 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPR Auto-Formalization with AI Agents and Human Verification
Apr 16, 2026We study the overall process of automatic formalization of GDPR provisions using large language models, within a human-in-the-loop verification framework. Rather than aiming for full autonomy, we adopt a role-specialized workflow in which LLM-based AI components, operating in a multi-agent setting with iterative feedback, generate legal scenarios, formal rules, and atomic facts. This is coupled with independent verification modules which include human reviewers' assessment of representational, logical, and legal correctness. Using this approach, we construct a high-quality dataset to be used for GDPR auto-formalization, and analyze both successful and problematic cases. Our results show that structured verification and targeted human oversight are essential for reliable legal formalization, especially in the presence of legal nuance and context-sensitive reasoning.
Legal2LogicICL: Improving Generalization in Transforming Legal Cases to Logical Formulas via Diverse Few-Shot Learning
Apr 13, 2026This work aims to improve the generalization of logic-based legal reasoning systems by integrating recent advances in NLP with legal-domain adaptive few-shot learning techniques using LLMs. Existing logic-based legal reasoning pipelines typically rely on fine-tuned models to map natural-language legal cases into logical formulas before forwarding them to a symbolic reasoner. However, such approaches are heavily constrained by the scarcity of high-quality annotated training data. To address this limitation, we propose a novel LLM-based legal reasoning framework that enables effective in-context learning through retrieval-augmented generation. Specifically, we introduce Legal2LogicICL, a few-shot retrieval framework that balances diversity and similarity of exemplars at both the latent semantic representation level and the legal text structure level. In addition, our method explicitly accounts for legal structure by mitigating entity-induced retrieval bias in legal texts, where lengthy and highly specific entity mentions often dominate semantic representations and obscure legally meaningful reasoning patterns. Our Legal2LogicICL constructs informative and robust few-shot demonstrations, leading to accurate and stable logical rule generation without requiring additional training. In addition, we construct a new dataset, named Legal2Proleg, which is annotated with alignments between legal cases and PROLEG logical formulas to support the evaluation of legal semantic parsing. Experimental results on both open-source and proprietary LLMs demonstrate that our approach significantly improves accuracy, stability, and generalization in transforming natural-language legal case descriptions into logical representations, highlighting its effectiveness for interpretable and reliable legal reasoning. Our code is available at https://github.com/yingjie7/Legal2LogicICL.
A negation detection assessment of GPTs: analysis with the xNot360 dataset
Jun 29, 2023



Negation is a fundamental aspect of natural language, playing a critical role in communication and comprehension. Our study assesses the negation detection performance of Generative Pre-trained Transformer (GPT) models, specifically GPT-2, GPT-3, GPT-3.5, and GPT-4. We focus on the identification of negation in natural language using a zero-shot prediction approach applied to our custom xNot360 dataset. Our approach examines sentence pairs labeled to indicate whether the second sentence negates the first. Our findings expose a considerable performance disparity among the GPT models, with GPT-4 surpassing its counterparts and GPT-3.5 displaying a marked performance reduction. The overall proficiency of the GPT models in negation detection remains relatively modest, indicating that this task pushes the boundaries of their natural language understanding capabilities. We not only highlight the constraints of GPT models in handling negation but also emphasize the importance of logical reliability in high-stakes domains such as healthcare, science, and law.
VSEC: Transformer-based Model for Vietnamese Spelling Correction
Nov 09, 2021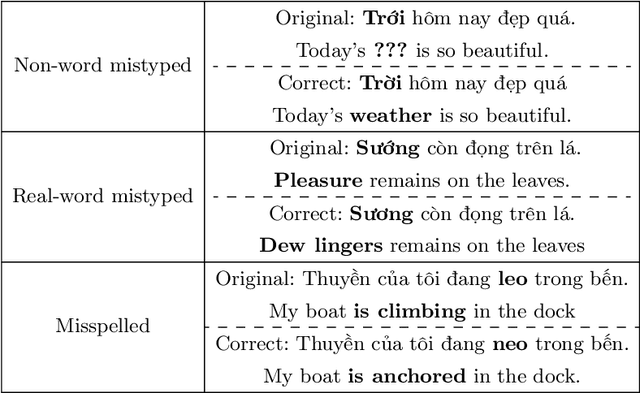
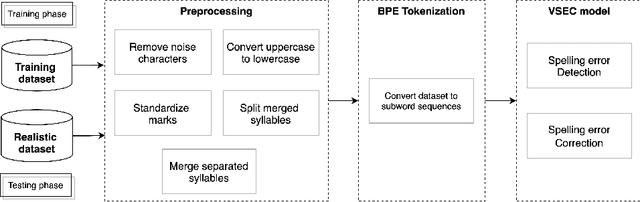


Spelling error correction is one of topics which have a long history in natural language processing. Although previous studies have achieved remarkable results, challenges still exist. In the Vietnamese language, a state-of-the-art method for the task infers a syllable's context from its adjacent syllables. The method's accuracy can be unsatisfactory, however, because the model may lose the context if two (or more) spelling mistakes stand near each other. In this paper, we propose a novel method to correct Vietnamese spelling errors. We tackle the problems of mistyped errors and misspelled errors by using a deep learning model. The embedding layer, in particular, is powered by the byte pair encoding technique. The sequence to sequence model based on the Transformer architecture makes our approach different from the previous works on the same problem. In the experiment, we train the model with a large synthetic dataset, which is randomly introduced spelling errors. We test the performance of the proposed method using a realistic dataset. This dataset contains 11,202 human-made misspellings in 9,341 different Vietnamese sentences. The experimental results show that our method achieves encouraging performance with 86.8% errors detected and 81.5% errors corrected, which improves the state-of-the-art approach 5.6% and 2.2%, respectively.