 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent Escapes Saddle Points Efficiently
Feb 13, 2019
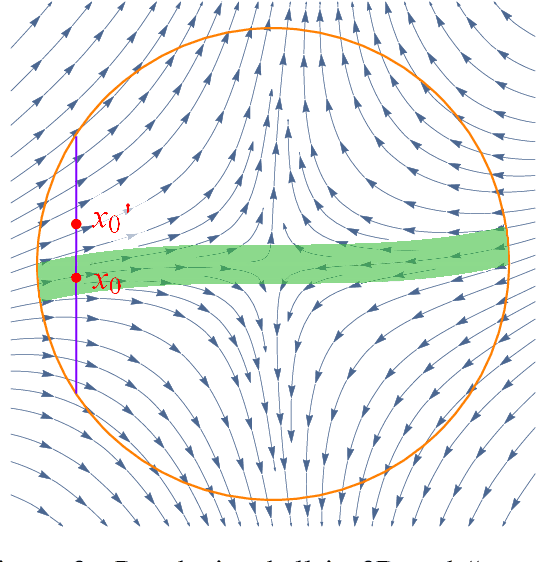
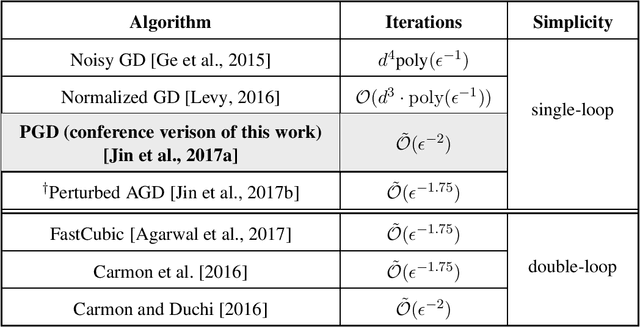
This paper considers the perturbed stochastic gradient descent algorithm and shows that it finds $\epsilon$-second order stationary points ($\left\|\nabla f(x)\right\|\leq \epsilon$ and $\nabla^2 f(x) \succeq -\sqrt{\epsilon} \mathbf{I}$) in $\tilde{O}(d/\epsilon^4)$ iterations, giving the first result that has linear dependence on dimension for this setting. For the special case, where stochastic gradients are Lipschitz, the dependence on dimension reduces to polylogarithmic. In addition to giving new results, this paper also presents a simplified proof strategy that gives a shorter and more elegant proof of previously known results (Jin et al. 2017) on perturbed gradient descent algorithm.
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
Feb 11, 2019In this note, we derive concentration inequalities for random vectors with subGaussian norm (a generalization of both subGaussian random vectors and norm bounded random vectors), which are tight up to logarithmic factors.
Minmax Optimization: Stable Limit Points of Gradient Descent Ascent are Locally Optimal
Feb 02, 2019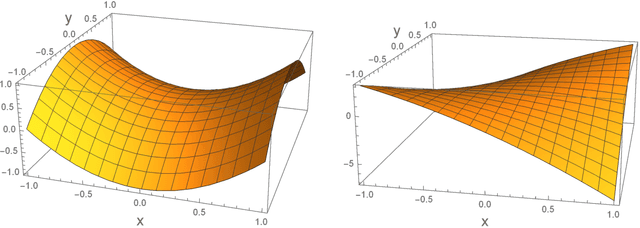
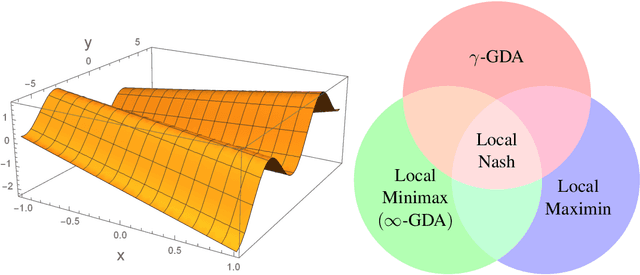
Minmax optimization, especially in its general nonconvex-nonconcave formulation, has found extensive applications in modern machine learning frameworks such as generative adversarial networks (GAN), adversarial training and multi-agent reinforcement learning. Gradient-based algorithms, in particular gradient descent ascent (GDA), are widely used in practice to solve these problems. Despite the practical popularity of GDA, however, its theoretical behavior has been considered highly undesirable. Indeed, apart from possiblity of non-convergence, recent results (Daskalakis and Panageas, 2018; Mazumdar and Ratliff, 2018; Adolphs et al., 2018) show that even when GDA converges, its stable limit points can be points that are not local Nash equilibria, thus not game-theoretically meaningful. In this paper, we initiate a discussion on the proper optimality measures for minmax optimization, and introduce a new notion of local optimality---local minmax---as a more suitable alternative to the notion of local Nash equilibrium. We establish favorable properties of local minmax points, and show, most importantly, that as the ratio of the ascent step size to the descent step size goes to infinity, stable limit points of GDA are exactly local minmax points up to degenerate points, demonstrating that all stable limit points of GDA have a game-theoretic meaning for minmax problems.
