 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging External Knowledge Resources to Enable Domain-Specific Comprehension
Jan 15, 2024



Machine Reading Comprehension (MRC) has been a long-standing problem in NLP and, with the recent introduction of the BERT family of transformer based language models, it has come a long way to getting solved. Unfortunately, however, when BERT variants trained on general text corpora are applied to domain-specific text, their performance inevitably degrades on account of the domain shift i.e. genre/subject matter discrepancy between the training and downstream application data. Knowledge graphs act as reservoirs for either open or closed domain information and prior studies have shown that they can be used to improve the performance of general-purpose transformers in domain-specific applications. Building on existing work, we introduce a method using Multi-Layer Perceptrons (MLPs) for aligning and integrating embeddings extracted from knowledge graphs with the embeddings spaces of pre-trained language models (LMs). We fuse the aligned embeddings with open-domain LMs BERT and RoBERTa, and fine-tune them for two MRC tasks namely span detection (COVID-QA) and multiple-choice questions (PubMedQA). On the COVID-QA dataset, we see that our approach allows these models to perform similar to their domain-specific counterparts, Bio/Sci-BERT, as evidenced by the Exact Match (EM) metric. With regards to PubMedQA, we observe an overall improvement in accuracy while the F1 stays relatively the same over the domain-specific models.
WildGEN: Long-horizon Trajectory Generation for Wildlife
Dec 30, 2023Trajectory generation is an important concern in pedestrian, vehicle, and wildlife movement studies. Generated trajectories help enrich the training corpus in relation to deep learning applications, and may be used to facilitate simulation tasks. This is especially significant in the wildlife domain, where the cost of obtaining additional real data can be prohibitively expensive, time-consuming, and bear ethical considerations. In this paper, we introduce WildGEN: a conceptual framework that addresses this challenge by employing a Variational Auto-encoders (VAEs) based method for the acquisition of movement characteristics exhibited by wild geese over a long horizon using a sparse set of truth samples. A subsequent post-processing step of the generated trajectories is performed based on smoothing filters to reduce excessive wandering. Our evaluation is conducted through visual inspection and the computation of the Hausdorff distance between the generated and real trajectories. In addition, we utilize the Pearson Correlation Coefficient as a way to measure how realistic the trajectories are based on the similarity of clusters evaluated on the generated and real trajectories.
FaMeSumm: Investigating and Improving Faithfulness of Medical Summarization
Nov 08, 2023



Summaries of medical text shall be faithful by being consistent and factual with source inputs, which is an important but understudied topic for safety and efficiency in healthcare. In this paper, we investigate and improve faithfulness in summarization on a broad range of medical summarization tasks. Our investigation reveals that current summarization models often produce unfaithful outputs for medical input text. We then introduce FaMeSumm, a framework to improve faithfulness by fine-tuning pre-trained language models based on medical knowledge. FaMeSumm performs contrastive learning on designed sets of faithful and unfaithful summaries, and it incorporates medical terms and their contexts to encourage faithful generation of medical terms. We conduct comprehensive experiments on three datasets in two languages: health question and radiology report summarization datasets in English, and a patient-doctor dialogue dataset in Chinese. Results demonstrate that FaMeSumm is flexible and effective by delivering consistent improvements over mainstream language models such as BART, T5, mT5, and PEGASUS, yielding state-of-the-art performances on metrics for faithfulness and general quality. Human evaluation by doctors also shows that FaMeSumm generates more faithful outputs. Our code is available at https://github.com/psunlpgroup/FaMeSumm .
Quality > Quantity: Synthetic Corpora from Foundation Models for Closed-Domain Extractive Question Answering
Oct 25, 2023



