 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOAT: Bilateral Local Attention Vision Transformer
Jan 31, 2022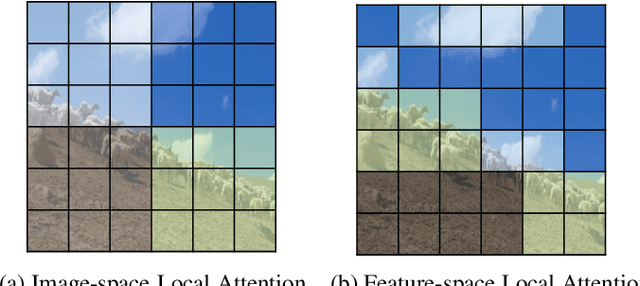
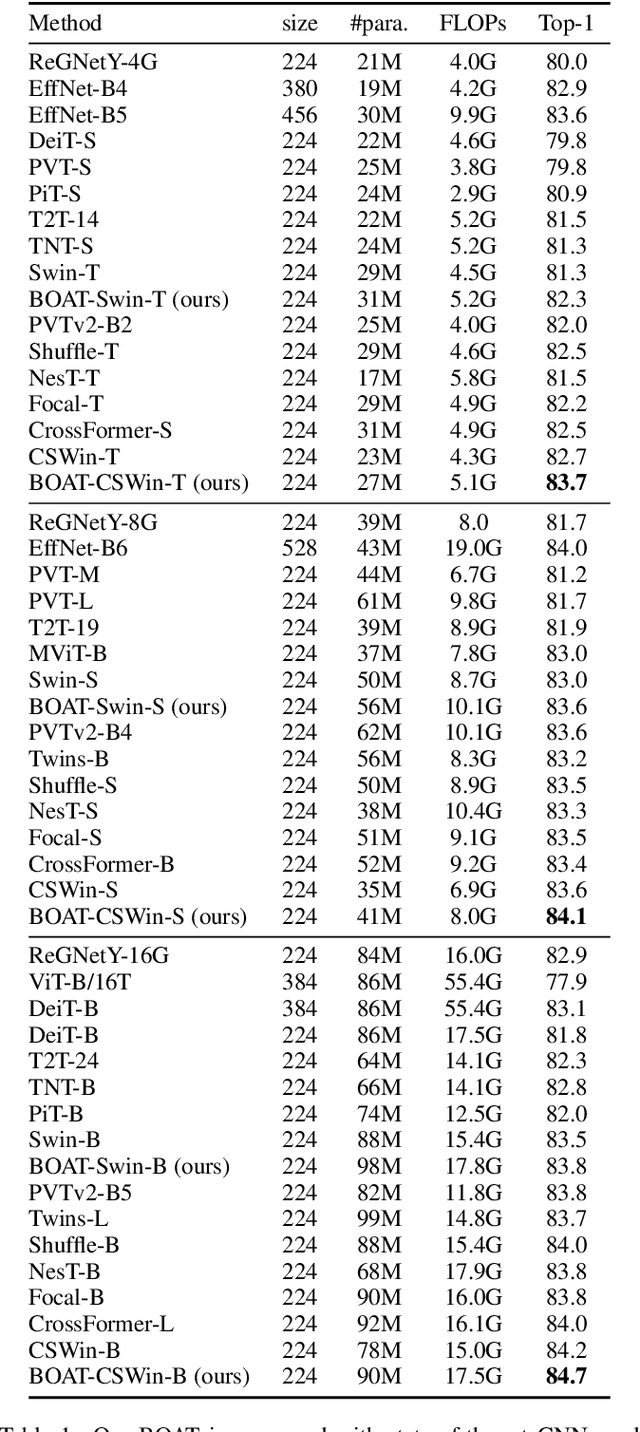

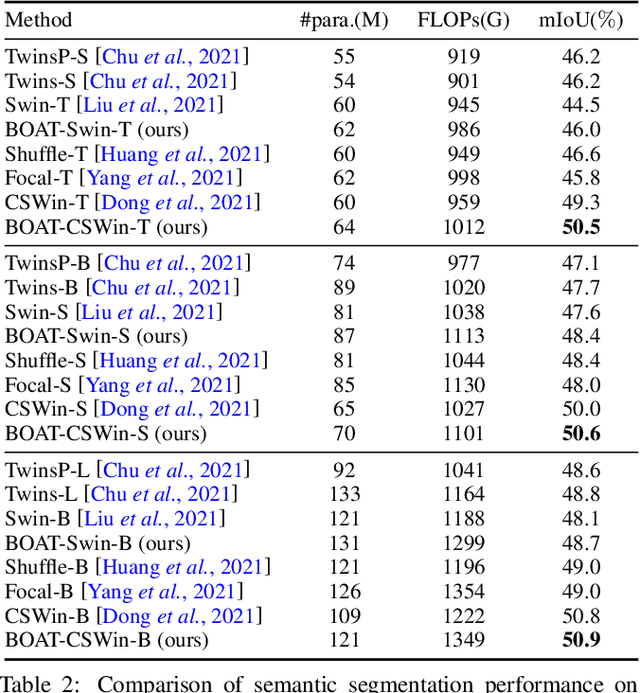
Vision Transformers achieved outstanding performance in many computer vision tasks. Early Vision Transformers such as ViT and DeiT adopt global self-attention, which is computationally expensive when the number of patches is large. To improve efficiency, recent Vision Transformers adopt local self-attention mechanisms, where self-attention is computed within local windows. Despite the fact that window-based local self-attention significantly boosts efficiency, it fails to capture the relationships between distant but similar patches in the image plane. To overcome this limitation of image-space local attention, in this paper, we further exploit the locality of patches in the feature space. We group the patches into multiple clusters using their features, and self-attention is computed within every cluster. Such feature-space local attention effectively captures the connections between patches across different local windows but still relevant. We propose a Bilateral lOcal Attention vision Transformer (BOAT), which integrates feature-space local attention with image-space local attention. We further integrate BOAT with both Swin and CSWin models, and extensive experiments on several benchmark datasets demonstrate that our BOAT-CSWin model clearly and consistently outperforms existing state-of-the-art CNN models and vision Transformers.
