 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeytopt: Autotuning Scientific Applications for Energy Efficiency at Large Scales
Mar 28, 2023



As we enter the exascale computing era, efficiently utilizing power and optimizing the performance of scientific applications under power and energy constraints has become critical and challenging. We propose a low-overhead autotuning framework to autotune performance and energy for various hybrid MPI/OpenMP scientific applications at large scales and to explore the tradeoffs between application runtime and power/energy for energy efficient application execution, then use this framework to autotune four ECP proxy applications -- XSBench, AMG, SWFFT, and SW4lite. Our approach uses Bayesian optimization with a Random Forest surrogate model to effectively search parameter spaces with up to 6 million different configurations on two large-scale production systems, Theta at Argonne National Laboratory and Summit at Oak Ridge National Laboratory. The experimental results show that our autotuning framework at large scales has low overhead and achieves good scalability. Using the proposed autotuning framework to identify the best configurations, we achieve up to 91.59% performance improvement, up to 21.2% energy savings, and up to 37.84% EDP improvement on up to 4,096 nodes.
Application of probabilistic modeling and automated machine learning framework for high-dimensional stress field
Mar 15, 2023



Modern computational methods, involving highly sophisticated mathematical formulations, enable several tasks like modeling complex physical phenomenon, predicting key properties and design optimization. The higher fidelity in these computer models makes it computationally intensive to query them hundreds of times for optimization and one usually relies on a simplified model albeit at the cost of losing predictive accuracy and precision. Towards this, data-driven surrogate modeling methods have shown a lot of promise in emulating the behavior of the expensive computer models. However, a major bottleneck in such methods is the inability to deal with high input dimensionality and the need for relatively large datasets. With such problems, the input and output quantity of interest are tensors of high dimensionality. Commonly used surrogate modeling methods for such problems, suffer from requirements like high number of computational evaluations that precludes one from performing other numerical tasks like uncertainty quantification and statistical analysis. In this work, we propose an end-to-end approach that maps a high-dimensional image like input to an output of high dimensionality or its key statistics. Our approach uses two main framework that perform three steps: a) reduce the input and output from a high-dimensional space to a reduced or low-dimensional space, b) model the input-output relationship in the low-dimensional space, and c) enable the incorporation of domain-specific physical constraints as masks. In order to accomplish the task of reducing input dimensionality we leverage principal component analysis, that is coupled with two surrogate modeling methods namely: a) Bayesian hybrid modeling, and b) DeepHyper's deep neural networks. We demonstrate the applicability of the approach on a problem of a linear elastic stress field data.
Quantifying uncertainty for deep learning based forecasting and flow-reconstruction using neural architecture search ensembles
Feb 20, 2023



Classical problems in computational physics such as data-driven forecasting and signal reconstruction from sparse sensors have recently seen an explosion in deep neural network (DNN) based algorithmic approaches. However, most DNN models do not provide uncertainty estimates, which are crucial for establishing the trustworthiness of these techniques in downstream decision making tasks and scenarios. In recent years, ensemble-based methods have achieved significant success for the uncertainty quantification in DNNs on a number of benchmark problems. However, their performance on real-world applications remains under-explored. In this work, we present an automated approach to DNN discovery and demonstrate how this may also be utilized for ensemble-based uncertainty quantification. Specifically, we propose the use of a scalable neural and hyperparameter architecture search for discovering an ensemble of DNN models for complex dynamical systems. We highlight how the proposed method not only discovers high-performing neural network ensembles for our tasks, but also quantifies uncertainty seamlessly. This is achieved by using genetic algorithms and Bayesian optimization for sampling the search space of neural network architectures and hyperparameters. Subsequently, a model selection approach is used to identify candidate models for an ensemble set construction. Afterwards, a variance decomposition approach is used to estimate the uncertainty of the predictions from the ensemble. We demonstrate the feasibility of this framework for two tasks - forecasting from historical data and flow reconstruction from sparse sensors for the sea-surface temperature. We demonstrate superior performance from the ensemble in contrast with individual high-performing models and other benchmarks.
