 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trainable Saliency Maps in Medical Imaging
Nov 15, 2020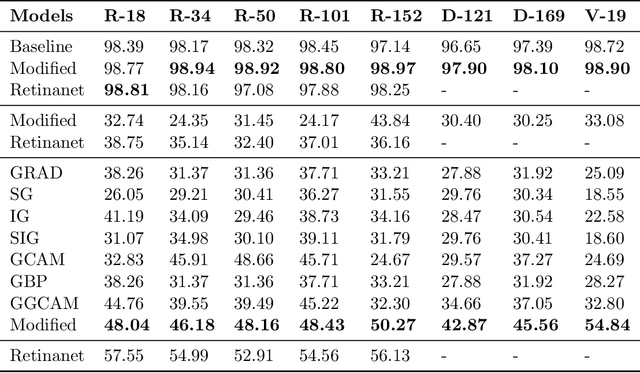
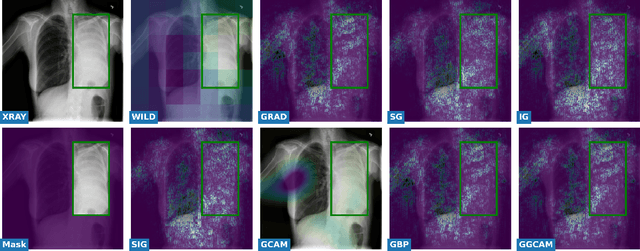
While success of Deep Learning (DL) in automated diagnosis can be transformative to the medicinal practice especially for people with little or no access to doctors, its widespread acceptability is severely limited by inherent black-box decision making and unsafe failure modes. While saliency methods attempt to tackle this problem in non-medical contexts, their apriori explanations do not transfer well to medical usecases. With this study we validate a model design element agnostic to both architecture complexity and model task, and show how introducing this element gives an inherently self-explanatory model. We compare our results with state of the art non-trainable saliency maps on RSNA Pneumonia Dataset and demonstrate a much higher localization efficacy using our adopted technique. We also compare, with a fully supervised baseline and provide a reasonable alternative to it's high data labelling overhead. We further investigate the validity of our claims through qualitative evaluation from an expert reader.
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020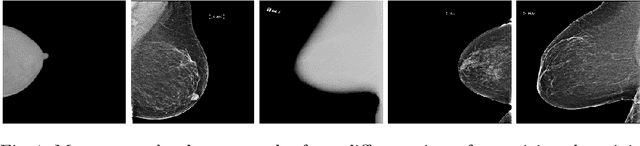

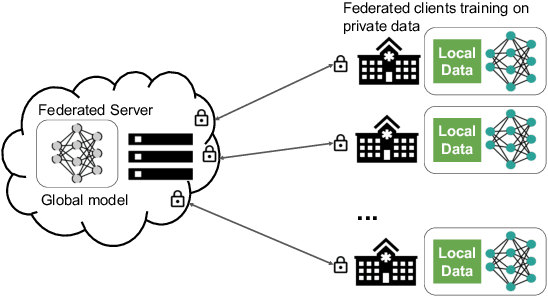
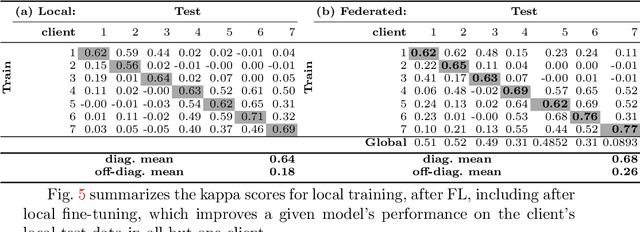
Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Assessing the (Un)Trustworthiness of Saliency Maps for Localizing Abnormalities in Medical Imaging
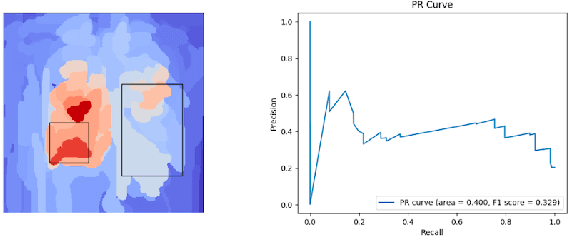
Aug 06, 2020Saliency maps have become a widely used method to make deep learning models more interpretable by providing post-hoc explanations of classifiers through identification of the most pertinent areas of the input medical image. They are increasingly being used in medical imaging to provide clinically plausible explanations for the decisions the neural network makes. However, the utility and robustness of these visualization maps has not yet been rigorously examined in the context of medical imaging. We posit that trustworthiness in this context requires 1) localization utility, 2) sensitivity to model weight randomization, 3) repeatability, and 4) reproducibility. Using the localization information available in two large public radiology datasets, we quantify the performance of eight commonly used saliency map approaches for the above criteria using area under the precision-recall curves (AUPRC) and structural similarity index (SSIM), comparing their performance to various baseline measures. Using our framework to quantify the trustworthiness of saliency maps, we show that all eight saliency map techniques fail at least one of the criteria and are, in most cases, less trustworthy when compared to the baselines. We suggest that their usage in the high-risk domain of medical imaging warrants additional scrutiny and recommend that detection or segmentation models be used if localization is the desired output of the network. Additionally, to promote reproducibility of our findings, we provide the code we used for all tests performed in this work at this link: https://github.com/QTIM-Lab/Assessing-Saliency-Maps.
