 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpan Modeling for Idiomaticity and Figurative Language Detection with Span Contrastive Loss
Mar 24, 2026The category of figurative language contains many varieties, some of which are non-compositional in nature. This type of phrase or multi-word expression (MWE) includes idioms, which represent a single meaning that does not consist of the sum of its words. For language models, this presents a unique problem due to tokenization and adjacent contextual embeddings. Many large language models have overcome this issue with large phrase vocabulary, though immediate recognition frequently fails without one- or few-shot prompting or instruction finetuning. The best results have been achieved with BERT-based or LSTM finetuning approaches. The model in this paper contains one such variety. We propose BERT- and RoBERTa-based models finetuned with a combination of slot loss and span contrastive loss (SCL) with hard negative reweighting to improve idiomaticity detection, attaining state of the art sequence accuracy performance on existing datasets. Comparative ablation studies show the effectiveness of SCL and its generalizability. The geometric mean of F1 and sequence accuracy (SA) is also proposed to assess a model's span awareness and general performance together.
JNLP at SemEval-2025 Task 11: Cross-Lingual Multi-Label Emotion Detection Using Generative Models
May 19, 2025With the rapid advancement of global digitalization, users from different countries increasingly rely on social media for information exchange. In this context, multilingual multi-label emotion detection has emerged as a critical research area. This study addresses SemEval-2025 Task 11: Bridging the Gap in Text-Based Emotion Detection. Our paper focuses on two sub-tracks of this task: (1) Track A: Multi-label emotion detection, and (2) Track B: Emotion intensity. To tackle multilingual challenges, we leverage pre-trained multilingual models and focus on two architectures: (1) a fine-tuned BERT-based classification model and (2) an instruction-tuned generative LLM. Additionally, we propose two methods for handling multi-label classification: the base method, which maps an input directly to all its corresponding emotion labels, and the pairwise method, which models the relationship between the input text and each emotion category individually. Experimental results demonstrate the strong generalization ability of our approach in multilingual emotion recognition. In Track A, our method achieved Top 4 performance across 10 languages, ranking 1st in Hindi. In Track B, our approach also secured Top 5 performance in 7 languages, highlighting its simplicity and effectiveness\footnote{Our code is available at https://github.com/yingjie7/mlingual_multilabel_emo_detection.
Multimodal Contrastive In-Context Learning
Aug 23, 2024



The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
A Decoupling and Aggregating Framework for Joint Extraction of Entities and Relations
May 14, 2024



Named Entity Recognition and Relation Extraction are two crucial and challenging subtasks in the field of Information Extraction. Despite the successes achieved by the traditional approaches, fundamental research questions remain open. First, most recent studies use parameter sharing for a single subtask or shared features for both two subtasks, ignoring their semantic differences. Second, information interaction mainly focuses on the two subtasks, leaving the fine-grained informtion interaction among the subtask-specific features of encoding subjects, relations, and objects unexplored. Motivated by the aforementioned limitations, we propose a novel model to jointly extract entities and relations. The main novelties are as follows: (1) We propose to decouple the feature encoding process into three parts, namely encoding subjects, encoding objects, and encoding relations. Thanks to this, we are able to use fine-grained subtask-specific features. (2) We propose novel inter-aggregation and intra-aggregation strategies to enhance the information interaction and construct individual fine-grained subtask-specific features, respectively. The experimental results demonstrate that our model outperforms several previous state-of-the-art models. Extensive additional experiments further confirm the effectiveness of our model.
Encoded Summarization: Summarizing Documents into Continuous Vector Space for Legal Case Retrieval
Sep 15, 2023We present our method for tackling a legal case retrieval task by introducing our method of encoding documents by summarizing them into continuous vector space via our phrase scoring framework utilizing deep neural networks. On the other hand, we explore the benefits from combining lexical features and latent features generated with neural networks. Our experiments show that lexical features and latent features generated with neural networks complement each other to improve the retrieval system performance. Furthermore, our experimental results suggest the importance of case summarization in different aspects: using provided summaries and performing encoded summarization. Our approach achieved F1 of 65.6% and 57.6% on the experimental datasets of legal case retrieval tasks.
Causal Intersectionality and Dual Form of Gradient Descent for Multimodal Analysis: a Case Study on Hateful Memes
Aug 19, 2023In the wake of the explosive growth of machine learning (ML) usage, particularly within the context of emerging Large Language Models (LLMs), comprehending the semantic significance rooted in their internal workings is crucial. While causal analyses focus on defining semantics and its quantification, the gradient-based approach is central to explainable AI (XAI), tackling the interpretation of the black box. By synergizing these approaches, the exploration of how a model's internal mechanisms illuminate its causal effect has become integral for evidence-based decision-making. A parallel line of research has revealed that intersectionality - the combinatory impact of multiple demographics of an individual - can be structured in the form of an Averaged Treatment Effect (ATE). Initially, this study illustrates that the hateful memes detection problem can be formulated as an ATE, assisted by the principles of intersectionality, and that a modality-wise summarization of gradient-based attention attribution scores can delineate the distinct behaviors of three Transformerbased models concerning ATE. Subsequently, we show that the latest LLM LLaMA2 has the ability to disentangle the intersectional nature of memes detection in an in-context learning setting, with their mechanistic properties elucidated via meta-gradient, a secondary form of gradient. In conclusion, this research contributes to the ongoing dialogue surrounding XAI and the multifaceted nature of ML models.
Miko Team: Deep Learning Approach for Legal Question Answering in ALQAC 2022
Nov 04, 2022We introduce efficient deep learning-based methods for legal document processing including Legal Document Retrieval and Legal Question Answering tasks in the Automated Legal Question Answering Competition (ALQAC 2022). In this competition, we achieve 1\textsuperscript{st} place in the first task and 3\textsuperscript{rd} place in the second task. Our method is based on the XLM-RoBERTa model that is pre-trained from a large amount of unlabeled corpus before fine-tuning to the specific tasks. The experimental results showed that our method works well in legal retrieval information tasks with limited labeled data. Besides, this method can be applied to other information retrieval tasks in low-resource languages.
JNLP Team: Deep Learning Approaches for Legal Processing Tasks in COLIEE 2021
Jun 25, 2021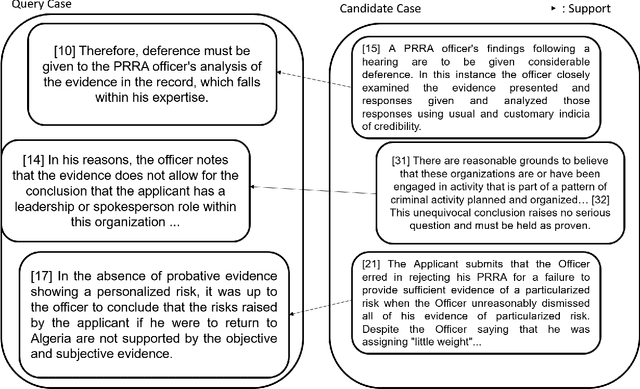

