 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Human-Machine Partnership for Manufacturing: Enhancing Warehouse Planning through Simulation-Driven Knowledge Graphs and LLM Collaboration
Dec 20, 2025Manufacturing planners face complex operational challenges that require seamless collaboration between human expertise and intelligent systems to achieve optimal performance in modern production environments. Traditional approaches to analyzing simulation-based manufacturing data often create barriers between human decision-makers and critical operational insights, limiting effective partnership in manufacturing planning. Our framework establishes a collaborative intelligence system integrating Knowledge Graphs and Large Language Model-based agents to bridge this gap, empowering manufacturing professionals through natural language interfaces for complex operational analysis. The system transforms simulation data into semantically rich representations, enabling planners to interact naturally with operational insights without specialized expertise. A collaborative LLM agent works alongside human decision-makers, employing iterative reasoning that mirrors human analytical thinking while generating precise queries for knowledge extraction and providing transparent validation. This partnership approach to manufacturing bottleneck identification, validated through operational scenarios, demonstrates enhanced performance while maintaining human oversight and decision authority. For operational inquiries, the system achieves near-perfect accuracy through natural language interaction. For investigative scenarios requiring collaborative analysis, we demonstrate the framework's effectiveness in supporting human experts to uncover interconnected operational issues that enhance understanding and decision-making. This work advances collaborative manufacturing by creating intuitive methods for actionable insights, reducing cognitive load while amplifying human analytical capabilities in evolving manufacturing ecosystems.
Thinking in Many Modes: How Composite Reasoning Elevates Large Language Model Performance with Limited Data
Sep 26, 2025



Large Language Models (LLMs), despite their remarkable capabilities, rely on singular, pre-dominant reasoning paradigms, hindering their performance on intricate problems that demand diverse cognitive strategies. To address this, we introduce Composite Reasoning (CR), a novel reasoning approach empowering LLMs to dynamically explore and combine multiple reasoning styles like deductive, inductive, and abductive for more nuanced problem-solving. Evaluated on scientific and medical question-answering benchmarks, our approach outperforms existing baselines like Chain-of-Thought (CoT) and also surpasses the accuracy of DeepSeek-R1 style reasoning (SR) capabilities, while demonstrating superior sample efficiency and adequate token usage. Notably, CR adaptively emphasizes domain-appropriate reasoning styles. It prioritizes abductive and deductive reasoning for medical question answering, but shifts to causal, deductive, and inductive methods for scientific reasoning. Our findings highlight that by cultivating internal reasoning style diversity, LLMs acquire more robust, adaptive, and efficient problem-solving abilities.
Leveraging Knowledge Graphs and LLM Reasoning to Identify Operational Bottlenecks for Warehouse Planning Assistance
Jul 23, 2025



Analyzing large, complex output datasets from Discrete Event Simulations (DES) of warehouse operations to identify bottlenecks and inefficiencies is a critical yet challenging task, often demanding significant manual effort or specialized analytical tools. Our framework integrates Knowledge Graphs (KGs) and Large Language Model (LLM)-based agents to analyze complex Discrete Event Simulation (DES) output data from warehouse operations. It transforms raw DES data into a semantically rich KG, capturing relationships between simulation events and entities. An LLM-based agent uses iterative reasoning, generating interdependent sub-questions. For each sub-question, it creates Cypher queries for KG interaction, extracts information, and self-reflects to correct errors. This adaptive, iterative, and self-correcting process identifies operational issues mimicking human analysis. Our DES approach for warehouse bottleneck identification, tested with equipment breakdowns and process irregularities, outperforms baseline methods. For operational questions, it achieves near-perfect pass rates in pinpointing inefficiencies. For complex investigative questions, we demonstrate its superior diagnostic ability to uncover subtle, interconnected issues. This work bridges simulation modeling and AI (KG+LLM), offering a more intuitive method for actionable insights, reducing time-to-insight, and enabling automated warehouse inefficiency evaluation and diagnosis.
ACT: Bridging the Gap in Code Translation through Synthetic Data Generation & Adaptive Training
Jul 22, 2025