Assessing the validity of saliency maps for abnormality localization in medical imaging
May 29, 2020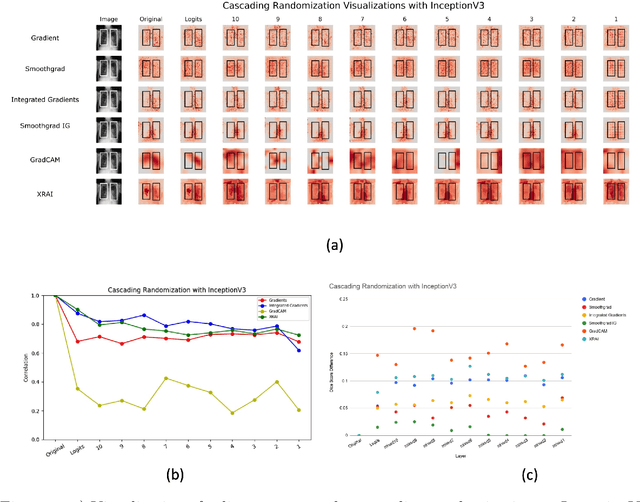
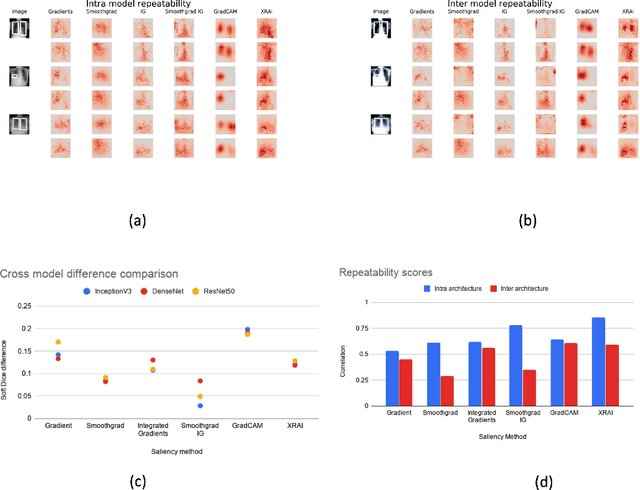
Saliency maps have become a widely used method to assess which areas of the input image are most pertinent to the prediction of a trained neural network. However, in the context of medical imaging, there is no study to our knowledge that has examined the efficacy of these techniques and quantified them using overlap with ground truth bounding boxes. In this work, we explored the credibility of the various existing saliency map methods on the RSNA Pneumonia dataset. We found that GradCAM was the most sensitive to model parameter and label randomization, and was highly agnostic to model architecture.
