 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context-Aware Approach for Detecting Check-Worthy Claims in Political Debates
Paper and Code
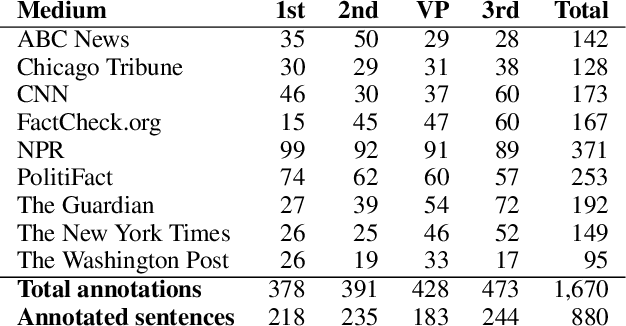
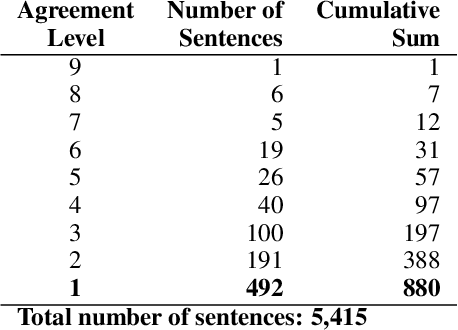

In the context of investigative journalism, we address the problem of automatically identifying which claims in a given document are most worthy and should be prioritized for fact-checking. Despite its importance, this is a relatively understudied problem. Thus, we create a new dataset of political debates, containing statements that have been fact-checked by nine reputable sources, and we train machine learning models to predict which claims should be prioritized for fact-checking, i.e., we model the problem as a ranking task. Unlike previous work, which has looked primarily at sentences in isolation, in this paper we focus on a rich input representation modeling the context: relationship between the target statement and the larger context of the debate, interaction between the opponents, and reaction by the moderator and by the public. Our experiments show state-of-the-art results, outperforming a strong rivaling system by a margin, while also confirming the importance of the contextual information.