Domain adaptation, the process of training a model in one domain and applying it to another, has been extensively explored in machine learning. While training a domain-specific foundation model (FM) from scratch is an option, recent methods have focused on adapting pre-trained FMs for domain-specific tasks. However, our experiments reveal that either approach does not consistently achieve state-of-the-art (SOTA) results in the target domain. In this work, we study extractive question answering within closed domains and introduce the concept of targeted pre-training. This involves determining and generating relevant data to further pre-train our models, as opposed to the conventional philosophy of utilizing domain-specific FMs trained on a wide range of data. Our proposed framework uses Galactica to generate synthetic, ``targeted'' corpora that align with specific writing styles and topics, such as research papers and radiology reports. This process can be viewed as a form of knowledge distillation. We apply our method to two biomedical extractive question answering datasets, COVID-QA and RadQA, achieving a new benchmark on the former and demonstrating overall improvements on the latter. Code available at https://github.com/saptarshi059/CDQA-v1-Targetted-PreTraining/tree/main.
Analysis of Elephant Movement in Sub-Saharan Africa: Ecological, Climatic, and Conservation Perspectives
Jul 21, 2023The interaction between elephants and their environment has profound implications for both ecology and conservation strategies. This study presents an analytical approach to decipher the intricate patterns of elephant movement in Sub-Saharan Africa, concentrating on key ecological drivers such as seasonal variations and rainfall patterns. Despite the complexities surrounding these influential factors, our analysis provides a holistic view of elephant migratory behavior in the context of the dynamic African landscape. Our comprehensive approach enables us to predict the potential impact of these ecological determinants on elephant migration, a critical step in establishing informed conservation strategies. This projection is particularly crucial given the impacts of global climate change on seasonal and rainfall patterns, which could substantially influence elephant movements in the future. The findings of our work aim to not only advance the understanding of movement ecology but also foster a sustainable coexistence of humans and elephants in Sub-Saharan Africa. By predicting potential elephant routes, our work can inform strategies to minimize human-elephant conflict, effectively manage land use, and enhance anti-poaching efforts. This research underscores the importance of integrating movement ecology and climatic variables for effective wildlife management and conservation planning.
Spatio-temporal Storytelling? Leveraging Generative Models for Semantic Trajectory Analysis
Jun 24, 2023
In this paper, we lay out a vision for analysing semantic trajectory traces and generating synthetic semantic trajectory data (SSTs) using generative language model. Leveraging the advancements in deep learning, as evident by progress in the field of natural language processing (NLP), computer vision, etc. we intend to create intelligent models that can study the semantic trajectories in various contexts, predicting future trends, increasing machine understanding of the movement of animals, humans, goods, etc. enhancing human-computer interactions, and contributing to an array of applications ranging from urban-planning to personalized recommendation engines and business strategy.
Lumos in the Night Sky: AI-enabled Visual Tool for Exploring Night-Time Light Patterns
Jun 05, 2023

We introduce NightPulse, an interactive tool for Night-time light (NTL) data visualization and analytics, which enables researchers and stakeholders to explore and analyze NTL data with a user-friendly platform. Powered by efficient system architecture, NightPulse supports image segmentation, clustering, and change pattern detection to identify urban development and sprawl patterns. It captures temporal trends of NTL and semantics of cities, answering questions about demographic factors, city boundaries, and unusual differences.
Forecasting User Interests Through Topic Tag Predictions in Online Health Communities
Nov 05, 2022The increasing reliance on online communities for healthcare information by patients and caregivers has led to the increase in the spread of misinformation, or subjective, anecdotal and inaccurate or non-specific recommendations, which, if acted on, could cause serious harm to the patients. Hence, there is an urgent need to connect users with accurate and tailored health information in a timely manner to prevent such harm. This paper proposes an innovative approach to suggesting reliable information to participants in online communities as they move through different stages in their disease or treatment. We hypothesize that patients with similar histories of disease progression or course of treatment would have similar information needs at comparable stages. Specifically, we pose the problem of predicting topic tags or keywords that describe the future information needs of users based on their profiles, traces of their online interactions within the community (past posts, replies) and the profiles and traces of online interactions of other users with similar profiles and similar traces of past interaction with the target users. The result is a variant of the collaborative information filtering or recommendation system tailored to the needs of users of online health communities. We report results of our experiments on an expert curated data set which demonstrate the superiority of the proposed approach over the state of the art baselines with respect to accurate and timely prediction of topic tags (and hence information sources of interest).
Recognition of Implicit Geographic Movement in Text
Jan 30, 2022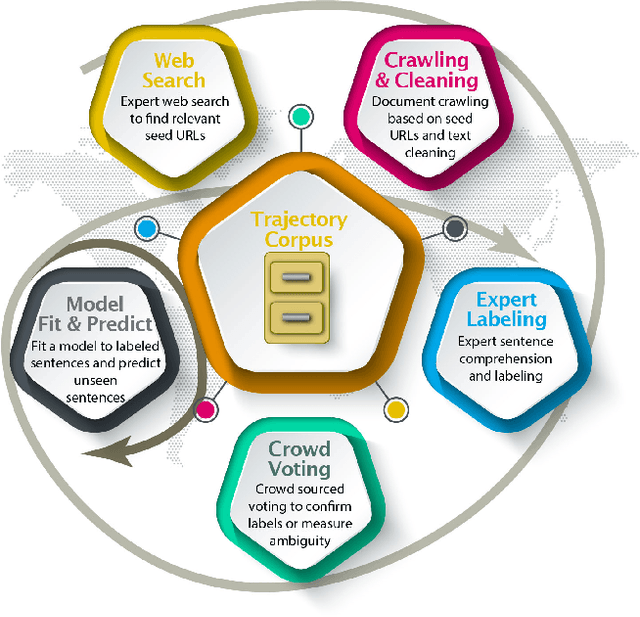
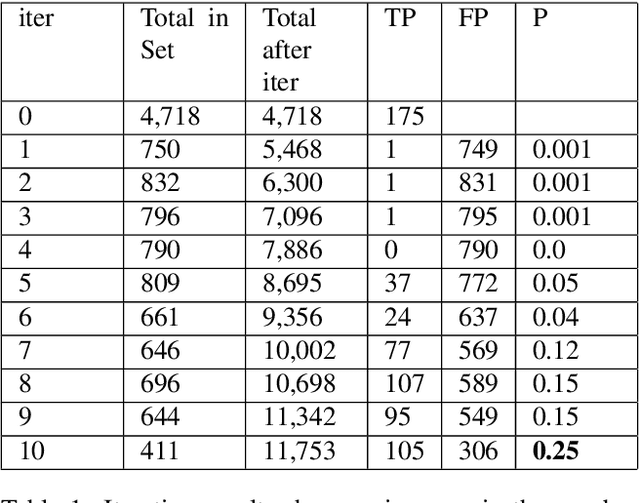