On the Power-Law Spectrum in Deep Learning: A Bridge to Protein Science
Jan 31, 2022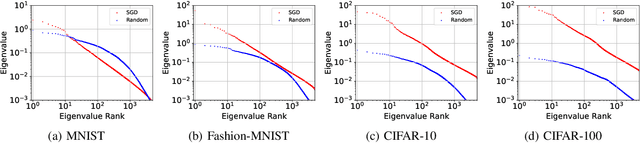
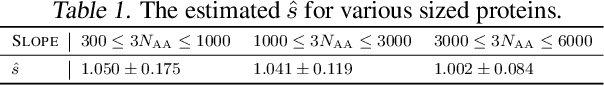
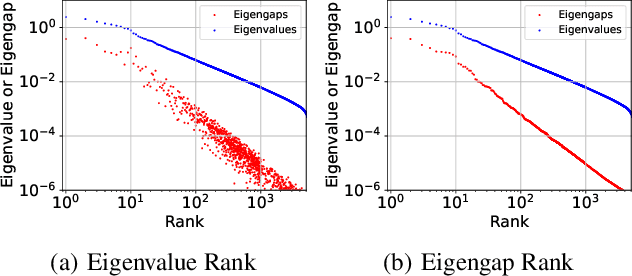

It is well-known that the Hessian matters to optimization, generalization, and even robustness of deep learning. Recent works empirically discovered that the Hessian spectrum in deep learning has a two-component structure that consists of a small number of large eigenvalues and a large number of nearly-zero eigenvalues. However, the theoretical mechanism behind the Hessian spectrum is still absent or under-explored. We are the first to theoretically and empirically demonstrate that the Hessian spectrums of well-trained deep neural networks exhibit simple power-law distributions. Our work further reveals how the power-law spectrum essentially matters to deep learning: (1) it leads to low-dimensional and robust learning space, and (2) it implicitly penalizes the variational free energy, which results in low-complexity solutions. We further used the power-law spectral framework as a powerful tool to demonstrate multiple novel behaviors of deep learning. Interestingly, the power-law spectrum is also known to be important in protein, which indicates a novel bridge between deep learning and protein science.
