 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Representations for Adaptive Deployment
Jun 01, 2022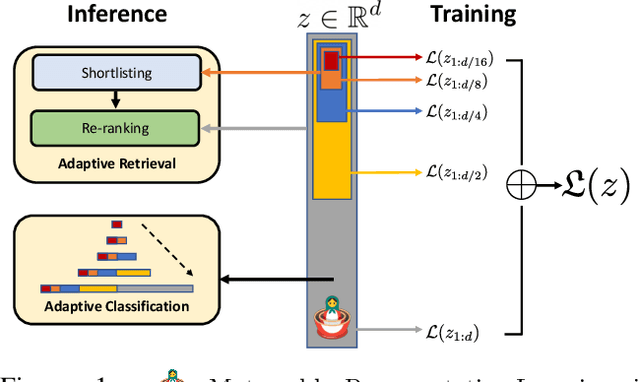
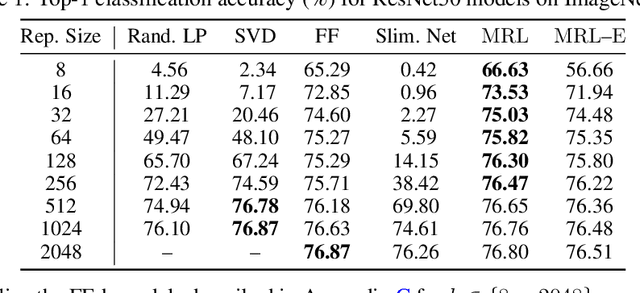
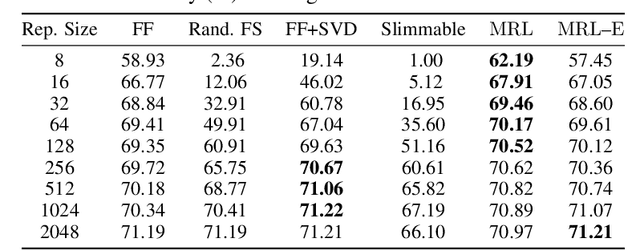
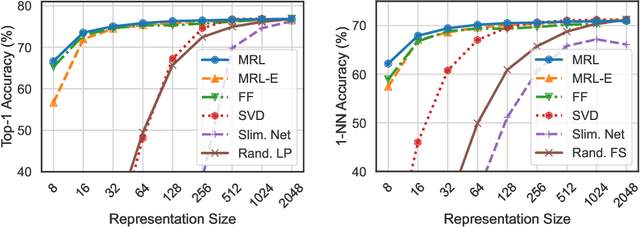
Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and (c) up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities -- vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/RAIVNLab/MRL.
DP-PCA: Statistically Optimal and Differentially Private PCA
May 27, 2022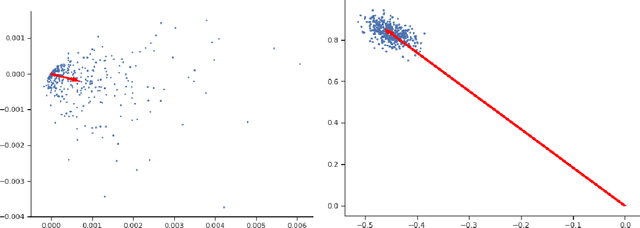
We study the canonical statistical task of computing the principal component from $n$ i.i.d.~data in $d$ dimensions under $(\varepsilon,\delta)$-differential privacy. Although extensively studied in literature, existing solutions fall short on two key aspects: ($i$) even for Gaussian data, existing private algorithms require the number of samples $n$ to scale super-linearly with $d$, i.e., $n=\Omega(d^{3/2})$, to obtain non-trivial results while non-private PCA requires only $n=O(d)$, and ($ii$) existing techniques suffer from a non-vanishing error even when the randomness in each data point is arbitrarily small. We propose DP-PCA, which is a single-pass algorithm that overcomes both limitations. It is based on a private minibatch gradient ascent method that relies on {\em private mean estimation}, which adds minimal noise required to ensure privacy by adapting to the variance of a given minibatch of gradients. For sub-Gaussian data, we provide nearly optimal statistical error rates even for $n=\tilde O(d)$. Furthermore, we provide a lower bound showing that sub-Gaussian style assumption is necessary in obtaining the optimal error rate.