On the insufficiency of existing momentum schemes for Stochastic Optimization
Jul 31, 2018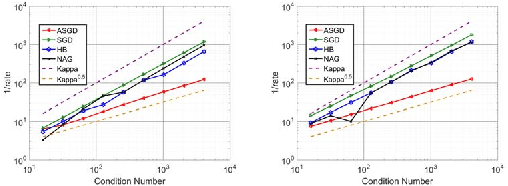
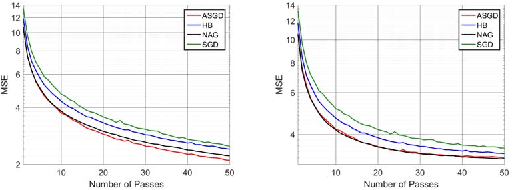
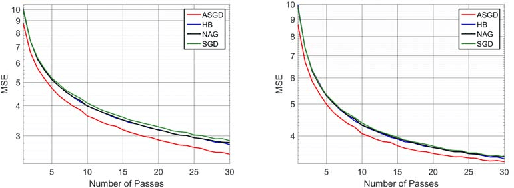
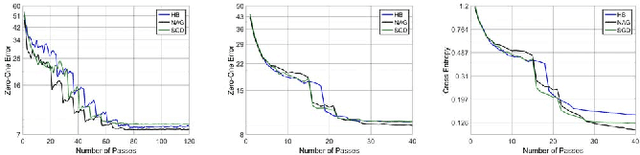
Momentum based stochastic gradient methods such as heavy ball (HB) and Nesterov's accelerated gradient descent (NAG) method are widely used in practice for training deep networks and other supervised learning models, as they often provide significant improvements over stochastic gradient descent (SGD). Rigorously speaking, "fast gradient" methods have provable improvements over gradient descent only for the deterministic case, where the gradients are exact. In the stochastic case, the popular explanations for their wide applicability is that when these fast gradient methods are applied in the stochastic case, they partially mimic their exact gradient counterparts, resulting in some practical gain. This work provides a counterpoint to this belief by proving that there exist simple problem instances where these methods cannot outperform SGD despite the best setting of its parameters. These negative problem instances are, in an informal sense, generic; they do not look like carefully constructed pathological instances. These results suggest (along with empirical evidence) that HB or NAG's practical performance gains are a by-product of mini-batching. Furthermore, this work provides a viable (and provable) alternative, which, on the same set of problem instances, significantly improves over HB, NAG, and SGD's performance. This algorithm, referred to as Accelerated Stochastic Gradient Descent (ASGD), is a simple to implement stochastic algorithm, based on a relatively less popular variant of Nesterov's Acceleration. Extensive empirical results in this paper show that ASGD has performance gains over HB, NAG, and SGD.
