 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Fairness Guarantee in Learning with Censorship
Feb 16, 2023Algorithmic fairness, studying how to make machine learning (ML) algorithms fair, is an established area of ML. As ML technologies expand their application domains, including ones with high societal impact, it becomes essential to take fairness into consideration when building ML systems. Yet, despite its wide range of socially sensitive applications, most work treats the issue of algorithmic bias as an intrinsic property of supervised learning, i.e., the class label is given as a precondition. Unlike prior fairness work, we study individual fairness in learning with censorship where the assumption of availability of the class label does not hold, while still requiring that similar individuals are treated similarly. We argue that this perspective represents a more realistic model of fairness research for real-world application deployment, and show how learning with such a relaxed precondition draws new insights that better explain algorithmic fairness. We also thoroughly evaluate the performance of the proposed methodology on three real-world datasets, and validate its superior performance in minimizing discrimination while maintaining predictive performance.
Nash Equilibria and Pitfalls of Adversarial Training in Adversarial Robustness Games
Oct 25, 2022Adversarial training is a standard technique for training adversarially robust models. In this paper, we study adversarial training as an alternating best-response strategy in a 2-player zero-sum game. We prove that even in a simple scenario of a linear classifier and a statistical model that abstracts robust vs. non-robust features, the alternating best response strategy of such game may not converge. On the other hand, a unique pure Nash equilibrium of the game exists and is provably robust. We support our theoretical results with experiments, showing the non-convergence of adversarial training and the robustness of Nash equilibrium.
Label Propagation with Weak Supervision
Oct 07, 2022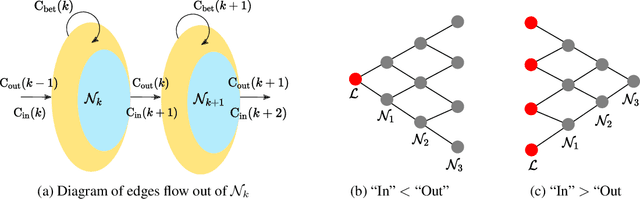
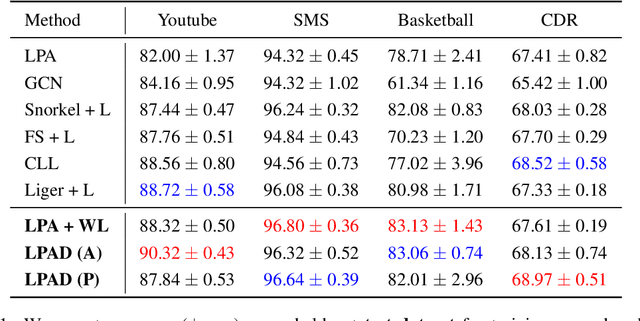

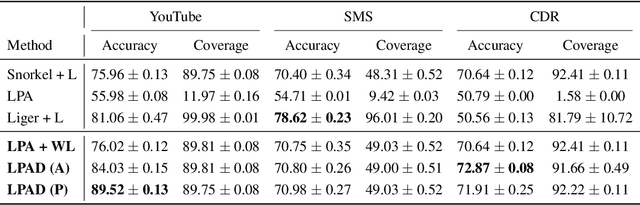
Semi-supervised learning and weakly supervised learning are important paradigms that aim to reduce the growing demand for labeled data in current machine learning applications. In this paper, we introduce a novel analysis of the classical label propagation algorithm (LPA) (Zhu & Ghahramani, 2002) that moreover takes advantage of useful prior information, specifically probabilistic hypothesized labels on the unlabeled data. We provide an error bound that exploits both the local geometric properties of the underlying graph and the quality of the prior information. We also propose a framework to incorporate multiple sources of noisy information. In particular, we consider the setting of weak supervision, where our sources of information are weak labelers. We demonstrate the ability of our approach on multiple benchmark weakly supervised classification tasks, showing improvements upon existing semi-supervised and weakly supervised methods.