Analyzing the impact of climate change on critical infrastructure from the scientific literature: A weakly supervised NLP approach
Feb 06, 2023



Natural language processing (NLP) is a promising approach for analyzing large volumes of climate-change and infrastructure-related scientific literature. However, best-in-practice NLP techniques require large collections of relevant documents (corpus). Furthermore, NLP techniques using machine learning and deep learning techniques require labels grouping the articles based on user-defined criteria for a significant subset of a corpus in order to train the supervised model. Even labeling a few hundred documents with human subject-matter experts is a time-consuming process. To expedite this process, we developed a weak supervision-based NLP approach that leverages semantic similarity between categories and documents to (i) establish a topic-specific corpus by subsetting a large-scale open-access corpus and (ii) generate category labels for the topic-specific corpus. In comparison with a months-long process of subject-matter expert labeling, we assign category labels to the whole corpus using weak supervision and supervised learning in about 13 hours. The labeled climate and NCF corpus enable targeted, efficient identification of documents discussing a topic (or combination of topics) of interest and identification of various effects of climate change on critical infrastructure, improving the usability of scientific literature and ultimately supporting enhanced policy and decision making. To demonstrate this capability, we conduct topic modeling on pairs of climate hazards and NCFs to discover trending topics at the intersection of these categories. This method is useful for analysts and decision-makers to quickly grasp the relevant topics and most important documents linked to the topic.
Unified Probabilistic Neural Architecture and Weight Ensembling Improves Model Robustness
Oct 08, 2022

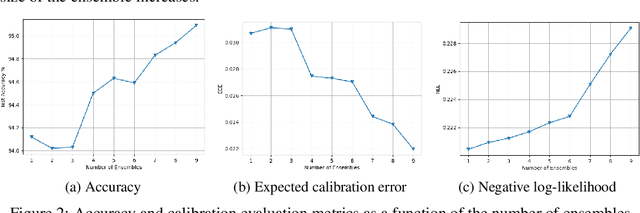