Give me (un)certainty -- An exploration of parameters that affect segmentation uncertainty
Nov 14, 2019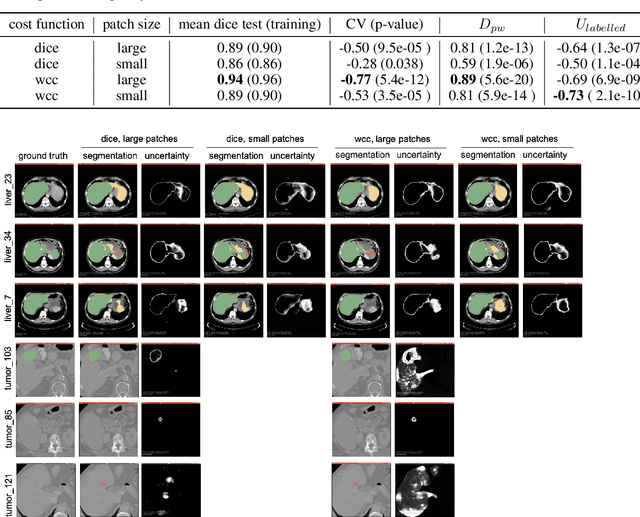
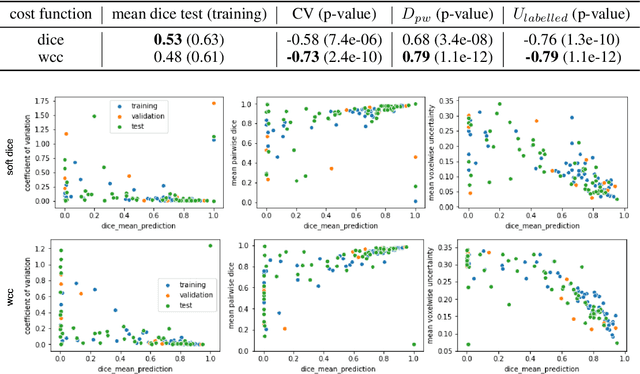
Segmentation tasks in medical imaging are inherently ambiguous: the boundary of a target structure is oftentimes unclear due to image quality and biological factors. As such, predicted segmentations from deep learning algorithms are inherently ambiguous. Additionally, "ground truth" segmentations performed by human annotators are in fact weak labels that further increase the uncertainty of outputs of supervised models developed on these manual labels. To date, most deep learning segmentation studies utilize predicted segmentations without uncertainty quantification. In contrast, we explore the use of Monte Carlo dropout U-Nets for the segmentation with additional quantification of segmentation uncertainty. We assess the utility of three measures of uncertainty (Coefficient of Variation, Mean Pairwise Dice, and Mean Voxelwise Uncertainty) for the segmentation of a less ambiguous target structure (liver) and a more ambiguous one (liver tumors). Furthermore, we assess how the utility of these measures changes with different patch sizes and cost functions. Our results suggest that models trained using larger patches and the weighted categorical cross-entropy as cost function allow the extraction of more meaningful uncertainty measures compared to smaller patches and soft dice loss. Among the three uncertainty measures Mean Pairwise Dice shows the strongest correlation with segmentation quality. Our study serves as a proof-of-concept of how uncertainty measures can be used to assess the quality of a predicted segmentation, potentially serving to flag low quality segmentations from a given model for further human review.
Deep Tone Mapping Operator for High Dynamic Range Images
Aug 12, 2019
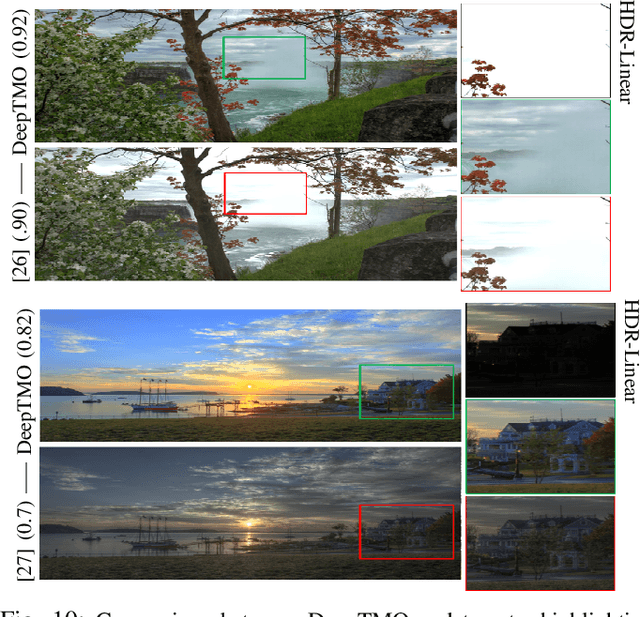
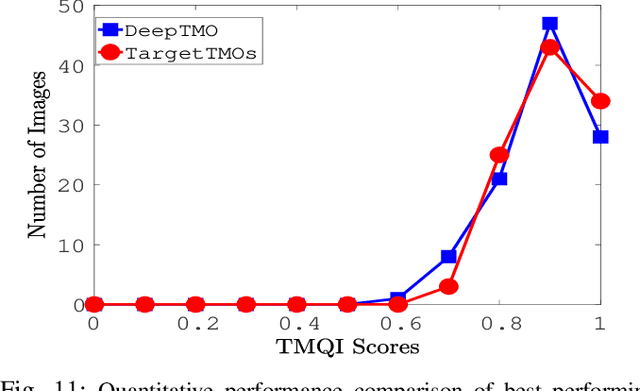
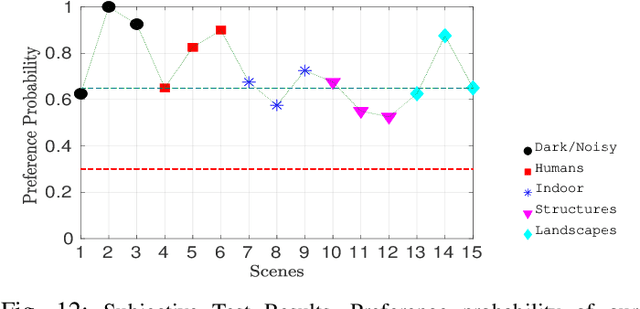
A computationally fast tone mapping operator (TMO) that can quickly adapt to a wide spectrum of high dynamic range (HDR) content is quintessential for visualization on varied low dynamic range (LDR) output devices such as movie screens or standard displays. Existing TMOs can successfully tone-map only a limited number of HDR content and require an extensive parameter tuning to yield the best subjective-quality tone-mapped output. In this paper, we address this problem by proposing a fast, parameter-free and scene-adaptable deep tone mapping operator (DeepTMO) that yields a high-resolution and high-subjective quality tone mapped output. Based on conditional generative adversarial network (cGAN), DeepTMO not only learns to adapt to vast scenic-content (e.g., outdoor, indoor, human, structures, etc.) but also tackles the HDR related scene-specific challenges such as contrast