 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Algorithmic Deductive Circuits for Logical Reasoning
May 27, 2026Recent studies have shown that Large Language Models (LLMs) can achieve strong reasoning performance by incorporating functional symbolic representations that abstractly describe graph traversal algorithms and step-by-step reasoning in few-shot learning settings. However, it remains unclear how LLMs genuinely understand the abstract meaning of each reasoning step and the overall algorithm from only a limited number of demonstrations. This work aims to localize the attention heads responsible for individual reasoning steps and characterize the types of information transferred among them. We first align constituent reasoning steps with their corresponding token logits under a symbolic-aided Chain-of-Thought (CoT) prompting framework. Our analysis shows that token positions that steer the reasoning process are associated with low confidence scores caused by constraints on satisfying reasoning behavior patterns in demonstrations. We then adopt causal mediation analysis techniques to identify the attention heads responsible for these patterns. In addition, our findings indicate that LLMs retrieve factual and rule-based information for individual sub-reasoning tasks through specialized attention heads (approximately 3% total heads), whereas higher layers predominantly facilitate information integration and the emergence of global reasoning strategies (e.g., graph traversal algorithms) that coordinate multiple intermediate reasoning steps to solve the overall task.
Legal2LogicICL: Improving Generalization in Transforming Legal Cases to Logical Formulas via Diverse Few-Shot Learning
Apr 13, 2026This work aims to improve the generalization of logic-based legal reasoning systems by integrating recent advances in NLP with legal-domain adaptive few-shot learning techniques using LLMs. Existing logic-based legal reasoning pipelines typically rely on fine-tuned models to map natural-language legal cases into logical formulas before forwarding them to a symbolic reasoner. However, such approaches are heavily constrained by the scarcity of high-quality annotated training data. To address this limitation, we propose a novel LLM-based legal reasoning framework that enables effective in-context learning through retrieval-augmented generation. Specifically, we introduce Legal2LogicICL, a few-shot retrieval framework that balances diversity and similarity of exemplars at both the latent semantic representation level and the legal text structure level. In addition, our method explicitly accounts for legal structure by mitigating entity-induced retrieval bias in legal texts, where lengthy and highly specific entity mentions often dominate semantic representations and obscure legally meaningful reasoning patterns. Our Legal2LogicICL constructs informative and robust few-shot demonstrations, leading to accurate and stable logical rule generation without requiring additional training. In addition, we construct a new dataset, named Legal2Proleg, which is annotated with alignments between legal cases and PROLEG logical formulas to support the evaluation of legal semantic parsing. Experimental results on both open-source and proprietary LLMs demonstrate that our approach significantly improves accuracy, stability, and generalization in transforming natural-language legal case descriptions into logical representations, highlighting its effectiveness for interpretable and reliable legal reasoning. Our code is available at https://github.com/yingjie7/Legal2LogicICL.
Goose: Anisotropic Speculation Trees for Training-Free Speculative Decoding
Apr 02, 2026Speculative decoding accelerates large language model inference by drafting multiple candidate tokens and verifying them in a single forward pass. Candidates are organized as a tree: deeper trees accept more tokens per step, but adding depth requires sacrificing breadth (fallback options) under a fixed verification budget. Existing training-free methods draft from a single token source and shape their trees without distinguishing candidate quality across origins. We observe that two common training-free token sources - n-gram matches copied from the input context, and statistical predictions from prior forward passes - differ dramatically in acceptance rate (~6x median gap, range 2-18x across five models and five benchmarks). We prove that when such a quality gap exists, the optimal tree is anisotropic (asymmetric): reliable tokens should form a deep chain while unreliable tokens spread as wide branches, breaking through the depth limit of balanced trees. We realize this structure in GOOSE, a training-free framework that builds an adaptive spine tree - a deep chain of high-acceptance context-matched tokens with wide branches of low-acceptance alternatives at each node. We prove that the number of tokens accepted per step is at least as large as that of either source used alone. On five LLMs (7B-33B) and five benchmarks, GOOSE achieves 1.9-4.3x lossless speedup, outperforming balanced-tree baselines by 12-33% under the same budget.