Reproducibility in Optimization: Theoretical Framework and Limits
Feb 09, 2022
We initiate a formal study of reproducibility in optimization. We define a quantitative measure of reproducibility of optimization procedures in the face of noisy or error-prone operations such as inexact or stochastic gradient computations or inexact initialization. We then analyze several convex optimization settings of interest such as smooth, non-smooth, and strongly-convex objective functions and establish tight bounds on the limits of reproducibility in each setting. Our analysis reveals a fundamental trade-off between computation and reproducibility: more computation is necessary (and sufficient) for better reproducibility.
Real-time Recognition of Yoga Poses using computer Vision for Smart Health Care
Jan 19, 2022Nowadays, yoga has become a part of life for many people. Exercises and sports technological assistance is implemented in yoga pose identification. In this work, a self-assistance based yoga posture identification technique is developed, which helps users to perform Yoga with the correction feature in Real-time. The work also presents Yoga-hand mudra (hand gestures) identification. The YOGI dataset has been developed which include 10 Yoga postures with around 400-900 images of each pose and also contain 5 mudras for identification of mudras postures. It contains around 500 images of each mudra. The feature has been extracted by making a skeleton on the body for yoga poses and hand for mudra poses. Two different algorithms have been used for creating a skeleton one for yoga poses and the second for hand mudras. Angles of the joints have been extracted as a features for different machine learning and deep learning models. among all the models XGBoost with RandomSearch CV is most accurate and gives 99.2\% accuracy. The complete design framework is described in the present paper.
Node-Level Differentially Private Graph Neural Networks
Dec 06, 2021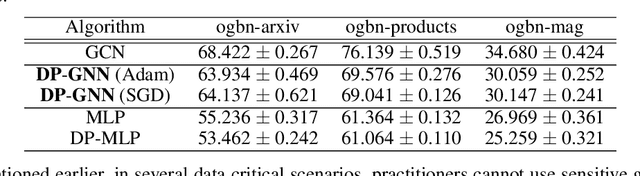
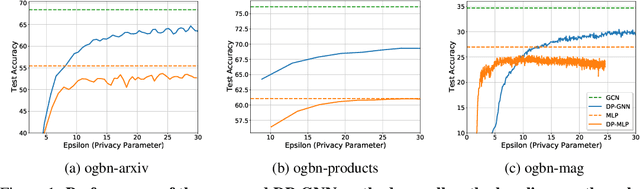
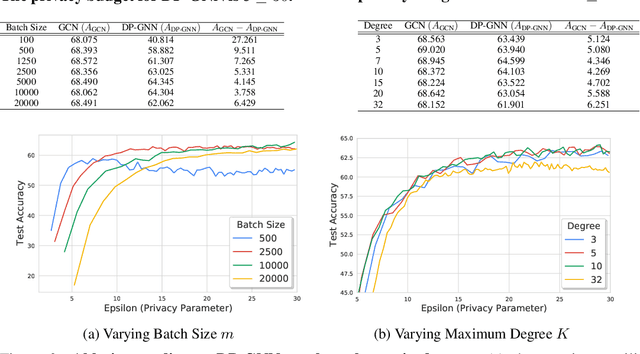
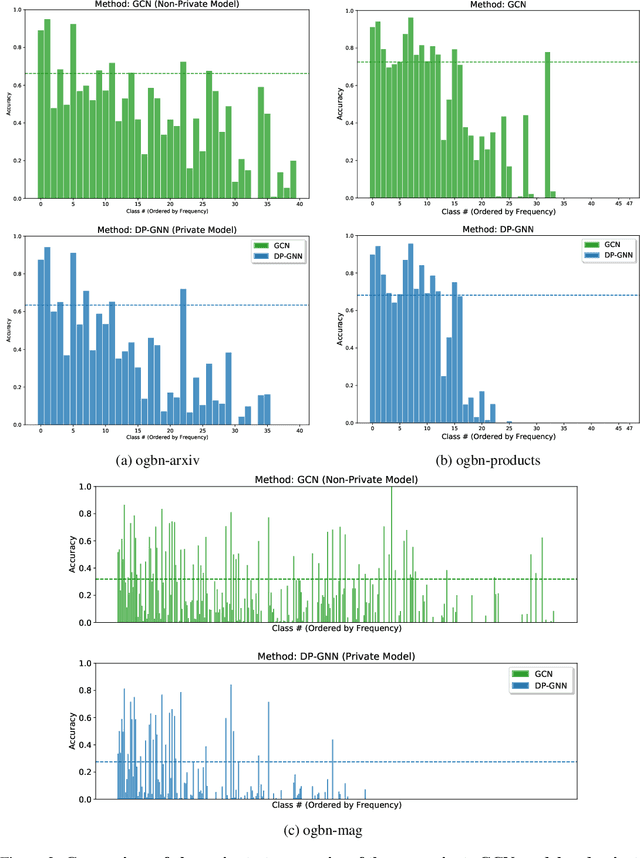