DAGMA: Learning DAGs via M-matrices and a Log-Determinant Acyclicity Characterization
Sep 16, 2022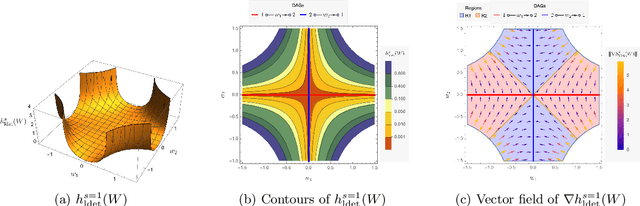
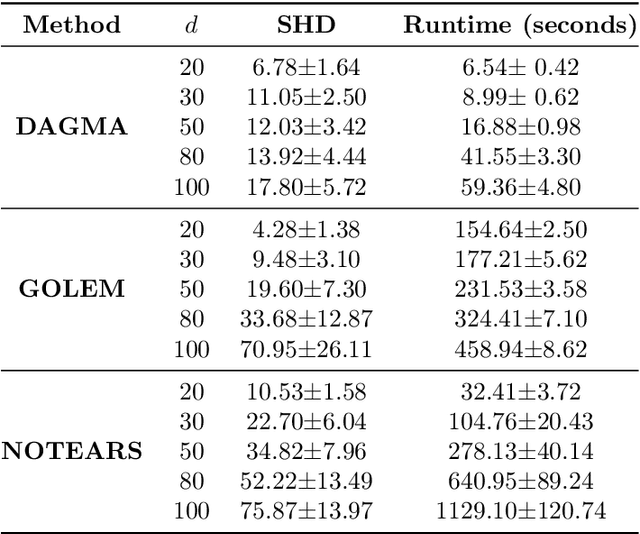
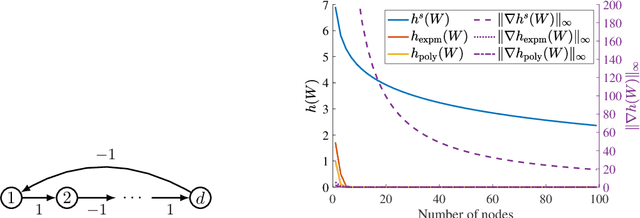
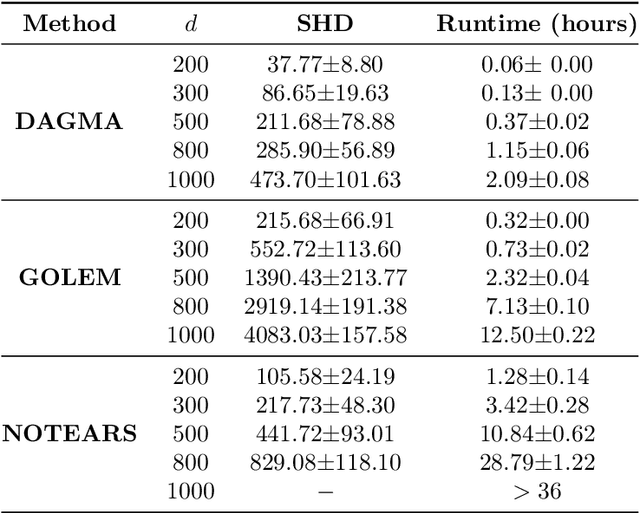
The combinatorial problem of learning directed acyclic graphs (DAGs) from data was recently framed as a purely continuous optimization problem by leveraging a differentiable acyclicity characterization of DAGs based on the trace of a matrix exponential function. Existing acyclicity characterizations are based on the idea that powers of an adjacency matrix contain information about walks and cycles. In this work, we propose a $\textit{fundamentally different}$ acyclicity characterization based on the log-determinant (log-det) function, which leverages the nilpotency property of DAGs. To deal with the inherent asymmetries of a DAG, we relate the domain of our log-det characterization to the set of $\textit{M-matrices}$, which is a key difference to the classical log-det function defined over the cone of positive definite matrices. Similar to acyclicity functions previously proposed, our characterization is also exact and differentiable. However, when compared to existing characterizations, our log-det function: (1) Is better at detecting large cycles; (2) Has better-behaved gradients; and (3) Its runtime is in practice about an order of magnitude faster. From the optimization side, we drop the typically used augmented Lagrangian scheme, and propose DAGMA ($\textit{Directed Acyclic Graphs via M-matrices for Acyclicity}$), a method that resembles the central path for barrier methods. Each point in the central path of DAGMA is a solution to an unconstrained problem regularized by our log-det function, then we show that at the limit of the central path the solution is guaranteed to be a DAG. Finally, we provide extensive experiments for $\textit{linear}$ and $\textit{nonlinear}$ SEMs, and show that our approach can reach large speed-ups and smaller structural Hamming distances against state-of-the-art methods.