Span Modeling for Idiomaticity and Figurative Language Detection with Span Contrastive Loss
Mar 24, 2026The category of figurative language contains many varieties, some of which are non-compositional in nature. This type of phrase or multi-word expression (MWE) includes idioms, which represent a single meaning that does not consist of the sum of its words. For language models, this presents a unique problem due to tokenization and adjacent contextual embeddings. Many large language models have overcome this issue with large phrase vocabulary, though immediate recognition frequently fails without one- or few-shot prompting or instruction finetuning. The best results have been achieved with BERT-based or LSTM finetuning approaches. The model in this paper contains one such variety. We propose BERT- and RoBERTa-based models finetuned with a combination of slot loss and span contrastive loss (SCL) with hard negative reweighting to improve idiomaticity detection, attaining state of the art sequence accuracy performance on existing datasets. Comparative ablation studies show the effectiveness of SCL and its generalizability. The geometric mean of F1 and sequence accuracy (SA) is also proposed to assess a model's span awareness and general performance together.
Non-Iterative Symbolic-Aided Chain-of-Thought for Logical Reasoning
Aug 17, 2025This work introduces Symbolic-Aided Chain-of-Thought (CoT), an improved approach to standard CoT, for logical reasoning in large language models (LLMs). The key idea is to integrate lightweight symbolic representations into few-shot prompts, structuring the inference steps with a consistent strategy to make reasoning patterns more explicit within a non-iterative reasoning process. By incorporating these symbolic structures, our method preserves the generalizability of standard prompting techniques while enhancing the transparency, interpretability, and analyzability of LLM logical reasoning. Extensive experiments on four well-known logical reasoning benchmarks -- ProofWriter, FOLIO, ProntoQA, and LogicalDeduction, which cover diverse reasoning scenarios -- demonstrate the effectiveness of the proposed approach, particularly in complex reasoning tasks that require navigating multiple constraints or rules. Notably, Symbolic-Aided CoT consistently improves LLMs' reasoning capabilities across various model sizes and significantly outperforms conventional CoT on three out of four datasets, ProofWriter, ProntoQA, and LogicalDeduction.
JNLP at SemEval-2025 Task 11: Cross-Lingual Multi-Label Emotion Detection Using Generative Models
May 19, 2025With the rapid advancement of global digitalization, users from different countries increasingly rely on social media for information exchange. In this context, multilingual multi-label emotion detection has emerged as a critical research area. This study addresses SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection. Our paper focuses on two sub-tracks of this task: (1) Track A: Multi-label emotion detection, and (2) Track B: Emotion intensity. To tackle multilingual challenges, we leverage pre-trained multilingual models and focus on two architectures: (1) a fine-tuned BERT-based classification model and (2) an instruction-tuned generative LLM. Additionally, we propose two methods for handling multi-label classification: the base method, which maps an input directly to all its corresponding emotion labels, and the pairwise method, which models the relationship between the input text and each emotion category individually. Experimental results demonstrate the strong generalization ability of our approach in multilingual emotion recognition. In Track A, our method achieved Top 4 performance across 10 languages, ranking 1st in Hindi. In Track B, our approach also secured Top 5 performance in 7 languages, highlighting its simplicity and effectiveness\footnote{Our code is available at https://github.com/yingjie7/mlingual_multilabel_emo_detection.
An Effective Method using Phrase Mechanism in Neural Machine Translation
Aug 22, 2023Machine Translation is one of the essential tasks in Natural Language Processing (NLP), which has massive applications in real life as well as contributing to other tasks in the NLP research community. Recently, Transformer -based methods have attracted numerous researchers in this domain and achieved state-of-the-art results in most of the pair languages. In this paper, we report an effective method using a phrase mechanism, PhraseTransformer, to improve the strong baseline model Transformer in constructing a Neural Machine Translation (NMT) system for parallel corpora Vietnamese-Chinese. Our experiments on the MT dataset of the VLSP 2022 competition achieved the BLEU score of 35.3 on Vietnamese to Chinese and 33.2 BLEU scores on Chinese to Vietnamese data. Our code is available at https://github.com/phuongnm94/PhraseTransformer.
Miko Team: Deep Learning Approach for Legal Question Answering in ALQAC 2022
Nov 04, 2022We introduce efficient deep learning-based methods for legal document processing including Legal Document Retrieval and Legal Question Answering tasks in the Automated Legal Question Answering Competition (ALQAC 2022). In this competition, we achieve 1\textsuperscript{st} place in the first task and 3\textsuperscript{rd} place in the second task. Our method is based on the XLM-RoBERTa model that is pre-trained from a large amount of unlabeled corpus before fine-tuning to the specific tasks. The experimental results showed that our method works well in legal retrieval information tasks with limited labeled data. Besides, this method can be applied to other information retrieval tasks in low-resource languages.
