 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do you MEME? Generating Explanations for Visual Semantic Role Labelling in Memes
Dec 20, 2022



Memes are powerful means for effective communication on social media. Their effortless amalgamation of viral visuals and compelling messages can have far-reaching implications with proper marketing. Previous research on memes has primarily focused on characterizing their affective spectrum and detecting whether the meme's message insinuates any intended harm, such as hate, offense, racism, etc. However, memes often use abstraction, which can be elusive. Here, we introduce a novel task - EXCLAIM, generating explanations for visual semantic role labeling in memes. To this end, we curate ExHVV, a novel dataset that offers natural language explanations of connotative roles for three types of entities - heroes, villains, and victims, encompassing 4,680 entities present in 3K memes. We also benchmark ExHVV with several strong unimodal and multimodal baselines. Moreover, we posit LUMEN, a novel multimodal, multi-task learning framework that endeavors to address EXCLAIM optimally by jointly learning to predict the correct semantic roles and correspondingly to generate suitable natural language explanations. LUMEN distinctly outperforms the best baseline across 18 standard natural language generation evaluation metrics. Our systematic evaluation and analyses demonstrate that characteristic multimodal cues required for adjudicating semantic roles are also helpful for generating suitable explanations.
Overview of the WANLP 2022 Shared Task on Propaganda Detection in Arabic
Nov 18, 2022



Propaganda is the expression of an opinion or an action by an individual or a group deliberately designed to influence the opinions or the actions of other individuals or groups with reference to predetermined ends, which is achieved by means of well-defined rhetorical and psychological devices. Propaganda techniques are commonly used in social media to manipulate or to mislead users. Thus, there has been a lot of recent research on automatic detection of propaganda techniques in text as well as in memes. However, so far the focus has been primarily on English. With the aim to bridge this language gap, we ran a shared task on detecting propaganda techniques in Arabic tweets as part of the WANLP 2022 workshop, which included two subtasks. Subtask~1 asks to identify the set of propaganda techniques used in a tweet, which is a multilabel classification problem, while Subtask~2 asks to detect the propaganda techniques used in a tweet together with the exact span(s) of text in which each propaganda technique appears. The task attracted 63 team registrations, and eventually 14 and 3 teams made submissions for subtask 1 and 2, respectively. Finally, 11 teams submitted system description papers.
GREENER: Graph Neural Networks for News Media Profiling
Nov 10, 2022We study the problem of profiling news media on the Web with respect to their factuality of reporting and bias. This is an important but under-studied problem related to disinformation and "fake news" detection, but it addresses the issue at a coarser granularity compared to looking at an individual article or an individual claim. This is useful as it allows to profile entire media outlets in advance. Unlike previous work, which has focused primarily on text (e.g.,~on the text of the articles published by the target website, or on the textual description in their social media profiles or in Wikipedia), here our main focus is on modeling the similarity between media outlets based on the overlap of their audience. This is motivated by homophily considerations, i.e.,~the tendency of people to have connections to people with similar interests, which we extend to media, hypothesizing that similar types of media would be read by similar kinds of users. In particular, we propose GREENER (GRaph nEural nEtwork for News mEdia pRofiling), a model that builds a graph of inter-media connections based on their audience overlap, and then uses graph neural networks to represent each medium. We find that such representations are quite useful for predicting the factuality and the bias of news media outlets, yielding improvements over state-of-the-art results reported on two datasets. When augmented with conventionally used representations obtained from news articles, Twitter, YouTube, Facebook, and Wikipedia, prediction accuracy is found to improve by 2.5-27 macro-F1 points for the two tasks.