GCWSNet: Generalized Consistent Weighted Sampling for Scalable and Accurate Training of Neural Networks
Jan 07, 2022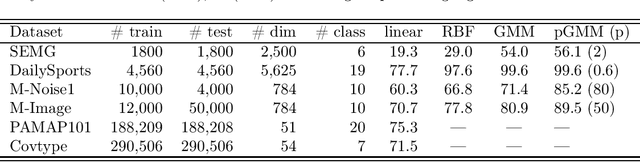
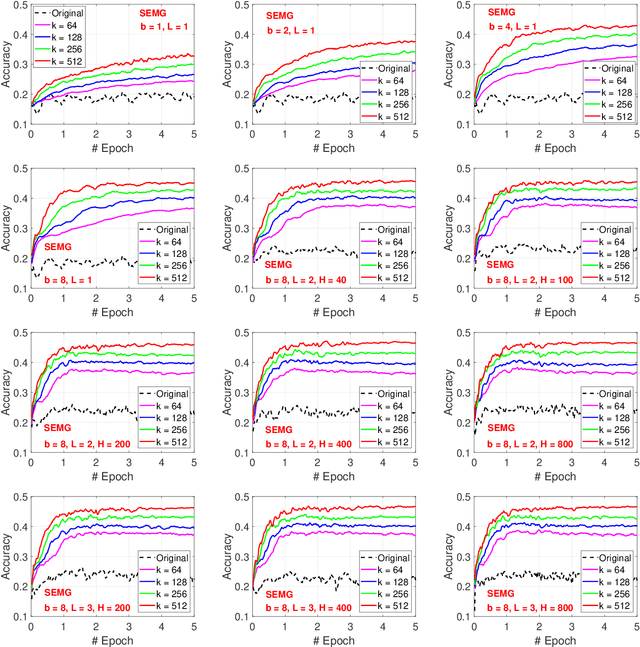
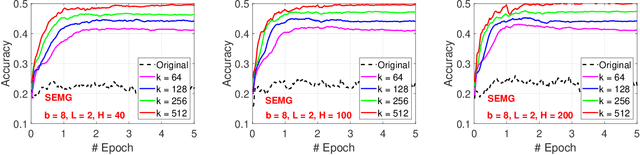
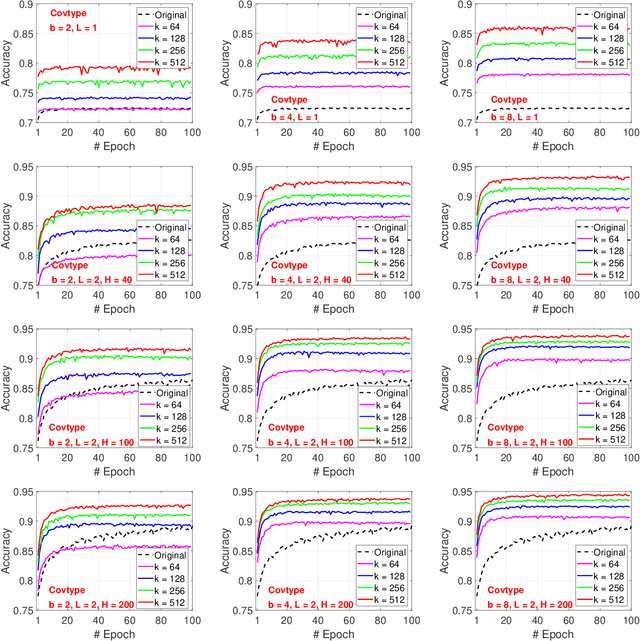
We develop the "generalized consistent weighted sampling" (GCWS) for hashing the "powered-GMM" (pGMM) kernel (with a tuning parameter $p$). It turns out that GCWS provides a numerically stable scheme for applying power transformation on the original data, regardless of the magnitude of $p$ and the data. The power transformation is often effective for boosting the performance, in many cases considerably so. We feed the hashed data to neural networks on a variety of public classification datasets and name our method ``GCWSNet''. Our extensive experiments show that GCWSNet often improves the classification accuracy. Furthermore, it is evident from the experiments that GCWSNet converges substantially faster. In fact, GCWS often reaches a reasonable accuracy with merely (less than) one epoch of the training process. This property is much desired because many applications, such as advertisement click-through rate (CTR) prediction models, or data streams (i.e., data seen only once), often train just one epoch. Another beneficial side effect is that the computations of the first layer of the neural networks become additions instead of multiplications because the input data become binary (and highly sparse). Empirical comparisons with (normalized) random Fourier features (NRFF) are provided. We also propose to reduce the model size of GCWSNet by count-sketch and develop the theory for analyzing the impact of using count-sketch on the accuracy of GCWS. Our analysis shows that an ``8-bit'' strategy should work well in that we can always apply an 8-bit count-sketch hashing on the output of GCWS hashing without hurting the accuracy much. There are many other ways to take advantage of GCWS when training deep neural networks. For example, one can apply GCWS on the outputs of the last layer to boost the accuracy of trained deep neural networks.