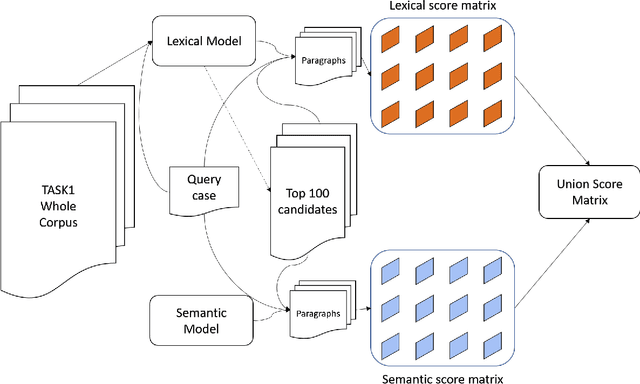

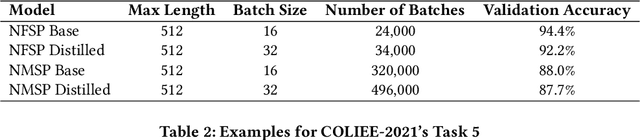
COLIEE is an annual competition in automatic computerized legal text processing. Automatic legal document processing is an ambitious goal, and the structure and semantics of the law are often far more complex than everyday language. In this article, we survey and report our methods and experimental results in using deep learning in legal document processing. The results show the difficulties as well as potentials in this family of approaches.
ParaLaw Nets -- Cross-lingual Sentence-level Pretraining for Legal Text Processing
Jun 25, 2021
Ambiguity is a characteristic of natural language, which makes expression ideas flexible. However, in a domain that requires accurate statements, it becomes a barrier. Specifically, a single word can have many meanings and multiple words can have the same meaning. When translating a text into a foreign language, the translator needs to determine the exact meaning of each element in the original sentence to produce the correct translation sentence. From that observation, in this paper, we propose ParaLaw Nets, a pretrained model family using sentence-level cross-lingual information to reduce ambiguity and increase the performance in legal text processing. This approach achieved the best result in the Question Answering task of COLIEE-2021.
JNLP Team: Deep Learning for Legal Processing in COLIEE 2020
Nov 04, 2020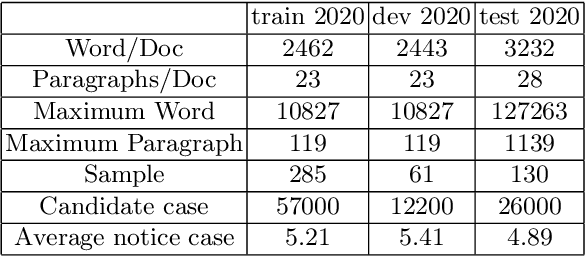
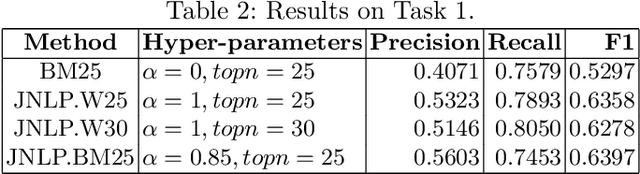
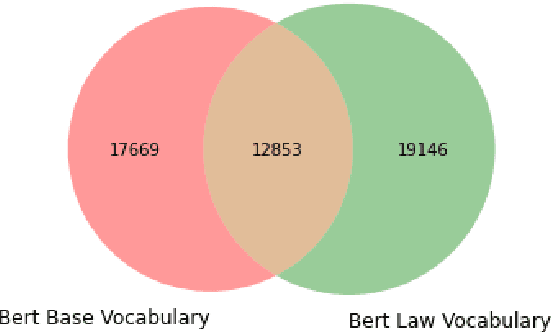
We propose deep learning based methods for automatic systems of legal retrieval and legal question-answering in COLIEE 2020. These systems are all characterized by being pre-trained on large amounts of data before being finetuned for the specified tasks. This approach helps to overcome the data scarcity and achieve good performance, thus can be useful for tackling related problems in information retrieval, and decision support in the legal domain. Besides, the approach can be explored to deal with other domain specific problems.