PASTA: Table-Operations Aware Fact Verification via Sentence-Table Cloze Pre-training
Nov 05, 2022Fact verification has attracted a lot of research attention recently, e.g., in journalism, marketing, and policymaking, as misinformation and disinformation online can sway one's opinion and affect one's actions. While fact-checking is a hard task in general, in many cases, false statements can be easily debunked based on analytics over tables with reliable information. Hence, table-based fact verification has recently emerged as an important and growing research area. Yet, progress has been limited due to the lack of datasets that can be used to pre-train language models (LMs) to be aware of common table operations, such as aggregating a column or comparing tuples. To bridge this gap, in this paper we introduce PASTA, a novel state-of-the-art framework for table-based fact verification via pre-training with synthesized sentence-table cloze questions. In particular, we design six types of common sentence-table cloze tasks, including Filter, Aggregation, Superlative, Comparative, Ordinal, and Unique, based on which we synthesize a large corpus consisting of 1.2 million sentence-table pairs from WikiTables. PASTA uses a recent pre-trained LM, DeBERTaV3, and further pretrains it on our corpus. Our experimental results show that PASTA achieves new state-of-the-art performance on two table-based fact verification benchmarks: TabFact and SEM-TAB-FACTS. In particular, on the complex set of TabFact, which contains multiple operations, PASTA largely outperforms the previous state of the art by 4.7 points (85.6% vs. 80.9%), and the gap between PASTA and human performance on the small TabFact test set is narrowed to just 1.5 points (90.6% vs. 92.1%).
IITD at the WANLP 2022 Shared Task: Multilingual Multi-Granularity Network for Propaganda Detection
Oct 31, 2022



We present our system for the two subtasks of the shared task on propaganda detection in Arabic, part of WANLP'2022. Subtask 1 is a multi-label classification problem to find the propaganda techniques used in a given tweet. Our system for this task uses XLM-R to predict probabilities for the target tweet to use each of the techniques. In addition to finding the techniques, Subtask 2 further asks to identify the textual span for each instance of each technique that is present in the tweet; the task can be modeled as a sequence tagging problem. We use a multi-granularity network with mBERT encoder for Subtask 2. Overall, our system ranks second for both subtasks (out of 14 and 3 participants, respectively). Our empirical analysis show that it does not help to use a much larger English corpus annotated with propaganda techniques, regardless of whether used in English or after translation to Arabic.