Communication-Efficient TeraByte-Scale Model Training Framework for Online Advertising
Jan 05, 2022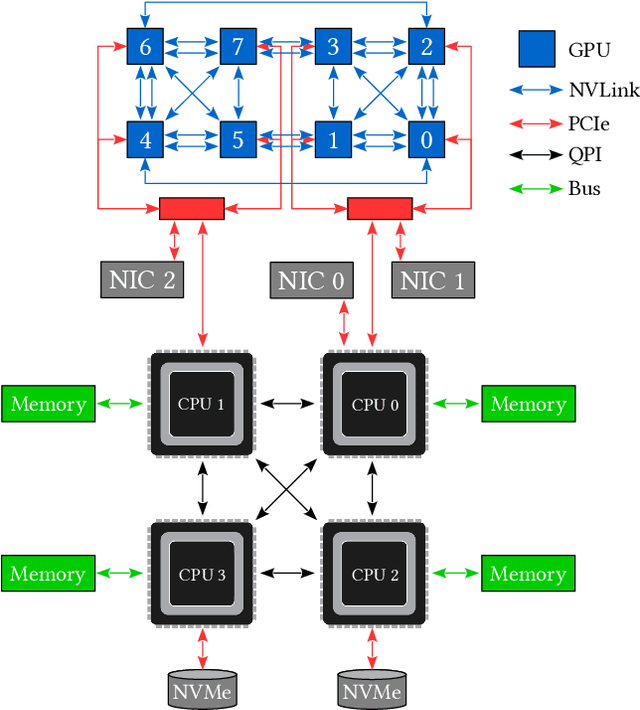
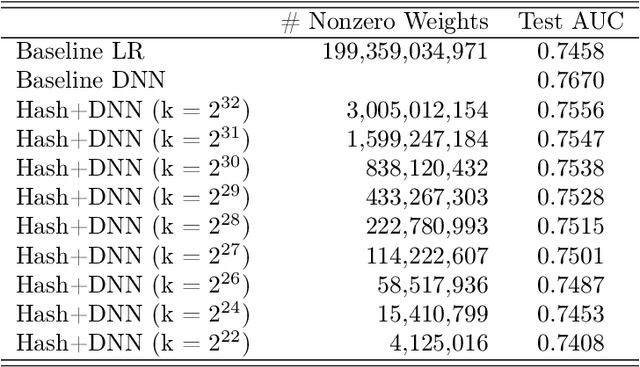
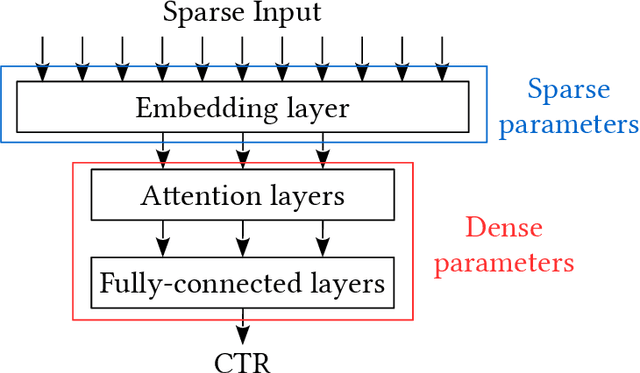
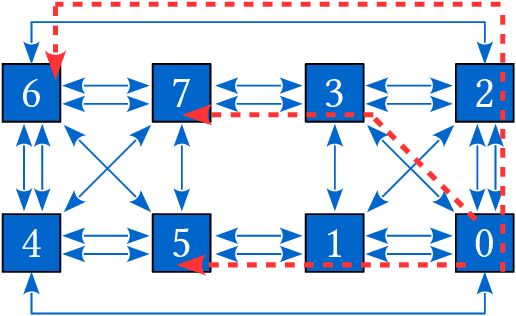
Click-Through Rate (CTR) prediction is a crucial component in the online advertising industry. In order to produce a personalized CTR prediction, an industry-level CTR prediction model commonly takes a high-dimensional (e.g., 100 or 1000 billions of features) sparse vector (that is encoded from query keywords, user portraits, etc.) as input. As a result, the model requires Terabyte scale parameters to embed the high-dimensional input. Hierarchical distributed GPU parameter server has been proposed to enable GPU with limited memory to train the massive network by leveraging CPU main memory and SSDs as secondary storage. We identify two major challenges in the existing GPU training framework for massive-scale ad models and propose a collection of optimizations to tackle these challenges: (a) the GPU, CPU, SSD rapidly communicate with each other during the training. The connections between GPUs and CPUs are non-uniform due to the hardware topology. The data communication route should be optimized according to the hardware topology; (b) GPUs in different computing nodes frequently communicates to synchronize parameters. We are required to optimize the communications so that the distributed system can become scalable. In this paper, we propose a hardware-aware training workflow that couples the hardware topology into the algorithm design. To reduce the extensive communication between computing nodes, we introduce a $k$-step model merging algorithm for the popular Adam optimizer and provide its convergence rate in non-convex optimization. To the best of our knowledge, this is the first application of $k$-step adaptive optimization method in industrial-level CTR model training. The numerical results on real-world data confirm that the optimized system design considerably reduces the training time of the massive model, with essentially no loss in accuracy.