Accelerating Stochastic Gradient Descent For Least Squares Regression
Jul 31, 2018
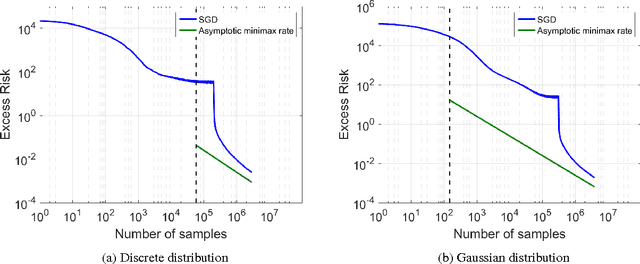
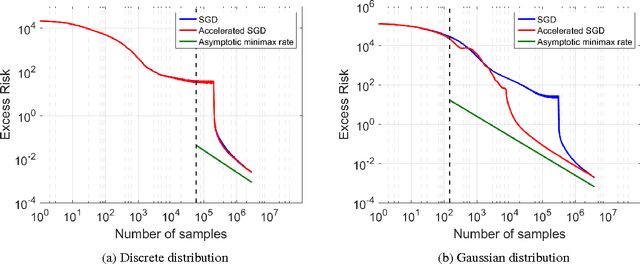
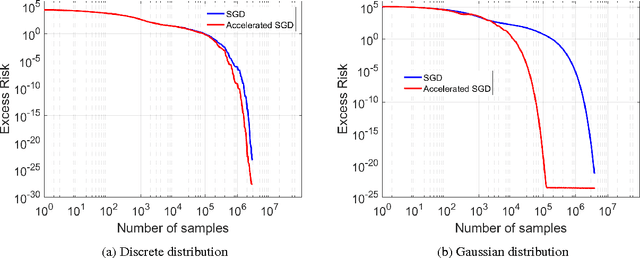
There is widespread sentiment that it is not possible to effectively utilize fast gradient methods (e.g. Nesterov's acceleration, conjugate gradient, heavy ball) for the purposes of stochastic optimization due to their instability and error accumulation, a notion made precise in d'Aspremont 2008 and Devolder, Glineur, and Nesterov 2014. This work considers these issues for the special case of stochastic approximation for the least squares regression problem, and our main result refutes the conventional wisdom by showing that acceleration can be made robust to statistical errors. In particular, this work introduces an accelerated stochastic gradient method that provably achieves the minimax optimal statistical risk faster than stochastic gradient descent. Critical to the analysis is a sharp characterization of accelerated stochastic gradient descent as a stochastic process. We hope this characterization gives insights towards the broader question of designing simple and effective accelerated stochastic methods for more general convex and non-convex optimization problems.
Parallelizing Stochastic Gradient Descent for Least Squares Regression: mini-batching, averaging, and model misspecification
Jul 31, 2018
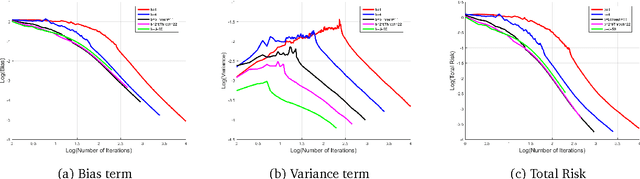

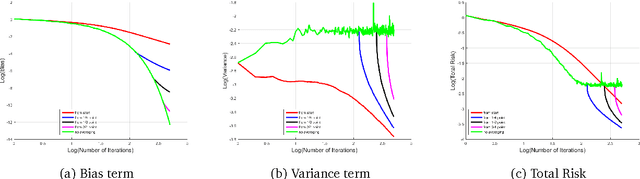
This work characterizes the benefits of averaging schemes widely used in conjunction with stochastic gradient descent (SGD). In particular, this work provides a sharp analysis of: (1) mini-batching, a method of averaging many samples of a stochastic gradient to both reduce the variance of the stochastic gradient estimate and for parallelizing SGD and (2) tail-averaging, a method involving averaging the final few iterates of SGD to decrease the variance in SGD's final iterate. This work presents non-asymptotic excess risk bounds for these schemes for the stochastic approximation problem of least squares regression. Furthermore, this work establishes a precise problem-dependent extent to which mini-batch SGD yields provable near-linear parallelization speedups over SGD with batch size one. This allows for understanding learning rate versus batch size tradeoffs for the final iterate of an SGD method. These results are then utilized in providing a highly parallelizable SGD method that obtains the minimax risk with nearly the same number of serial updates as batch gradient descent, improving significantly over existing SGD methods. A non-asymptotic analysis of communication efficient parallelization schemes such as model-averaging/parameter mixing methods is then provided. Finally, this work sheds light on some fundamental differences in SGD's behavior when dealing with agnostic noise in the (non-realizable) least squares regression problem. In particular, the work shows that the stepsizes that ensure minimax risk for the agnostic case must be a function of the noise properties. This paper builds on the operator view of analyzing SGD methods, introduced by Defossez and Bach (2015), followed by developing a novel analysis in bounding these operators to characterize the excess risk. These techniques are of broader interest in analyzing computational aspects of stochastic approximation.