Graph Neural Networks (GNNs) are a popular technique for modelling graph-structured data that compute node-level representations via aggregation of information from the local neighborhood of each node. However, this aggregation implies increased risk of revealing sensitive information, as a node can participate in the inference for multiple nodes. This implies that standard privacy preserving machine learning techniques, such as differentially private stochastic gradient descent (DP-SGD) - which are designed for situations where each data point participates in the inference for one point only - either do not apply, or lead to inaccurate solutions. In this work, we formally define the problem of learning 1-layer GNNs with node-level privacy, and provide an algorithmic solution with a strong differential privacy guarantee. Even though each node can be involved in the inference for multiple nodes, by employing a careful sensitivity analysis anda non-trivial extension of the privacy-by-amplification technique, our method is able to provide accurate solutions with solid privacy parameters. Empirical evaluation on standard benchmarks demonstrates that our method is indeed able to learn accurate privacy preserving GNNs, while still outperforming standard non-private methods that completely ignore graph information.
Online Target Q-learning with Reverse Experience Replay: Efficiently finding the Optimal Policy for Linear MDPs
Oct 19, 2021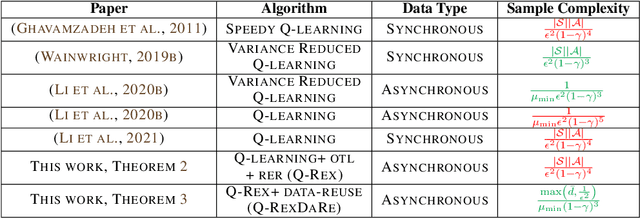
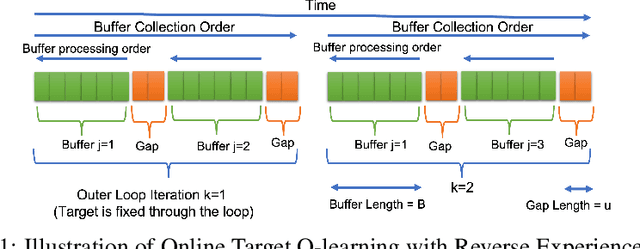

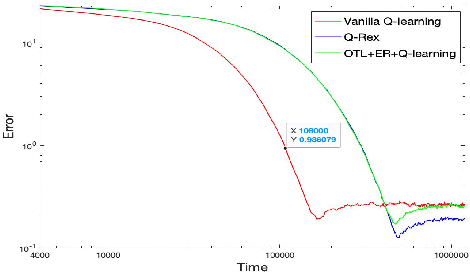
Q-learning is a popular Reinforcement Learning (RL) algorithm which is widely used in practice with function approximation (Mnih et al., 2015). In contrast, existing theoretical results are pessimistic about Q-learning. For example, (Baird, 1995) shows that Q-learning does not converge even with linear function approximation for linear MDPs. Furthermore, even for tabular MDPs with synchronous updates, Q-learning was shown to have sub-optimal sample complexity (Li et al., 2021;Azar et al., 2013). The goal of this work is to bridge the gap between practical success of Q-learning and the relatively pessimistic theoretical results. The starting point of our work is the observation that in practice, Q-learning is used with two important modifications: (i) training with two networks, called online network and target network simultaneously (online target learning, or OTL) , and (ii) experience replay (ER) (Mnih et al., 2015). While they have been observed to play a significant role in the practical success of Q-learning, a thorough