Concept Gradient: Concept-based Interpretation Without Linear Assumption
Aug 31, 2022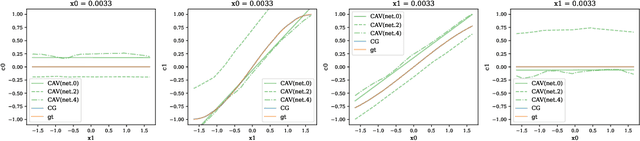
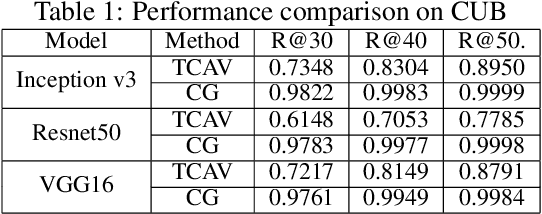
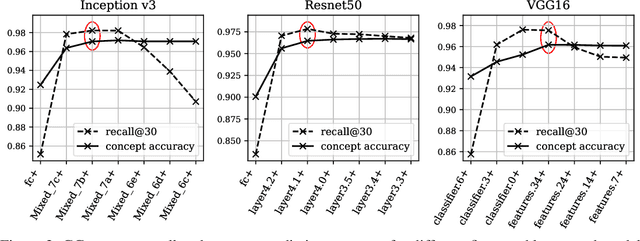
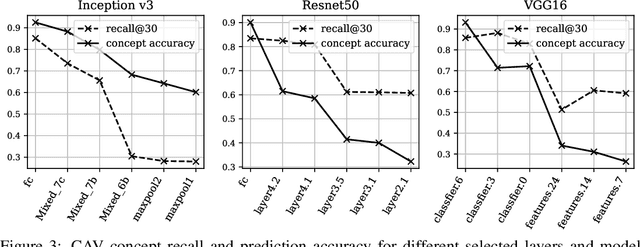
Concept-based interpretations of black-box models are often more intuitive for humans to understand. The most widely adopted approach for concept-based interpretation is Concept Activation Vector (CAV). CAV relies on learning a linear relation between some latent representation of a given model and concepts. The linear separability is usually implicitly assumed but does not hold true in general. In this work, we started from the original intent of concept-based interpretation and proposed Concept Gradient (CG), extending concept-based interpretation beyond linear concept functions. We showed that for a general (potentially non-linear) concept, we can mathematically evaluate how a small change of concept affecting the model's prediction, which leads to an extension of gradient-based interpretation to the concept space. We demonstrated empirically that CG outperforms CAV in both toy examples and real world datasets.