Robust machine learning models with accurately calibrated uncertainties are crucial for safety-critical applications. Probabilistic machine learning and especially the Bayesian formalism provide a systematic framework to incorporate robustness through the distributional estimates and reason about uncertainty. Recent works have shown that approximate inference approaches that take the weight space uncertainty of neural networks to generate ensemble prediction are the state-of-the-art. However, architecture choices have mostly been ad hoc, which essentially ignores the epistemic uncertainty from the architecture space. To this end, we propose a Unified probabilistic architecture and weight ensembling Neural Architecture Search (UraeNAS) that leverages advances in probabilistic neural architecture search and approximate Bayesian inference to generate ensembles form the joint distribution of neural network architectures and weights. The proposed approach showed a significant improvement both with in-distribution (0.86% in accuracy, 42% in ECE) CIFAR-10 and out-of-distribution (2.43% in accuracy, 30% in ECE) CIFAR-10-C compared to the baseline deterministic approach.
HPC Storage Service Autotuning Using Variational-Autoencoder-Guided Asynchronous Bayesian Optimization
Oct 03, 2022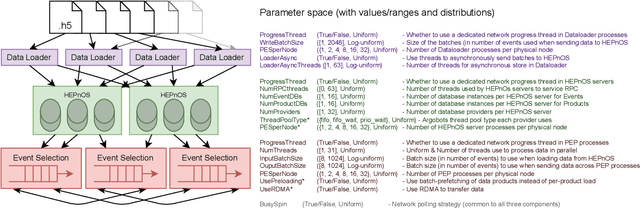
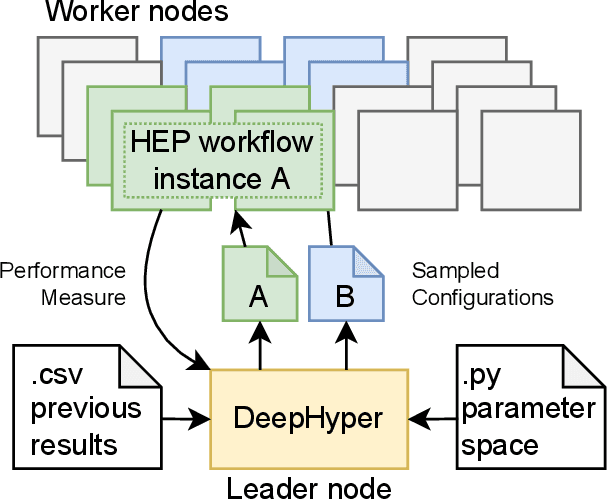
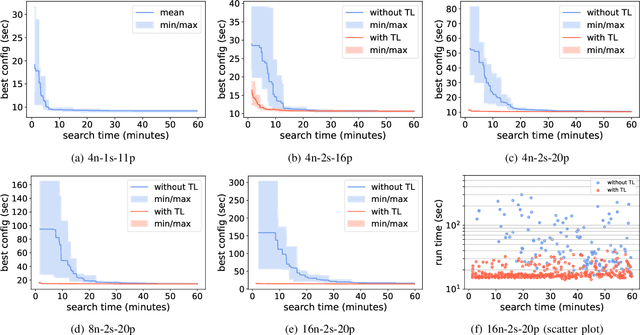
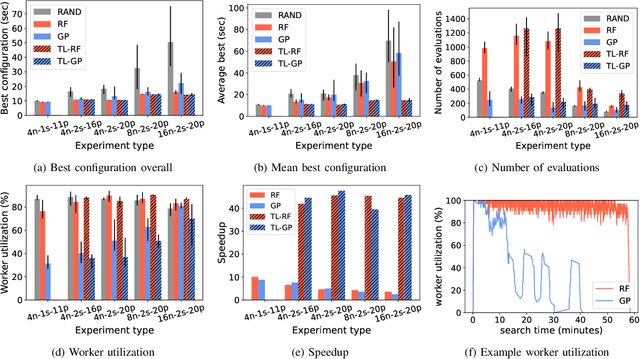
Distributed data storage services tailored to specific applications have grown popular in the high-performance computing (HPC) community as a way to address I/O and storage challenges. These services offer a variety of specific interfaces, semantics, and data representations. They also expose many tuning parameters, making it difficult for their users to find the best configuration for a given workload and platform. To address this issue, we develop a novel variational-autoencoder-guided asynchronous Bayesian