theoretical understanding of how these two modifications improve the convergence behavior of Q-learning has been missing in literature. By carefully combining Q-learning with OTL and reverse experience replay (RER) (a form of experience replay), we present novel methods Q-Rex and Q-RexDaRe (Q-Rex + data reuse). We show that Q-Rex efficiently finds the optimal policy for linear MDPs (or more generally for MDPs with zero inherent Bellman error with linear approximation (ZIBEL)) and provide non-asymptotic bounds on sample complexity -- the first such result for a Q-learning method for this class of MDPs under standard assumptions. Furthermore, we demonstrate that Q-RexDaRe in fact achieves near optimal sample complexity in the tabular setting, improving upon the existing results for vanilla Q-learning.
Neural Network Compatible Off-Policy Natural Actor-Critic Algorithm
Oct 19, 2021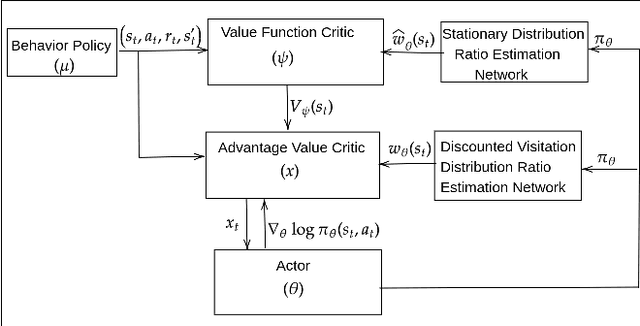

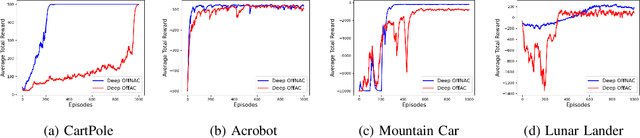
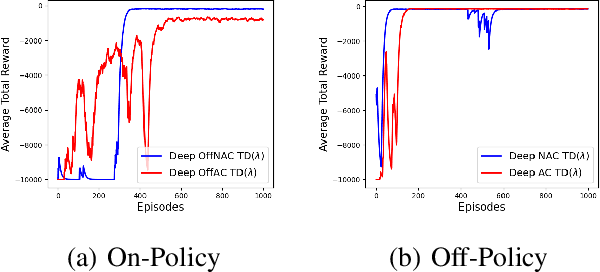
Learning optimal behavior from existing data is one of the most important problems in Reinforcement Learning (RL). This is known as "off-policy control" in RL where an agent's objective is to compute an optimal policy based on the data obtained from the given policy (known as the behavior policy). As the optimal policy can be very different from the behavior policy, learning optimal behavior is very hard in the "off-policy" setting compared to the "on-policy" setting where new data from the policy updates will be utilized in learning. This work proposes an off-policy natural actor-critic algorithm that utilizes state-action distribution correction for handling the off-policy behavior and the natural policy gradient for sample efficiency. The existing natural gradient-based actor-critic algorithms with convergence guarantees require fixed features for approximating both policy and value functions. This often leads to sub-optimal learning in many RL applications. On the other hand, our proposed algorithm utilizes compatible features that enable one to use arbitrary neural networks to approximate the policy and the value function and guarantee convergence to a locally optimal policy. We illustrate the benefit of the proposed off-policy natural gradient algorithm by comparing it with the vanilla gradient actor-critic algorithm on benchmark RL tasks.