Identifiability of deep generative models under mixture priors without auxiliary information
Jun 20, 2022


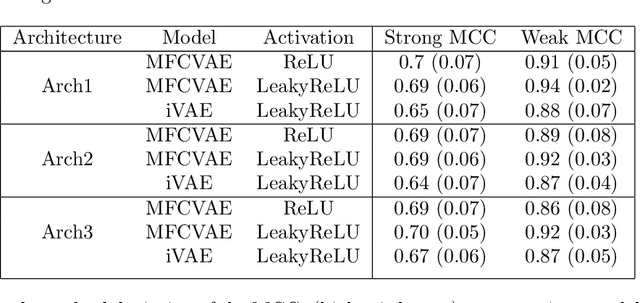
We prove identifiability of a broad class of deep latent variable models that (a) have universal approximation capabilities and (b) are the decoders of variational autoencoders that are commonly used in practice. Unlike existing work, our analysis does not require weak supervision, auxiliary information, or conditioning in the latent space. Recently, there has been a surge of works studying identifiability of such models. In these works, the main assumption is that along with the data, an auxiliary variable $u$ (also known as side information) is observed as well. At the same time, several works have empirically observed that this doesn't seem to be necessary in practice. In this work, we explain this behavior by showing that for a broad class of generative (i.e. unsupervised) models with universal approximation capabilities, the side information $u$ is not necessary: We prove identifiability of the entire generative model where we do not observe $u$ and only observe the data $x$. The models we consider are tightly connected with autoencoder architectures used in practice that leverage mixture priors in the latent space and ReLU/leaky-ReLU activations in the encoder. Our main result is an identifiability hierarchy that significantly generalizes previous work and exposes how different assumptions lead to different "strengths" of identifiability. For example, our weakest result establishes (unsupervised) identifiability up to an affine transformation, which already improves existing work. It's well known that these models have universal approximation capabilities and moreover, they have been extensively used in practice to learn representations of data.
Building Robust Ensembles via Margin Boosting
Jun 07, 2022
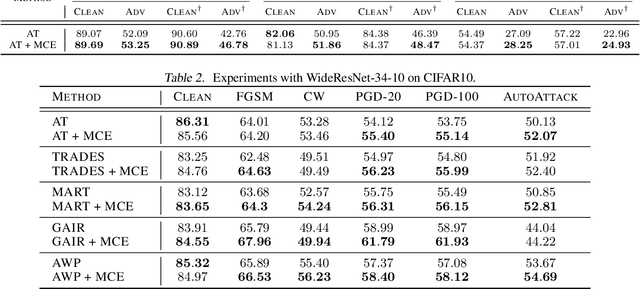

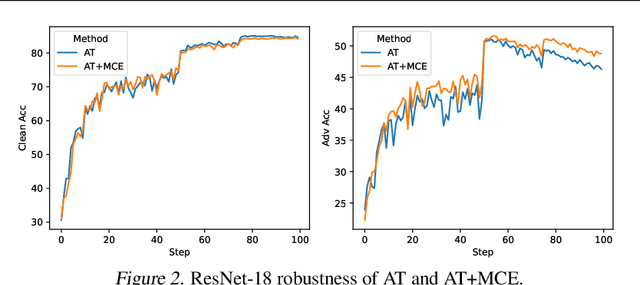
In the context of adversarial robustness, a single model does not usually have enough power to defend against all possible adversarial attacks, and as a result, has sub-optimal robustness. Consequently, an emerging line of work has focused on learning an ensemble of neural networks to defend against adversarial attacks. In this work, we take a principled approach towards building robust ensembles. We view this problem from the perspective of margin-boosting and develop an algorithm for learning an ensemble with maximum margin. Through extensive empirical evaluation on benchmark datasets, we show that our algorithm not only outperforms existing ensembling techniques, but also large models trained in an end-to-end fashion. An important byproduct of our work is a margin-maximizing cross-entropy (MCE) loss, which is a better alternative to the standard cross-entropy (CE) loss. Empirically, we show that replacing the CE loss in state-of-the-art adversarial training techniques with our MCE loss leads to significant performance improvement.
