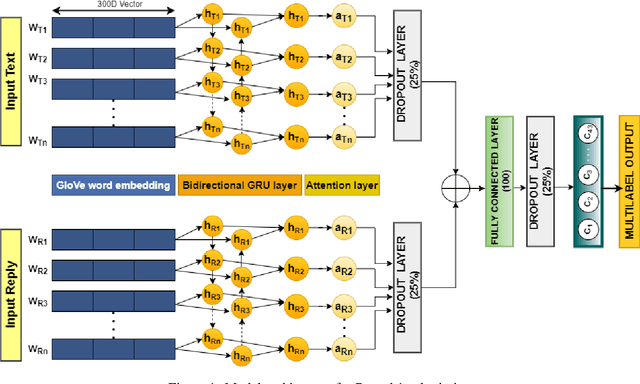
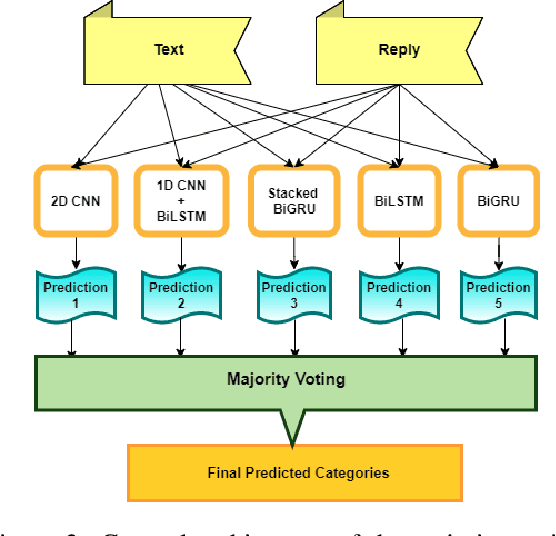
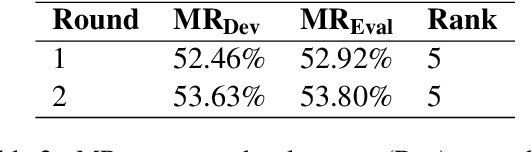
In this paper, we describe the systems submitted by our IITP-AINLPML team in the shared task of SocialNLP 2020, EmotionGIF 2020, on predicting the category(ies) of a GIF response for a given unlabelled tweet. For the round 1 phase of the task, we propose an attention-based Bi-directional GRU network trained on both the tweet (text) and their replies (text wherever available) and the given category(ies) for its GIF response. In the round 2 phase, we build several deep neural-based classifiers for the task and report the final predictions through a majority voting based ensemble technique. Our proposed models attain the best Mean Recall (MR) scores of 52.92% and 53.80% in round 1 and round 2, respectively.
Assessing the Severity of Health States based on Social Media Posts
Sep 21, 2020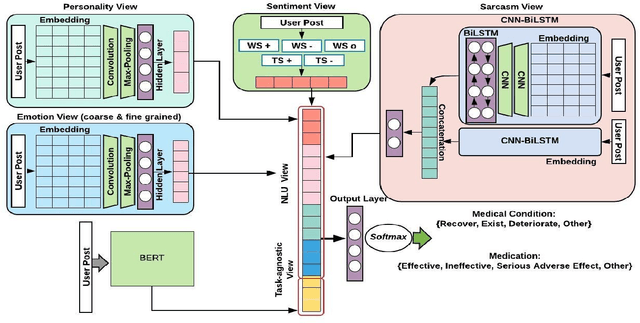
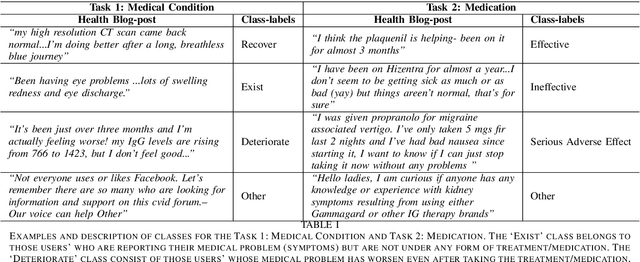


The unprecedented growth of Internet users has resulted in an abundance of unstructured information on social media including health forums, where patients request health-related information or opinions from other users. Previous studies have shown that online peer support has limited effectiveness without expert intervention. Therefore, a system capable of assessing the severity of health state from the patients' social media posts can help health professionals (HP) in prioritizing the user's post. In this study, we inspect the efficacy of different aspects of Natural Language Understanding (NLU) to identify the severity of the user's health state in relation to two perspectives(tasks) (a) Medical Condition (i.e., Recover, Exist, Deteriorate, Other) and (b) Medication (i.e., Effective, Ineffective, Serious Adverse Effect, Other) in online health communities. We propose a multiview learning framework that models both the textual content as well as contextual-information to assess the severity of the user's health state. Specifically, our model utilizes the NLU views such as sentiment, emotions, personality, and use of figurative language to extract the contextual information. The diverse NLU views demonstrate its effectiveness on both the tasks and as well as on the individual disease to assess a user's health.