IGLU: Efficient GCN Training via Lazy Updates
Sep 28, 2021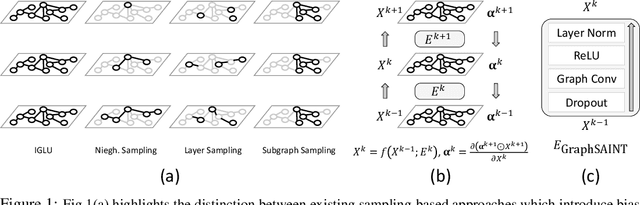
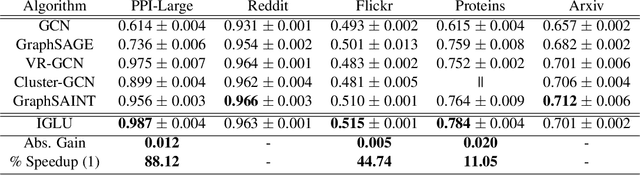
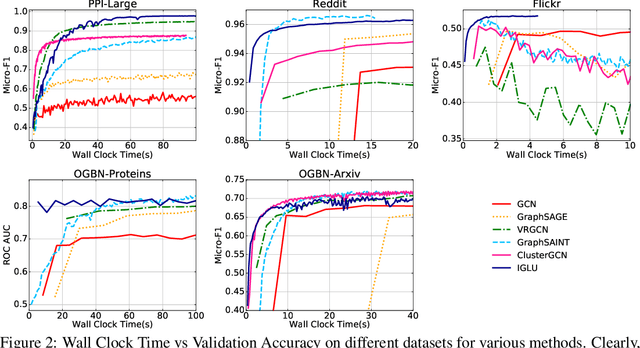

Graph Convolution Networks (GCN) are used in numerous settings involving a large underlying graph as well as several layers. Standard SGD-based training scales poorly here since each descent step ends up updating node embeddings for a large portion of the graph. Recent methods attempt to remedy this by sub-sampling the graph which does reduce the compute load, but at the cost of biased gradients which may offer suboptimal performance. In this work we introduce a new method IGLU that caches forward-pass embeddings for all nodes at various GCN layers. This enables IGLU to perform lazy updates that do not require updating a large number of node embeddings during descent which offers much faster convergence but does not significantly bias the gradients. Under standard assumptions such as objective smoothness, IGLU provably converges to a first-order saddle point. We validate IGLU extensively on a variety of benchmarks, where it offers up to 1.2% better accuracy despite requiring up to 88% less wall-clock time.