optimization method to tune HPC storage service parameters. Our approach uses transfer learning to leverage prior tuning results and use a dynamically updated surrogate model to explore the large parameter search space in a systematic way. We implement our approach within the DeepHyper open-source framework, and apply it to the autotuning of a high-energy physics workflow on Argonne's Theta supercomputer. We show that our transfer-learning approach enables a more than $40\times$ search speedup over random search, compared with a $2.5\times$ to $10\times$ speedup when not using transfer learning. Additionally, we show that our approach is on par with state-of-the-art autotuning frameworks in speed and outperforms them in resource utilization and parallelization capabilities.
Explainable Graph Pyramid Autoformer for Long-Term Traffic Forecasting
Sep 27, 2022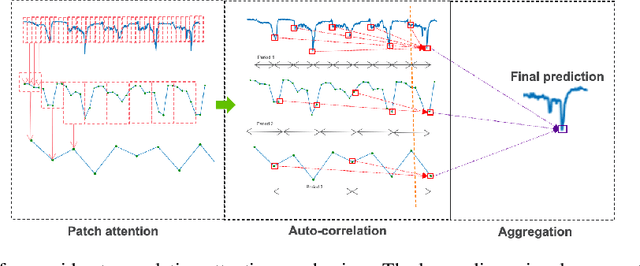
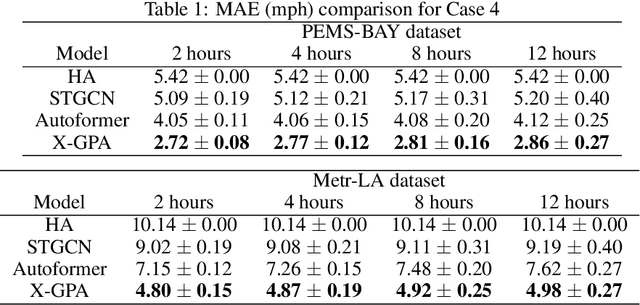
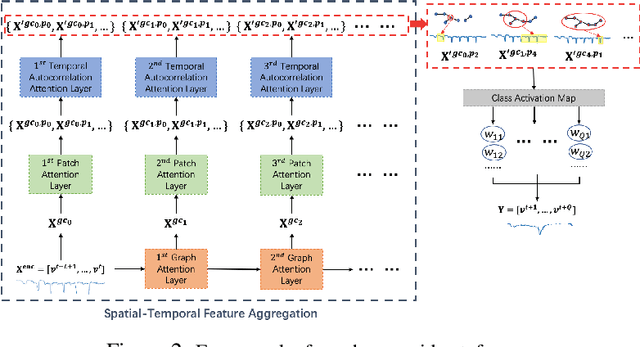
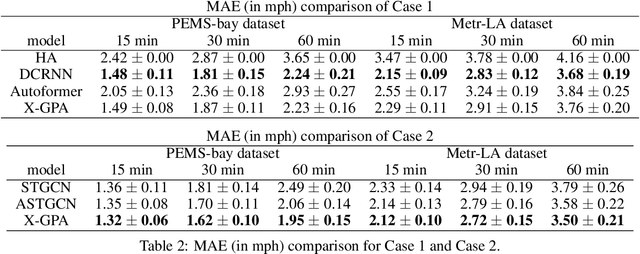
Accurate traffic forecasting is vital to an intelligent transportation system. Although many deep learning models have achieved state-of-art performance for short-term traffic forecasting of up to 1 hour, long-term traffic forecasting that spans multiple hours remains a major challenge. Moreover, most of the existing deep learning traffic forecasting models are black box, presenting additional challenges related to explainability and interpretability. We develop Graph Pyramid Autoformer (X-GPA), an explainable attention-based spatial-temporal graph neural network that uses a novel pyramid autocorrelation attention mechanism. It enables learning from long temporal sequences on graphs and improves long-term traffic forecasting accuracy. Our model can achieve up to 35 % better long-term traffic forecast accuracy than that of several state-of-the-art methods. The attention-based scores from the X-GPA model provide spatial and temporal explanations based on the traffic dynamics, which change for normal vs. peak-hour traffic and weekday vs. weekend traffic.