A Markov Chain Theory Approach to Characterizing the Minimax Optimality of Stochastic Gradient Descent (for Least Squares)
Jul 21, 2018This work provides a simplified proof of the statistical minimax optimality of (iterate averaged) stochastic gradient descent (SGD), for the special case of least squares. This result is obtained by analyzing SGD as a stochastic process and by sharply characterizing the stationary covariance matrix of this process. The finite rate optimality characterization captures the constant factors and addresses model mis-specification.
Smoothed analysis for low-rank solutions to semidefinite programs in quadratic penalty form
Mar 01, 2018Semidefinite programs (SDP) are important in learning and combinatorial optimization with numerous applications. In pursuit of low-rank solutions and low complexity algorithms, we consider the Burer--Monteiro factorization approach for solving SDPs. We show that all approximate local optima are global optima for the penalty formulation of appropriately rank-constrained SDPs as long as the number of constraints scales sub-quadratically with the desired rank of the optimal solution. Our result is based on a simple penalty function formulation of the rank-constrained SDP along with a smoothed analysis to avoid worst-case cost matrices. We particularize our results to two applications, namely, Max-Cut and matrix completion.
Accelerated Gradient Descent Escapes Saddle Points Faster than Gradient Descent
Nov 28, 2017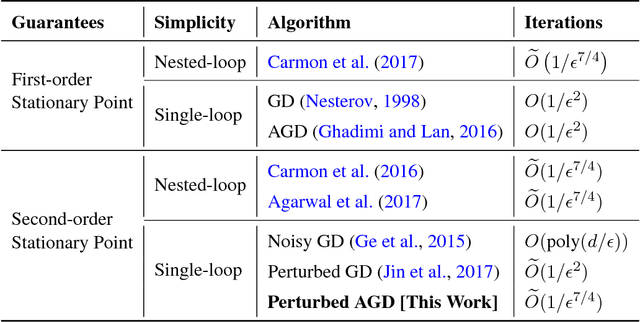
Nesterov's accelerated gradient descent (AGD), an instance of the general family of "momentum methods", provably achieves faster convergence rate than gradient descent (GD) in the convex setting. However, whether these methods are superior to GD in the nonconvex setting remains open. This paper studies a simple variant of AGD, and shows that it escapes saddle points and finds a second-order stationary point in $\tilde{O}(1/\epsilon^{7/4})$ iterations, faster than the $\tilde{O}(1/\epsilon^{2})$ iterations required by GD. To the best of our knowledge, this is the first Hessian-free algorithm to find a second-order stationary point faster than GD, and also the first single-loop algorithm with a faster rate than GD even in the setting of finding a first-order stationary point. Our analysis is based on two key ideas: (1) the use of a simple Hamiltonian function, inspired by a continuous-time perspective, which AGD monotonically decreases per step even for nonconvex functions, and (2) a novel framework called improve or localize, which is useful for tracking the long-term behavior of gradient-based optimization algorithms. We believe that these techniques may deepen our understanding of both acceleration algorithms and nonconvex optimization.
Leverage Score Sampling for Faster Accelerated Regression and ERM
Nov 22, 2017Given a matrix $\mathbf{A}\in\mathbb{R}^{n\times d}$ and a vector $b \in\mathbb{R}^{d}$, we show how to compute an $\epsilon$-approximate solution to the regression problem $ \min_{x\in\mathbb{R}^{d}}\frac{1}{2} \|\mathbf{A} x - b\|_{2}^{2} $ in time $ \tilde{O} ((n+\sqrt{d\cdot\kappa_{\text{sum}}})\cdot s\cdot\log\epsilon^{-1}) $ where $\kappa_{\text{sum}}=\mathrm{tr}\left(\mathbf{A}^{\top}\mathbf{A}\right)/\lambda_{\min}(\mathbf{A}^{T}\mathbf{A})$ and $s$ is the maximum number of non-zero entries in a row of $\mathbf{A}$. Our algorithm improves upon the previous best running time of $ \tilde{O} ((n+\sqrt{n \cdot\kappa_{\text{sum}}})\cdot s\cdot\log\epsilon^{-1})$. We achieve our result through a careful combination of leverage score sampling techniques, proximal point methods, and accelerated coordinate descent. Our method not only matches the performance of previous methods, but further improves whenever leverage scores of rows are small (up to polylogarithmic factors). We also provide a non-linear generalization of these results that improves the running time for solving a broader class of ERM problems.