Private Alternating Least Squares: Practical Private Matrix Completion with Tighter Rates
Jul 20, 2021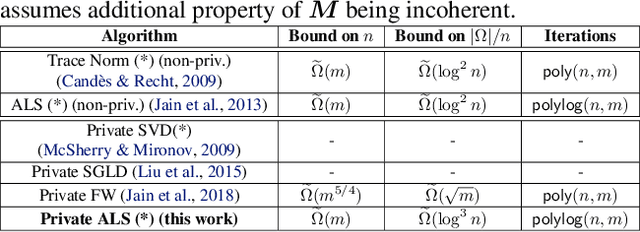
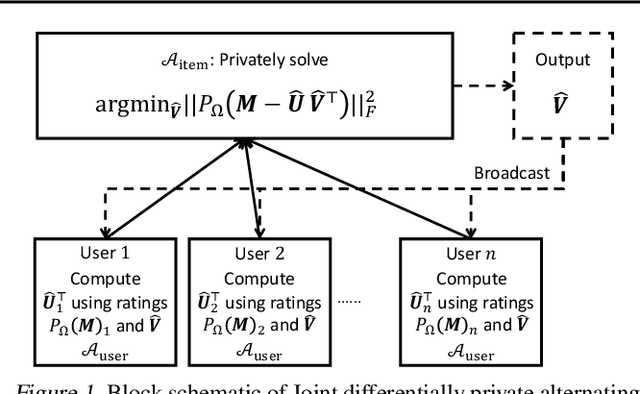
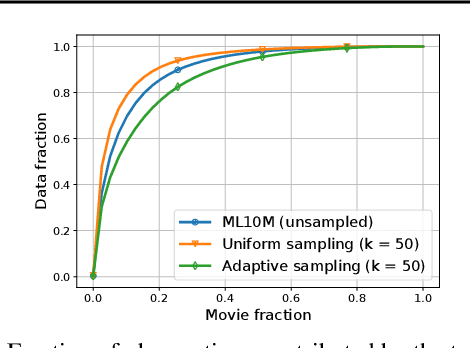
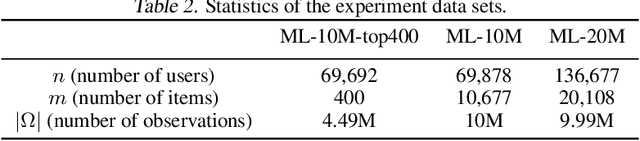
We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021
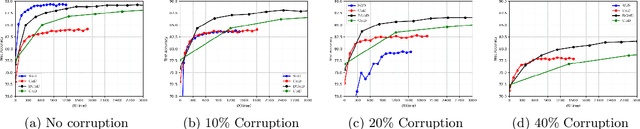
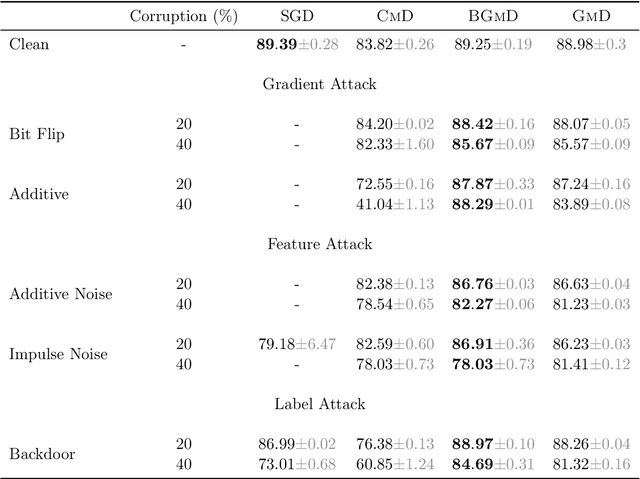
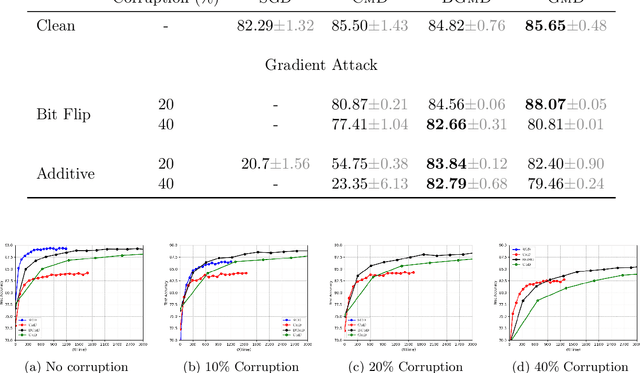
Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.