Asynchronous Distributed Bayesian Optimization at HPC Scale
Jul 04, 2022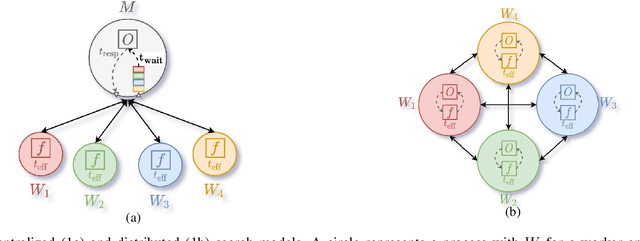
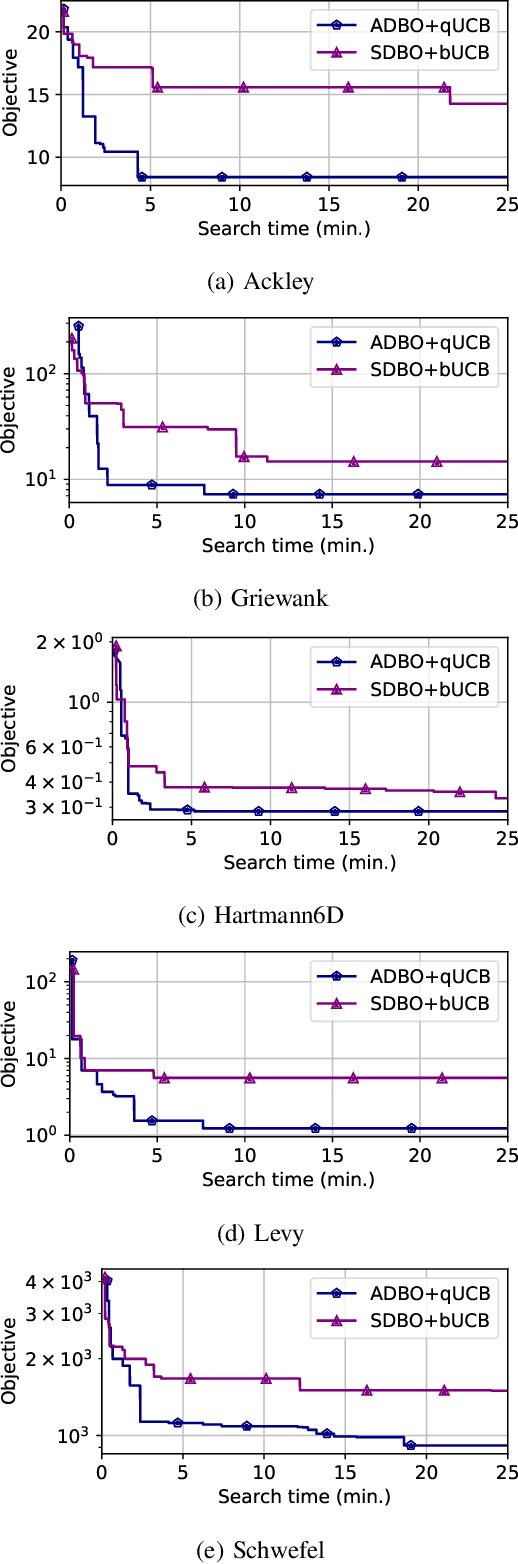
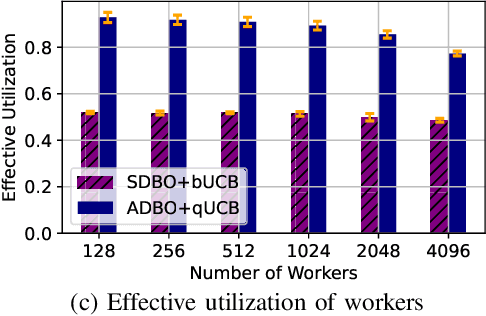

Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.
Multifidelity Reinforcement Learning with Control Variates
Jun 10, 2022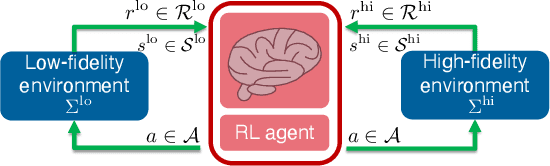
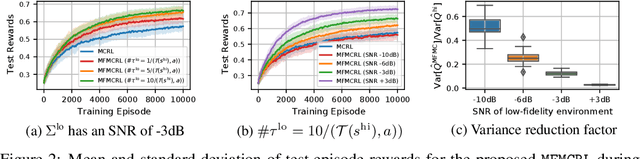
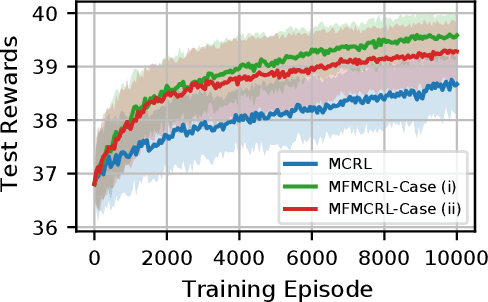
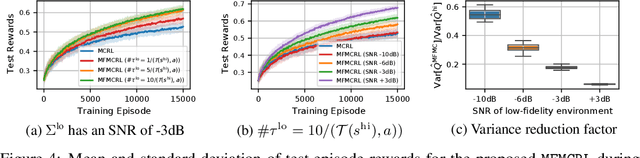
In many computational science and engineering applications, the output of a system of interest corresponding to a given input can be queried at different levels of fidelity with different costs. Typically, low-fidelity data is cheap and abundant, while high-fidelity data is expensive and scarce. In this work we study the reinforcement learning (RL) problem in the presence of multiple environments with different levels of fidelity for a given control task. We focus on improving the RL agent's performance with multifidelity data. Specifically, a multifidelity estimator that exploits the cross-correlations between the low- and high-fidelity returns is proposed to reduce the variance in the estimation of the state-action value function. The proposed estimator, which is based on the method of control variates, is used to design a multifidelity Monte Carlo RL (MFMCRL) algorithm that improves the learning of the agent in the high-fidelity environment. The impacts of variance reduction on policy evaluation and policy improvement are theoretically analyzed by using probability bounds. Our theoretical analysis and numerical experiments demonstrate that for a finite budget of high-fidelity data samples, our proposed MFMCRL agent attains superior performance compared with that of a standard RL agent that uses only the high-fidelity environment data for learning the optimal policy.