Boosting RGB-D Saliency Detection by Leveraging Unlabeled RGB Images
Jan 01, 2022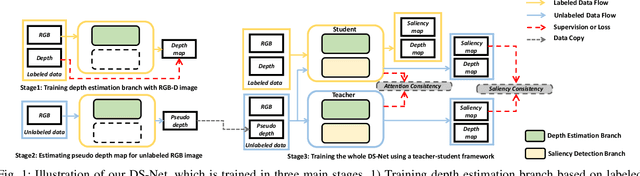
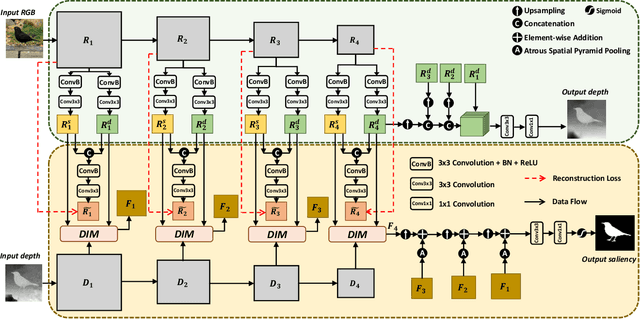
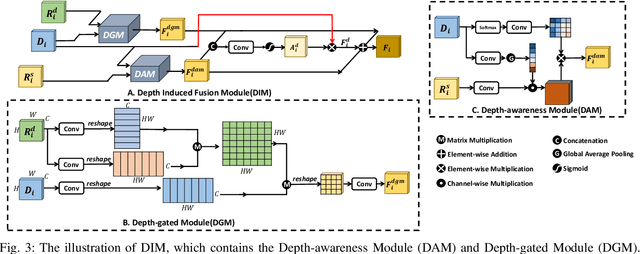

Training deep models for RGB-D salient object detection (SOD) often requires a large number of labeled RGB-D images. However, RGB-D data is not easily acquired, which limits the development of RGB-D SOD techniques. To alleviate this issue, we present a Dual-Semi RGB-D Salient Object Detection Network (DS-Net) to leverage unlabeled RGB images for boosting RGB-D saliency detection. We first devise a depth decoupling convolutional neural network (DDCNN), which contains a depth estimation branch and a saliency detection branch. The depth estimation branch is trained with RGB-D images and then used to estimate the pseudo depth maps for all unlabeled RGB images to form the paired data. The saliency detection branch is used to fuse the RGB feature and depth feature to predict the RGB-D saliency. Then, the whole DDCNN is assigned as the backbone in a teacher-student framework for semi-supervised learning. Moreover, we also introduce a consistency loss on the intermediate attention and saliency maps for the unlabeled data, as well as a supervised depth and saliency loss for labeled data. Experimental results on seven widely-used benchmark datasets demonstrate that our DDCNN outperforms state-of-the-art methods both quantitatively and qualitatively. We also demonstrate that our semi-supervised DS-Net can further improve the performance, even when using an RGB image with the pseudo depth map.
Learning Generative Vision Transformer with Energy-Based Latent Space for Saliency Prediction
Dec 27, 2021
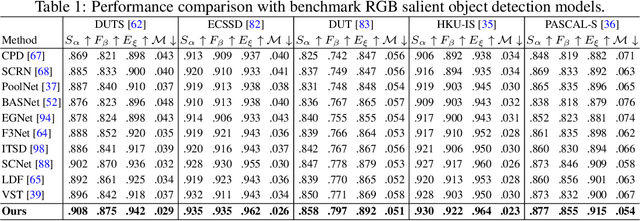
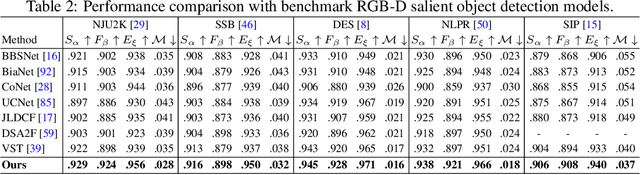

Vision transformer networks have shown superiority in many computer vision tasks. In this paper, we take a step further by proposing a novel generative vision transformer with latent variables following an informative energy-based prior for salient object detection. Both the vision transformer network and the energy-based prior model are jointly trained via Markov chain Monte Carlo-based maximum likelihood estimation, in which the sampling from the intractable posterior and prior distributions of the latent variables are performed by Langevin dynamics. Further, with the generative vision transformer, we can easily obtain a pixel-wise uncertainty map from an image, which indicates the model confidence in predicting saliency from the image. Different from the existing generative models which define the prior distribution of the latent variables as a simple isotropic Gaussian distribution, our model uses an energy-based informative prior which can be more expressive to capture the latent space of the data. We apply the proposed framework to both RGB and RGB-D salient object detection tasks. Extensive experimental results show that our framework can achieve not only accurate saliency predictions but also meaningful uncertainty maps that are consistent with the human perception.