JNLP Team: Deep Learning Approaches for Legal Processing Tasks in COLIEE 2021
Jun 25, 2021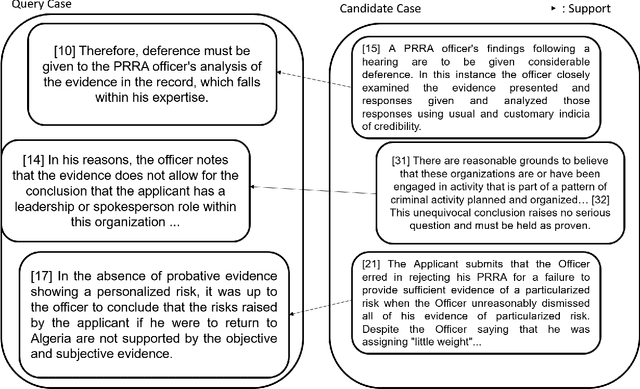

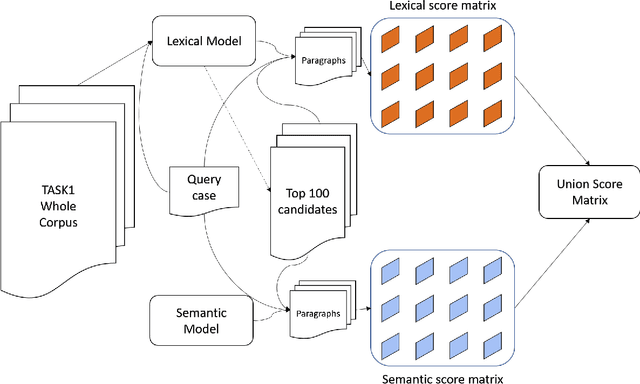

COLIEE is an annual competition in automatic computerized legal text processing. Automatic legal document processing is an ambitious goal, and the structure and semantics of the law are often far more complex than everyday language. In this article, we survey and report our methods and experimental results in using deep learning in legal document processing. The results show the difficulties as well as potentials in this family of approaches.
ParaLaw Nets -- Cross-lingual Sentence-level Pretraining for Legal Text Processing
Jun 25, 2021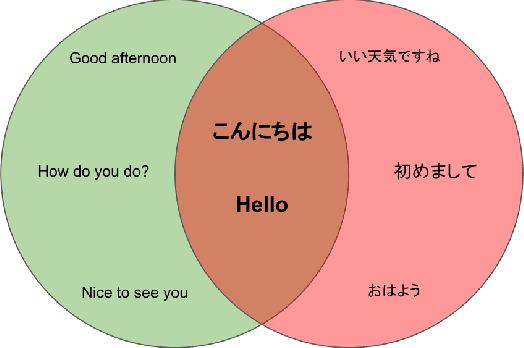
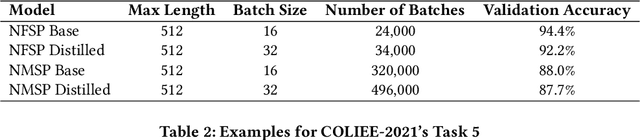
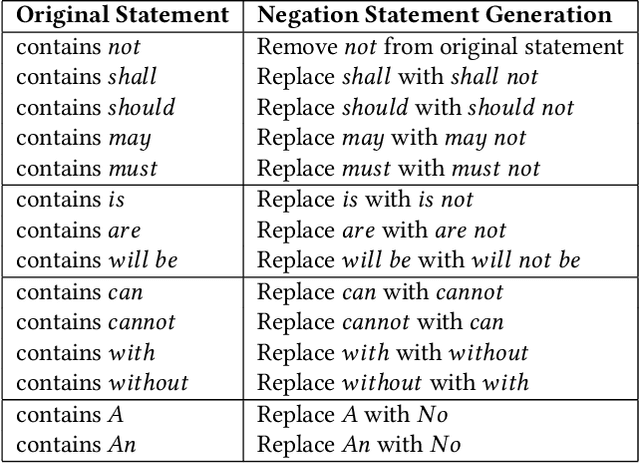
Ambiguity is a characteristic of natural language, which makes expression ideas flexible. However, in a domain that requires accurate statements, it becomes a barrier. Specifically, a single word can have many meanings and multiple words can have the same meaning. When translating a text into a foreign language, the translator needs to determine the exact meaning of each element in the original sentence to produce the correct translation sentence. From that observation, in this paper, we propose ParaLaw Nets, a pretrained model family using sentence-level cross-lingual information to reduce ambiguity and increase the performance in legal text processing. This approach achieved the best result in the Question Answering task of COLIEE-2021.