CrowdChecked: Detecting Previously Fact-Checked Claims in Social Media
Oct 10, 2022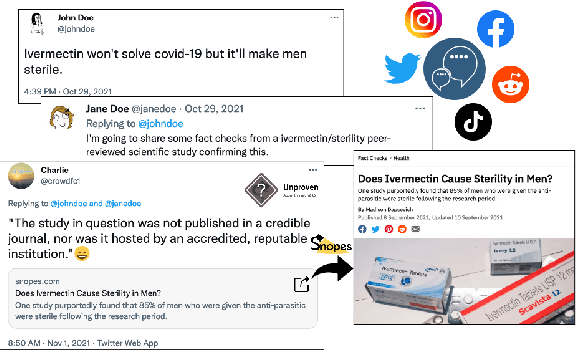
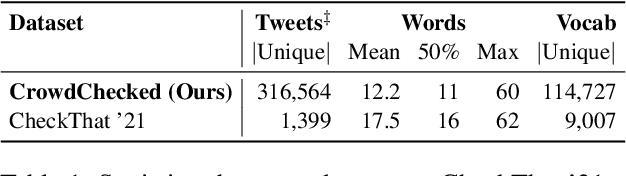
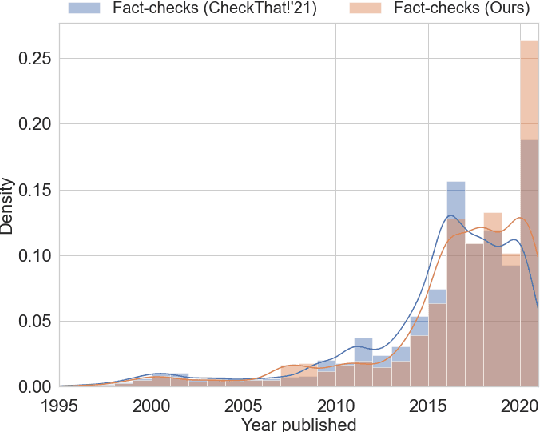
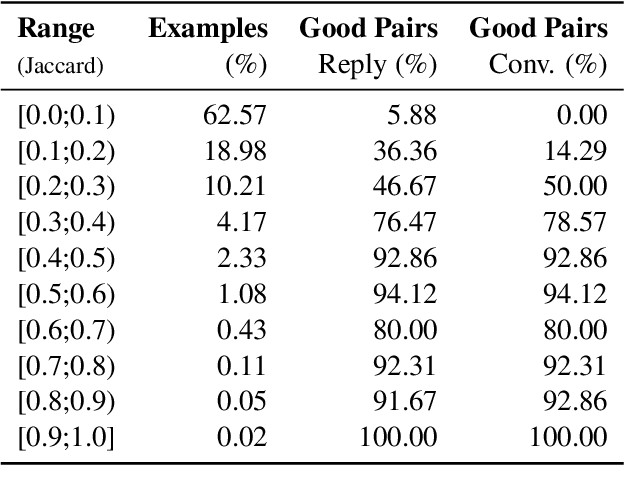
While there has been substantial progress in developing systems to automate fact-checking, they still lack credibility in the eyes of the users. Thus, an interesting approach has emerged: to perform automatic fact-checking by verifying whether an input claim has been previously fact-checked by professional fact-checkers and to return back an article that explains their decision. This is a sensible approach as people trust manual fact-checking, and as many claims are repeated multiple times. Yet, a major issue when building such systems is the small number of known tweet--verifying article pairs available for training. Here, we aim to bridge this gap by making use of crowd fact-checking, i.e., mining claims in social media for which users have responded with a link to a fact-checking article. In particular, we mine a large-scale collection of 330,000 tweets paired with a corresponding fact-checking article. We further propose an end-to-end framework to learn from this noisy data based on modified self-adaptive training, in a distant supervision scenario. Our experiments on the CLEF'21 CheckThat! test set show improvements over the state of the art by two points absolute. Our code and datasets are available at https://github.com/mhardalov/crowdchecked-claims
* Accepted to AACL-IJCNLP 2022 (Main Conference)
Ten Years after ImageNet: A 360° Perspective on AI
Oct 01, 2022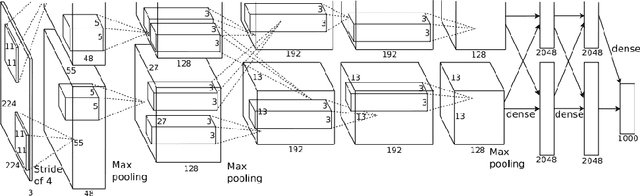
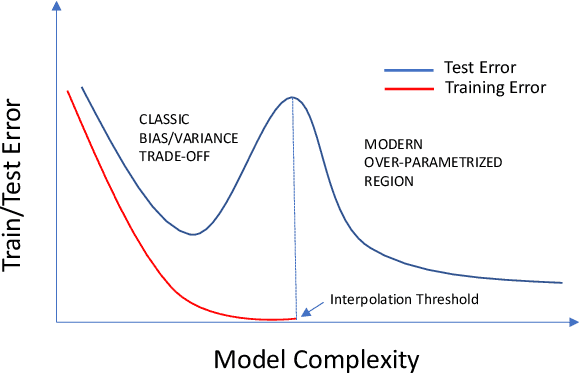
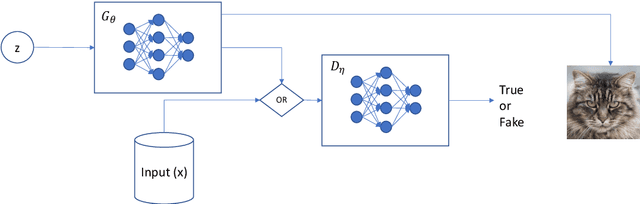
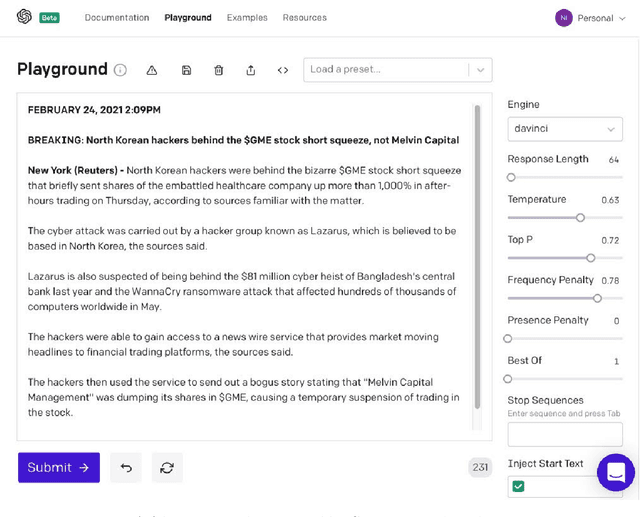