Tweet to News Conversion: An Investigation into Unsupervised Controllable Text Generation
Aug 21, 2020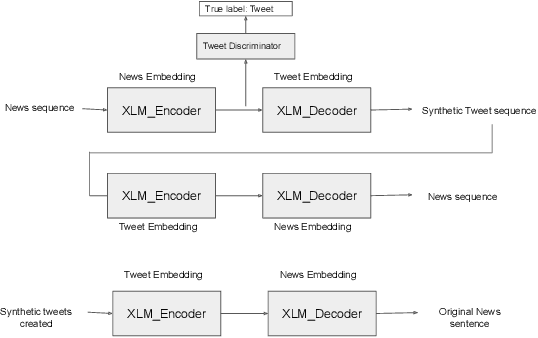
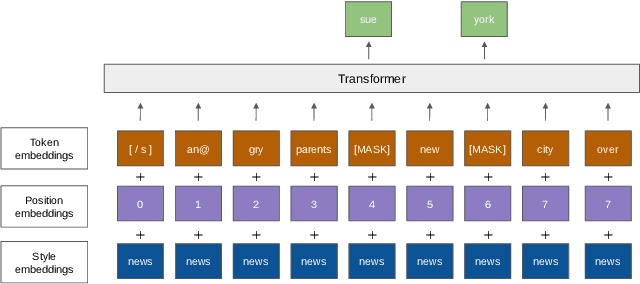
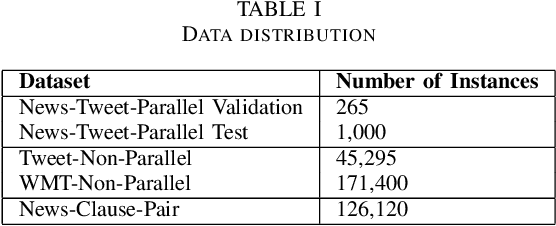
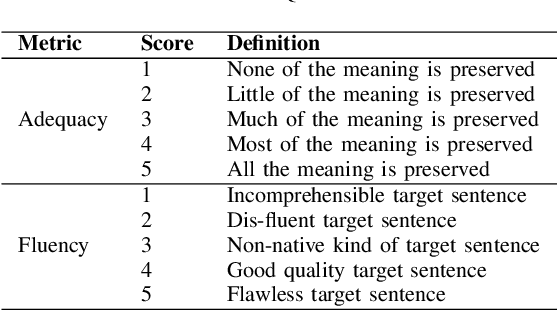
Text generator systems have become extremely popular with the advent of recent deep learning models such as encoder-decoder. Controlling the information and style of the generated output without supervision is an important and challenging Natural Language Processing (NLP) task. In this paper, we define the task of constructing a coherent paragraph from a set of disaster domain tweets, without any parallel data. We tackle the problem by building two systems in pipeline. The first system focuses on unsupervised style transfer and converts the individual tweets into news sentences. The second system stitches together the outputs from the first system to form a coherent news paragraph. We also propose a novel training mechanism, by splitting the sentences into propositions and training the second system to merge the sentences. We create a validation and test set consisting of tweet-sets and their equivalent news paragraphs to perform empirical evaluation. In a completely unsupervised setting, our model was able to achieve a BLEU score of 19.32, while successfully transferring styles and joining tweets to form a meaningful news paragraph.