Code translation is a crucial process in software development and migration projects, enabling interoperability between different programming languages and enhancing software adaptability and thus longevity. Traditional automated translation methods rely heavily on handcrafted transformation rules, which often lack flexibility and scalability. Meanwhile, advanced language models present promising alternatives but are often limited by proprietary, API-based implementations that raise concerns over data security and reliance. In this paper, we present Auto-Train for Code Translation (ACT), an innovative framework that aims to improve code translation capabilities by enabling in-house finetuning of open-source Large Language Models (LLMs). ACT's automated pipeline significantly boosts the performance of these models, narrowing the gap between open-source accessibility and the high performance of closed-source solutions. Central to ACT is its synthetic data generation module, which builds extensive, high-quality datasets from initial code samples, incorporating unit tests to ensure functional accuracy and diversity. ACT's evaluation framework incorporates execution-level checks, offering a comprehensive assessment of translation quality. A key feature in ACT is its controller module, which manages the entire pipeline by dynamically adjusting hyperparameters, orchestrating iterative data generation, and finetuning based on real-time evaluations. This enables ACT to intelligently optimize when to continue training, generate additional targeted training data, or stop the process. Our results demonstrate that ACT consistently enhances the effectiveness of open-source models, offering businesses and developers a secure and reliable alternative. Additionally, applying our data generation pipeline to industry-scale migration projects has led to a notable increase in developer acceleration.
INA: An Integrative Approach for Enhancing Negotiation Strategies with Reward-Based Dialogue System
Oct 27, 2023



In this paper, we propose a novel negotiation dialogue agent designed for the online marketplace. Our agent is integrative in nature i.e, it possesses the capability to negotiate on price as well as other factors, such as the addition or removal of items from a deal bundle, thereby offering a more flexible and comprehensive negotiation experience. We create a new dataset called Integrative Negotiation Dataset (IND) to enable this functionality. For this dataset creation, we introduce a new semi-automated data creation method, which combines defining negotiation intents, actions, and intent-action simulation between users and the agent to generate potential dialogue flows. Finally, the prompting of GPT-J, a state-of-the-art language model, is done to generate dialogues for a given intent, with a human-in-the-loop process for post-editing and refining minor errors to ensure high data quality. We employ a set of novel rewards, specifically tailored for the negotiation task to train our Negotiation Agent, termed as the Integrative Negotiation Agent (INA). These rewards incentivize the chatbot to learn effective negotiation strategies that can adapt to various contextual requirements and price proposals. By leveraging the IND, we train our model and conduct experiments to evaluate the effectiveness of our reward-based dialogue system for negotiation. Our results demonstrate that the proposed approach and reward system significantly enhance the agent's negotiation capabilities. The INA successfully engages in integrative negotiations, displaying the ability to dynamically adjust prices and negotiate the inclusion or exclusion of items in a bundle deal
Elevating Code-mixed Text Handling through Auditory Information of Words
Oct 27, 2023