It is ten years since neural networks made their spectacular comeback. Prompted by this anniversary, we take a holistic perspective on Artificial Intelligence (AI). Supervised Learning for cognitive tasks is effectively solved - provided we have enough high-quality labeled data. However, deep neural network models are not easily interpretable, and thus the debate between blackbox and whitebox modeling has come to the fore. The rise of attention networks, self-supervised learning, generative modeling, and graph neural networks has widened the application space of AI. Deep Learning has also propelled the return of reinforcement learning as a core building block of autonomous decision making systems. The possible harms made possible by new AI technologies have raised socio-technical issues such as transparency, fairness, and accountability. The dominance of AI by Big-Tech who control talent, computing resources, and most importantly, data may lead to an extreme AI divide. Failure to meet high expectations in high profile, and much heralded flagship projects like self-driving vehicles could trigger another AI winter.
DISARM: Detecting the Victims Targeted by Harmful Memes
May 11, 2022

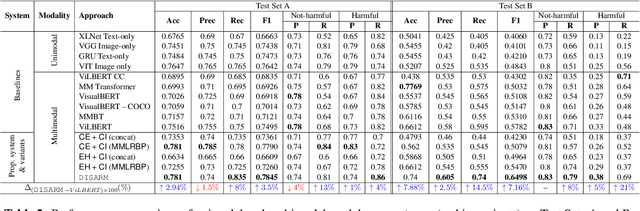
Internet memes have emerged as an increasingly popular means of communication on the Web. Although typically intended to elicit humour, they have been increasingly used to spread hatred, trolling, and cyberbullying, as well as to target specific individuals, communities, or society on political, socio-cultural, and psychological grounds. While previous work has focused on detecting harmful, hateful, and offensive memes, identifying whom they attack remains a challenging and underexplored area. Here we aim to bridge this gap. In particular, we create a dataset where we annotate each meme with its victim(s) such as the name of the targeted person(s), organization(s), and community(ies). We then propose DISARM (Detecting vIctimS targeted by hARmful Memes), a framework that uses named entity recognition and person identification to detect all entities a meme is referring to, and then, incorporates a novel contextualized multimodal deep neural network to classify whether the meme intends to harm these entities. We perform several systematic experiments on three test setups, corresponding to entities that are (a) all seen while training, (b) not seen as a harmful target on training, and (c) not seen at all on training. The evaluation results show that DISARM significantly outperforms ten unimodal and multimodal systems. Finally, we show that DISARM is interpretable and comparatively more generalizable and that it can reduce the relative error rate for harmful target identification by up to 9 points absolute over several strong multimodal rivals.