Sequential Bayesian Neural Subnetwork Ensembles
Jun 01, 2022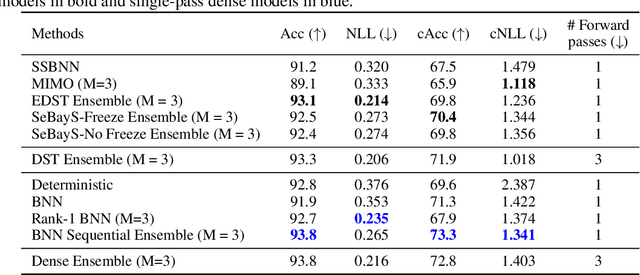
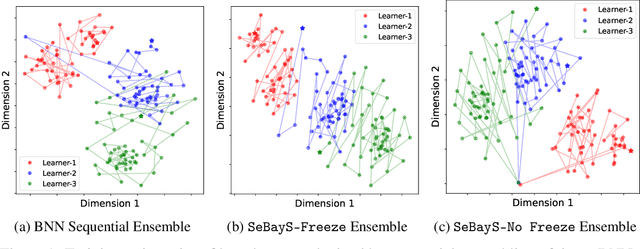
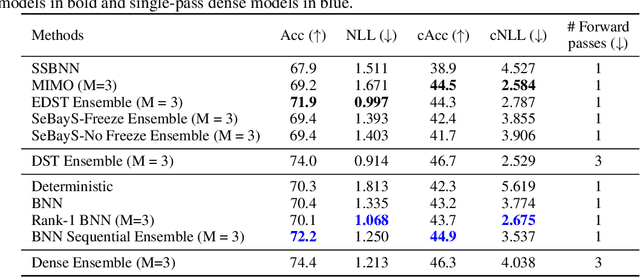
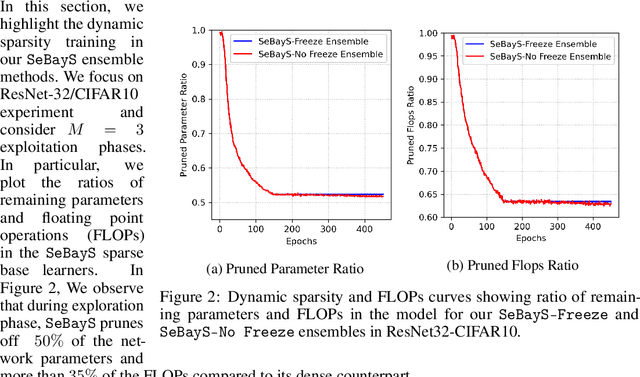
Deep neural network ensembles that appeal to model diversity have been used successfully to improve predictive performance and model robustness in several applications. Whereas, it has recently been shown that sparse subnetworks of dense models can match the performance of their dense counterparts and increase their robustness while effectively decreasing the model complexity. However, most ensembling techniques require multiple parallel and costly evaluations and have been proposed primarily with deterministic models, whereas sparsity induction has been mostly done through ad-hoc pruning. We propose sequential ensembling of dynamic Bayesian neural subnetworks that systematically reduce model complexity through sparsity-inducing priors and generate diverse ensembles in a single forward pass of the model. The ensembling strategy consists of an exploration phase that finds high-performing regions of the parameter space and multiple exploitation phases that effectively exploit the compactness of the sparse model to quickly converge to different minima in the energy landscape corresponding to high-performing subnetworks yielding diverse ensembles. We empirically demonstrate that our proposed approach surpasses the baselines of the dense frequentist and Bayesian ensemble models in prediction accuracy, uncertainty estimation, and out-of-distribution (OoD) robustness on CIFAR10, CIFAR100 datasets, and their out-of-distribution variants: CIFAR10-C, CIFAR100-C induced by corruptions. Furthermore, we found that our approach produced the most diverse ensembles compared to the approaches with a single forward pass and even compared to the approaches with multiple forward passes in some cases.