Input-Specific Robustness Certification for Randomized Smoothing
Dec 21, 2021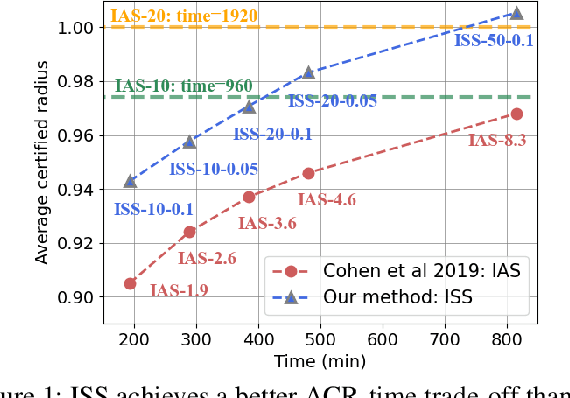
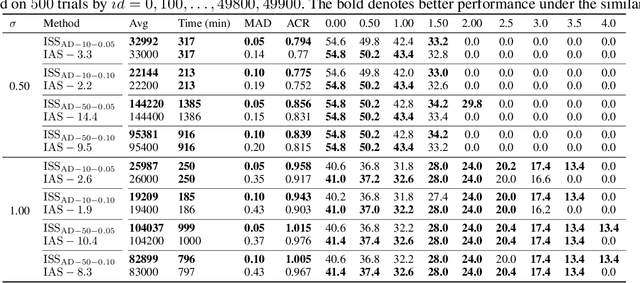
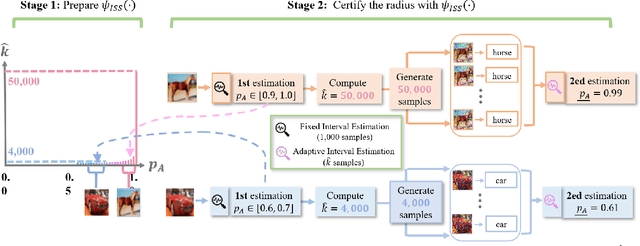
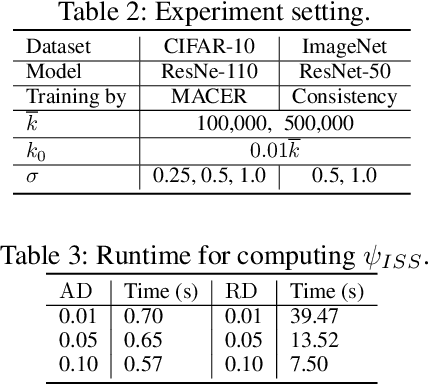
Although randomized smoothing has demonstrated high certified robustness and superior scalability to other certified defenses, the high computational overhead of the robustness certification bottlenecks the practical applicability, as it depends heavily on the large sample approximation for estimating the confidence interval. In existing works, the sample size for the confidence interval is universally set and agnostic to the input for prediction. This Input-Agnostic Sampling (IAS) scheme may yield a poor Average Certified Radius (ACR)-runtime trade-off which calls for improvement. In this paper, we propose Input-Specific Sampling (ISS) acceleration to achieve the cost-effectiveness for robustness certification, in an adaptive way of reducing the sampling size based on the input characteristic. Furthermore, our method universally controls the certified radius decline from the ISS sample size reduction. The empirical results on CIFAR-10 and ImageNet show that ISS can speed up the certification by more than three times at a limited cost of 0.05 certified radius. Meanwhile, ISS surpasses IAS on the average certified radius across the extensive hyperparameter settings. Specifically, ISS achieves ACR=0.958 on ImageNet ($\sigma=1.0$) in 250 minutes, compared to ACR=0.917 by IAS under the same condition. We release our code in \url{https://github.com/roy-ch/Input-Specific-Certification}.