TeamX@DravidianLangTech-ACL2022: A Comparative Analysis for Troll-Based Meme Classification
May 09, 2022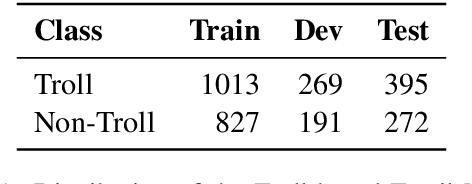
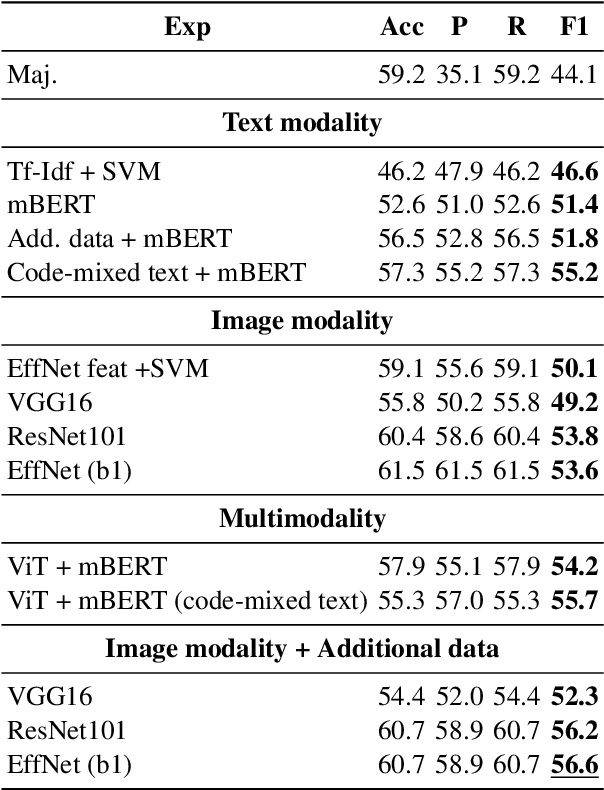
The spread of fake news, propaganda, misinformation, disinformation, and harmful content online raised concerns among social media platforms, government agencies, policymakers, and society as a whole. This is because such harmful or abusive content leads to several consequences to people such as physical, emotional, relational, and financial. Among different harmful content \textit{trolling-based} online content is one of them, where the idea is to post a message that is provocative, offensive, or menacing with an intent to mislead the audience. The content can be textual, visual, a combination of both, or a meme. In this study, we provide a comparative analysis of troll-based memes classification using the textual, visual, and multimodal content. We report several interesting findings in terms of code-mixed text, multimodal setting, and combining an additional dataset, which shows improvements over the majority baseline.
Detecting the Role of an Entity in Harmful Memes: Techniques and Their Limitations
May 09, 2022
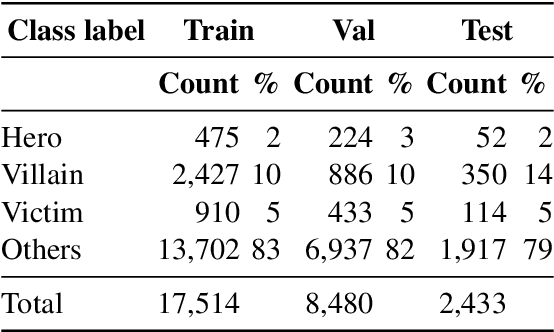

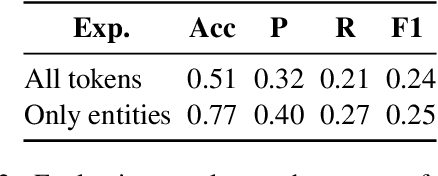
Harmful or abusive online content has been increasing over time, raising concerns for social media platforms, government agencies, and policymakers. Such harmful or abusive content can have major negative impact on society, e.g., cyberbullying can lead to suicides, rumors about COVID-19 can cause vaccine hesitance, promotion of fake cures for COVID-19 can cause health harms and deaths. The content that is posted and shared online can be textual, visual, or a combination of both, e.g., in a meme. Here, we describe our experiments in detecting the roles of the entities (hero, villain, victim) in harmful memes, which is part of the CONSTRAINT-2022 shared task, as well as our system for the task. We further provide a comparative analysis of different experimental settings (i.e., unimodal, multimodal, attention, and augmentation). For reproducibility, we make our experimental code publicly available. \url{https://github.com/robi56/harmful_memes_block_fusion}