and brightness, while preserving the fine-grained details. We explore 4 possible combinations of Generator-Discriminator architectural designs to specifically address some prominent issues in HDR related deep-learning frameworks like blurring, tiling patterns and saturation artifacts. By exploring different influences of scales, loss-functions and normalization layers under a cGAN setting, we conclude with adopting a multi-scale model for our task. To further leverage on the large-scale availability of unlabeled HDR data, we train our network by generating targets using an objective HDR quality metric, namely Tone Mapping Image Quality Index (TMQI). We demonstrate results both quantitatively and qualitatively, and showcase that our DeepTMO generates high-resolution, high-quality output images over a large spectrum of real-world scenes. Finally, we evaluate the perceived quality of our results by conducting a pair-wise subjective study which confirms the versatility of our method.
Unsupervised Representation Learning by Predicting Image Rotations
Mar 21, 2018



Over the last years, deep convolutional neural networks (ConvNets) have transformed the field of computer vision thanks to their unparalleled capacity to learn high level semantic image features. However, in order to successfully learn those features, they usually require massive amounts of manually labeled data, which is both expensive and impractical to scale. Therefore, unsupervised semantic feature learning, i.e., learning without requiring manual annotation effort, is of crucial importance in order to successfully harvest the vast amount of visual data that are available today. In our work we propose to learn image features by training ConvNets to recognize the 2d rotation that is applied to the image that it gets as input. We demonstrate both qualitatively and quantitatively that this apparently simple task actually provides a very powerful supervisory signal for semantic feature learning. We exhaustively evaluate our method in various unsupervised feature learning benchmarks and we exhibit in all of them state-of-the-art performance. Specifically, our results on those benchmarks demonstrate dramatic improvements w.r.t. prior state-of-the-art approaches in unsupervised representation learning and thus significantly close the gap with supervised feature learning. For instance, in PASCAL VOC 2007 detection task our unsupervised pre-trained AlexNet model achieves the state-of-the-art (among unsupervised methods) mAP of 54.4% that is only 2.4 points lower from the supervised case. We get similarly striking results when we transfer our unsupervised learned features on various other tasks, such as ImageNet classification, PASCAL classification, PASCAL segmentation, and CIFAR-10 classification. The code and models of our paper will be published on: https://github.com/gidariss/FeatureLearningRotNet .