C-OPH: Improving the Accuracy of One Permutation Hashing with Circulant Permutations
Nov 18, 2021
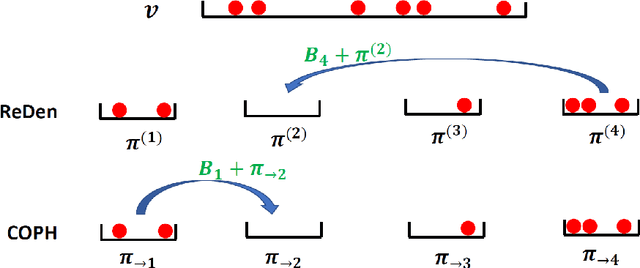
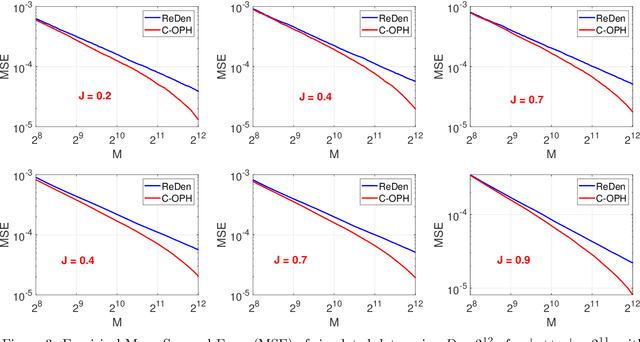
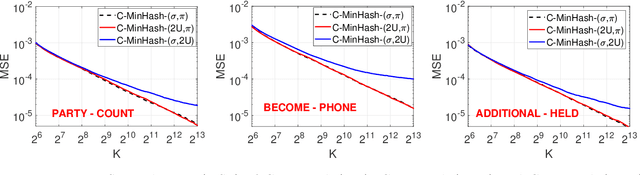
Minwise hashing (MinHash) is a classical method for efficiently estimating the Jaccrad similarity in massive binary (0/1) data. To generate $K$ hash values for each data vector, the standard theory of MinHash requires $K$ independent permutations. Interestingly, the recent work on "circulant MinHash" (C-MinHash) has shown that merely two permutations are needed. The first permutation breaks the structure of the data and the second permutation is re-used $K$ time in a circulant manner. Surprisingly, the estimation accuracy of C-MinHash is proved to be strictly smaller than that of the original MinHash. The more recent work further demonstrates that practically only one permutation is needed. Note that C-MinHash is different from the well-known work on "One Permutation Hashing (OPH)" published in NIPS'12. OPH and its variants using different "densification" schemes are popular alternatives to the standard MinHash. The densification step is necessary in order to deal with empty bins which exist in One Permutation Hashing. In this paper, we propose to incorporate the essential ideas of C-MinHash to improve the accuracy of One Permutation Hashing. Basically, we develop a new densification method for OPH, which achieves the smallest estimation variance compared to all existing densification schemes for OPH. Our proposed method is named C-OPH (Circulant OPH). After the initial permutation (which breaks the existing structure of the data), C-OPH only needs a "shorter" permutation of length $D/K$ (instead of $D$), where $D$ is the original data dimension and $K$ is the total number of bins in OPH. This short permutation is re-used in $K$ bins in a circulant shifting manner. It can be shown that the estimation variance of the Jaccard similarity is strictly smaller than that of the existing (densified) OPH methods.
MVT: Multi-view Vision Transformer for 3D Object Recognition
Oct 25, 2021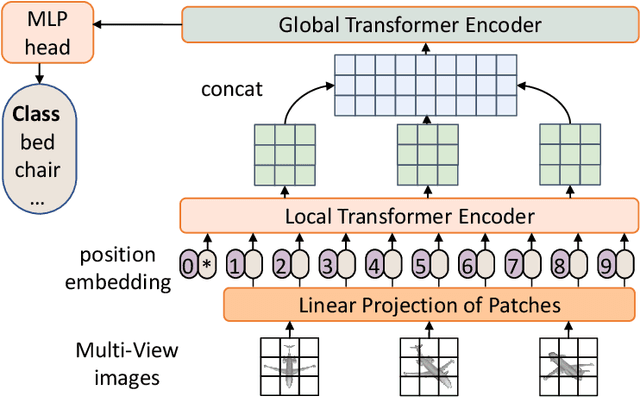
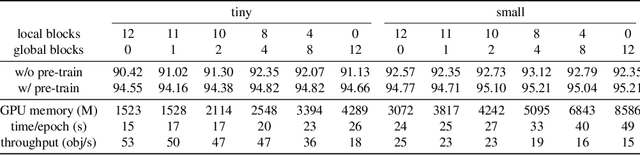

Inspired by the great success achieved by CNN in image recognition, view-based methods applied CNNs to model the projected views for 3D object understanding and achieved excellent performance. Nevertheless, multi-view CNN models cannot model the communications between patches from different views, limiting its effectiveness in 3D object recognition. Inspired by the recent success gained by vision Transformer in image recognition, we propose a Multi-view Vision Transformer (MVT) for 3D object recognition. Since each patch feature in a Transformer block has a global reception field, it naturally achieves communications between patches from different views. Meanwhile, it takes much less inductive bias compared with its CNN counterparts. Considering both effectiveness and efficiency, we develop a global-local structure for our MVT. Our experiments on two public benchmarks, ModelNet40 and ModelNet10, demonstrate the competitive performance of our MVT.