With the growing popularity of code-mixed data, there is an increasing need for better handling of this type of data, which poses a number of challenges, such as dealing with spelling variations, multiple languages, different scripts, and a lack of resources. Current language models face difficulty in effectively handling code-mixed data as they primarily focus on the semantic representation of words and ignore the auditory phonetic features. This leads to difficulties in handling spelling variations in code-mixed text. In this paper, we propose an effective approach for creating language models for handling code-mixed textual data using auditory information of words from SOUNDEX. Our approach includes a pre-training step based on masked-language-modelling, which includes SOUNDEX representations (SAMLM) and a new method of providing input data to the pre-trained model. Through experimentation on various code-mixed datasets (of different languages) for sentiment, offensive and aggression classification tasks, we establish that our novel language modeling approach (SAMLM) results in improved robustness towards adversarial attacks on code-mixed classification tasks. Additionally, our SAMLM based approach also results in better classification results over the popular baselines for code-mixed tasks. We use the explainability technique, SHAP (SHapley Additive exPlanations) to explain how the auditory features incorporated through SAMLM assist the model to handle the code-mixed text effectively and increase robustness against adversarial attacks \footnote{Source code has been made available on \url{https://github.com/20118/DefenseWithPhonetics}, \url{https://www.iitp.ac.in/~ai-nlp-ml/resources.html\#Phonetics}}.
Tweet to News Conversion: An Investigation into Unsupervised Controllable Text Generation
Aug 21, 2020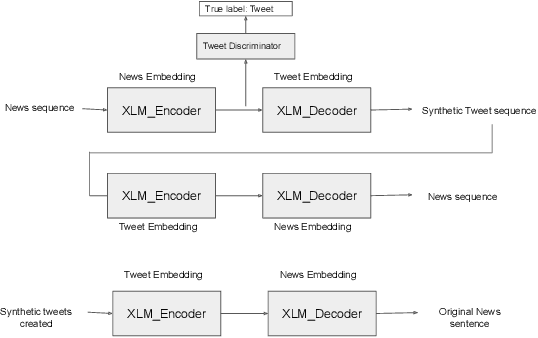
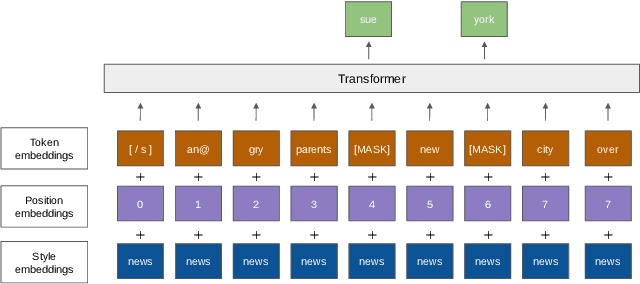
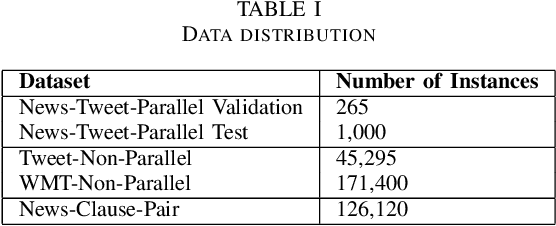
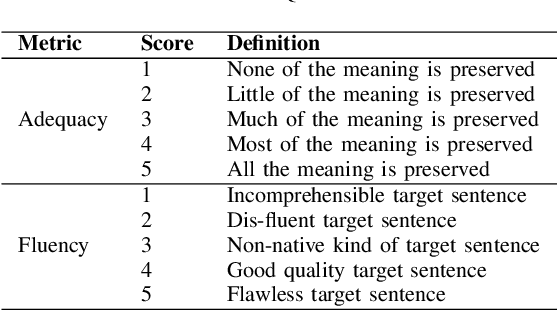
Text generator systems have become extremely popular with the advent of recent deep learning models such as encoder-decoder. Controlling the information and style of the generated output without supervision is an important and challenging Natural Language Processing (NLP) task. In this paper, we define the task of constructing a coherent paragraph from a set of disaster domain tweets, without any parallel data. We tackle the problem by building two systems in pipeline. The first system focuses on unsupervised style transfer and converts the individual tweets into news sentences. The second system stitches together the outputs from the first system to form a coherent news paragraph. We also propose a novel training mechanism, by splitting the sentences into propositions and training the second system to merge the sentences. We create a validation and test set consisting of tweet-sets and their equivalent news paragraphs to perform empirical evaluation. In a completely unsupervised setting, our model was able to achieve a BLEU score of 19.32, while successfully transferring styles and joining tweets to form a meaningful news paragraph.