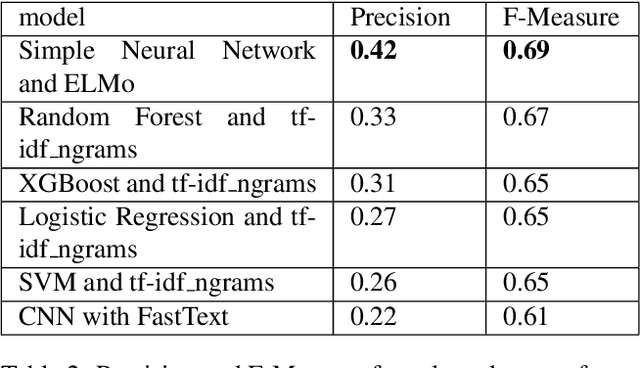
Analyzing the geographic movement of humans, animals, and other phenomena is a growing field of research. This research has benefited urban planning, logistics, animal migration understanding, and much more. Typically, the movement is captured as precise geographic coordinates and time stamps with Global Positioning Systems (GPS). Although some research uses computational techniques to take advantage of implicit movement in descriptions of route directions, hiking paths, and historical exploration routes, innovation would accelerate with a large and diverse corpus. We created a corpus of sentences labeled as describing geographic movement or not and including the type of entity moving. Creating this corpus proved difficult without any comparable corpora to start with, high human labeling costs, and since movement can at times be interpreted differently. To overcome these challenges, we developed an iterative process employing hand labeling, crowd voting for confirmation, and machine learning to predict more labels. By merging advances in word embeddings with traditional machine learning models and model ensembling, prediction accuracy is at an acceptable level to produce a large silver-standard corpus despite the small gold-standard corpus training set. Our corpus will likely benefit computational processing of geography in text and spatial cognition, in addition to detection of movement.
Federated Unlearning with Knowledge Distillation
Jan 24, 2022

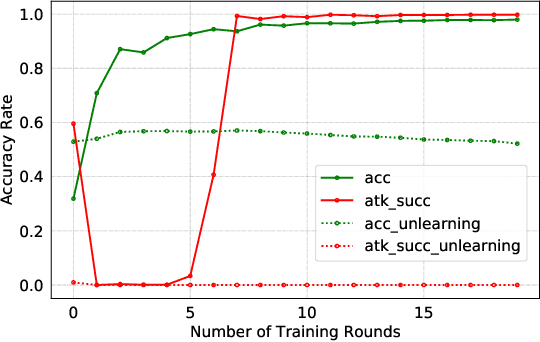
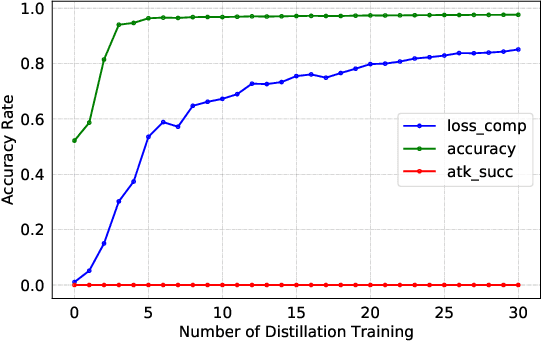
Federated Learning (FL) is designed to protect the data privacy of each client during the training process by transmitting only models instead of the original data. However, the trained model may memorize certain information about the training data. With the recent legislation on right to be forgotten, it is crucially essential for the FL model to possess the ability to forget what it has learned from each client. We propose a novel federated unlearning method to eliminate a client's contribution by subtracting the accumulated historical updates from the model and leveraging the knowledge distillation method to restore the model's performance without using any data from the clients. This method does not have any restrictions on the type of neural networks and does not rely on clients' participation, so it is practical and efficient in the FL system. We further introduce backdoor attacks in the training process to help evaluate the unlearning effect. Experiments on three canonical datasets demonstrate the effectiveness and efficiency of our method.