Faith-Shap: The Faithful Shapley Interaction Index
Mar 09, 2022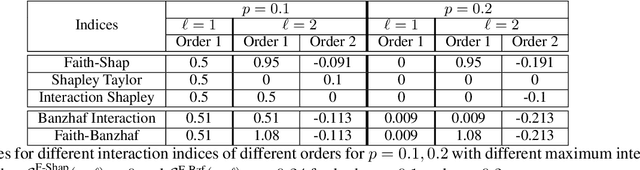
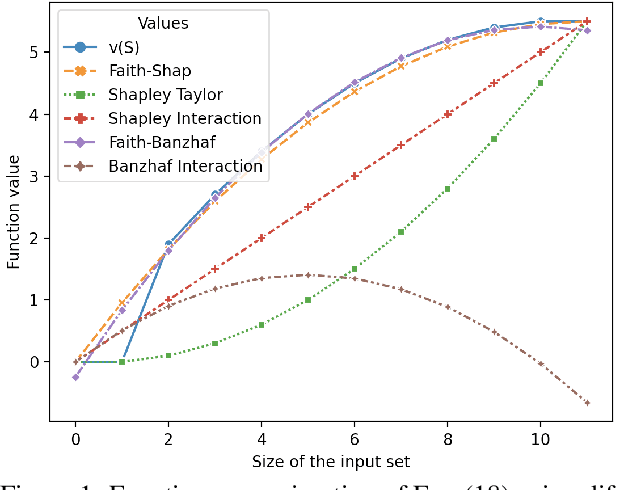
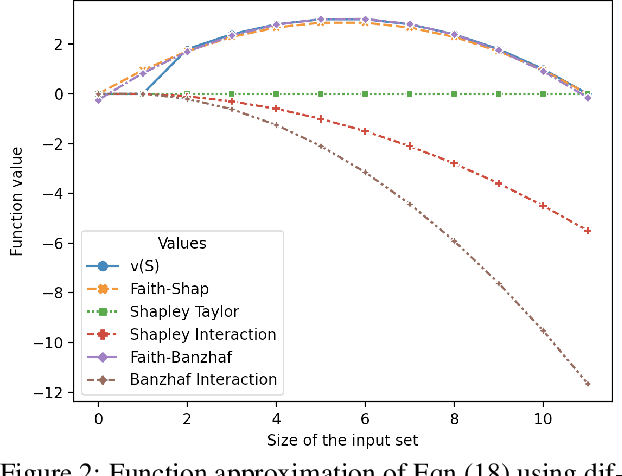
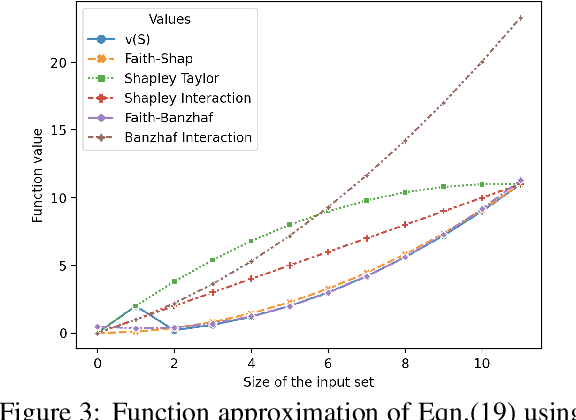
Shapley values, which were originally designed to assign attributions to individual players in coalition games, have become a commonly used approach in explainable machine learning to provide attributions to input features for black-box machine learning models. A key attraction of Shapley values is that they uniquely satisfy a very natural set of axiomatic properties. However, extending the Shapley value to assigning attributions to interactions rather than individual players, an interaction index, is non-trivial: as the natural set of axioms for the original Shapley values, extended to the context of interactions, no longer specify a unique interaction index. Many proposals thus introduce additional less "natural" axioms, while sacrificing the key axiom of efficiency, in order to obtain unique interaction indices. In this work, rather than introduce additional conflicting axioms, we adopt the viewpoint of Shapley values as coefficients of the most faithful linear approximation to the pseudo-Boolean coalition game value function. By extending linear to $\ell$-order polynomial approximations, we can then define the general family of faithful interaction indices}. We show that by additionally requiring the faithful interaction indices to satisfy interaction-extensions of the standard individual Shapley axioms (dummy, symmetry, linearity, and efficiency), we obtain a unique FaithfulShapley Interaction index, which we denote Faith-Shap, as a natural generalization of the Shapley value to interactions. We then provide some illustrative contrasts of Faith-Shap with previously proposed interaction indices, and further investigate some of its interesting algebraic properties. We further show the computational efficiency of computing Faith-Shap, together with some additional qualitative insights, via some illustrative experiments.