Fed-LAMB: Layerwise and Dimensionwise Locally Adaptive Optimization Algorithm
Oct 01, 2021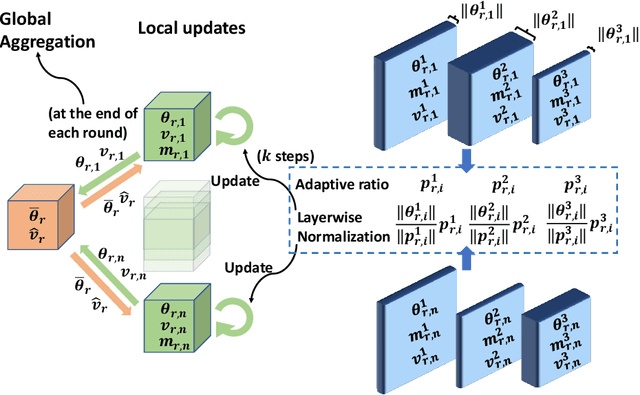

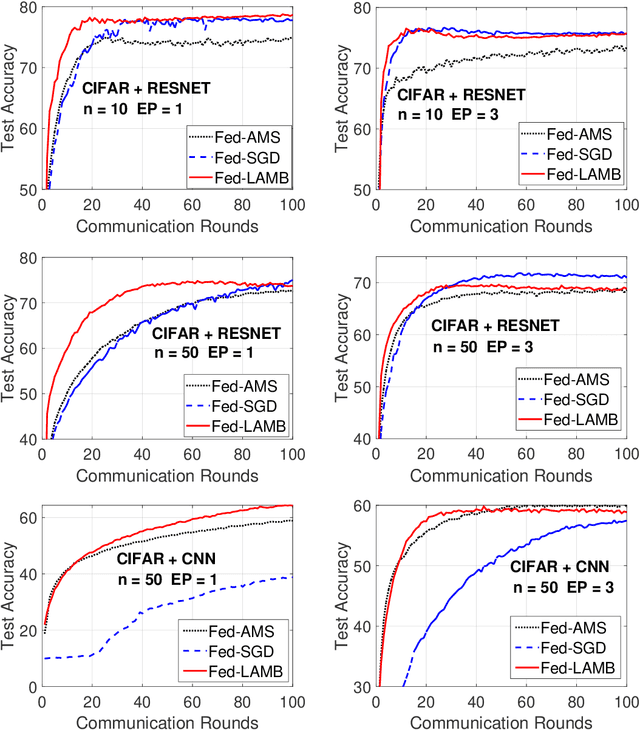
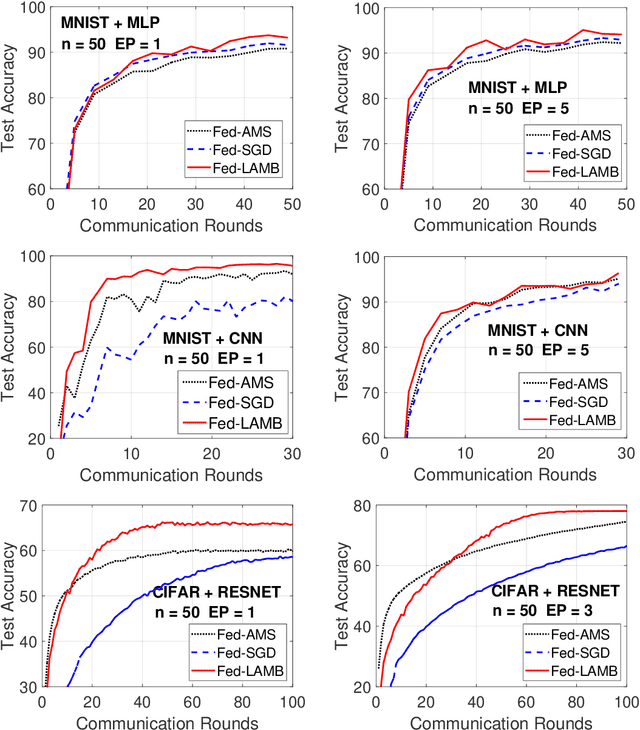
In the emerging paradigm of federated learning (FL), large amount of clients, such as mobile devices, are used to train possibly high-dimensional models on their respective data. Due to the low bandwidth of mobile devices, decentralized optimization methods need to shift the computation burden from those clients to the computation server while preserving privacy and reasonable communication cost. In this paper, we focus on the training of deep, as in multilayered, neural networks, under the FL settings. We present Fed-LAMB, a novel federated learning method based on a layerwise and dimensionwise updates of the local models, alleviating the nonconvexity and the multilayered nature of the optimization task at hand. We provide a thorough finite-time convergence analysis for Fed-LAMB characterizing how fast its gradient decreases. We provide experimental results under iid and non-iid settings to corroborate not only our theory, but also exhibit the faster convergence of our method, compared to the state-of-the-art.