Human-Centered Concept Explanations for Neural Networks
Feb 25, 2022
Understanding complex machine learning models such as deep neural networks with explanations is crucial in various applications. Many explanations stem from the model perspective, and may not necessarily effectively communicate why the model is making its predictions at the right level of abstraction. For example, providing importance weights to individual pixels in an image can only express which parts of that particular image are important to the model, but humans may prefer an explanation which explains the prediction by concept-based thinking. In this work, we review the emerging area of concept based explanations. We start by introducing concept explanations including the class of Concept Activation Vectors (CAV) which characterize concepts using vectors in appropriate spaces of neural activations, and discuss different properties of useful concepts, and approaches to measure the usefulness of concept vectors. We then discuss approaches to automatically extract concepts, and approaches to address some of their caveats. Finally, we discuss some case studies that showcase the utility of such concept-based explanations in synthetic settings and real world applications.
Threading the Needle of On and Off-Manifold Value Functions for Shapley Explanations
Feb 24, 2022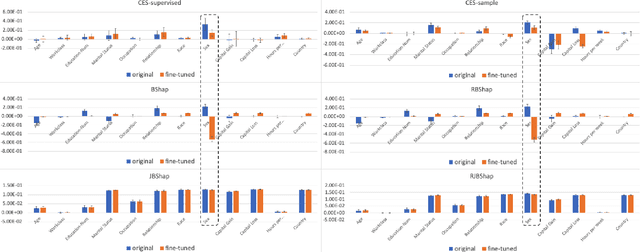

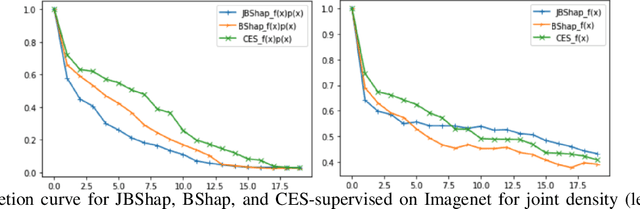
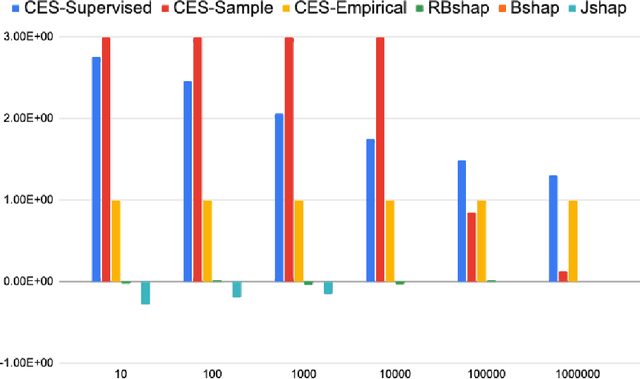
A popular explainable AI (XAI) approach to quantify feature importance of a given model is via Shapley values. These Shapley values arose in cooperative games, and hence a critical ingredient to compute these in an XAI context is a so-called value function, that computes the "value" of a subset of features, and which connects machine learning models to cooperative games. There are many possible choices for such value functions, which broadly fall into two categories: on-manifold and off-manifold value functions, which take an observational and an interventional viewpoint respectively. Both these classes however have their respective flaws, where on-manifold value functions violate key axiomatic properties and are computationally expensive, while off-manifold value functions pay less heed to the data manifold and evaluate the model on regions for which it wasn't trained. Thus, there is no consensus on which class of value functions to use. In this paper, we show that in addition to these existing issues, both classes of value functions are prone to adversarial manipulations on low density regions. We formalize the desiderata of value functions that respect both the model and the data manifold in a set of axioms and are robust to perturbation on off-manifold regions, and show that there exists a unique value function that satisfies these axioms, which we term the Joint Baseline value function, and the resulting Shapley value the Joint Baseline Shapley (JBshap), and validate the effectiveness of JBshap in experiments.