 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep what you need : extracting efficient subnetworks from large audio representation models
Feb 18, 2025


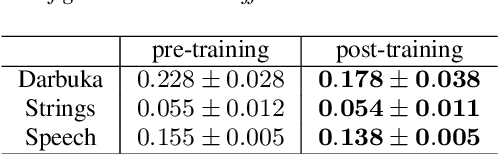
Recently, research on audio foundation models has witnessed notable advances, as illustrated by the ever improving results on complex downstream tasks. Subsequently, those pretrained networks have quickly been used for various audio applications. These improvements have however resulted in a considerable increase both in size and complexity of these models. Along the environmental concerns this issue raises, this prevents the deployment of such networks on consumer-level devices, and precludes their use for real-time applications. Moreover, this appears contradictory with the specificity of the tasks for which these models are used, which are often simpler compared to extracting a rich, multi-purpose representation from any type of audio data. In this paper, we address this issue with a simple, yet effective method to extract lightweight specialist subnetworks from large foundation models. Specifically, we introduce learnable binary masks in-between the layers of a pretrained representation model. When training the end-to-end model on a downstream task, we add a sparsity-inducing loss to the overall objective, hence learning a compact subnetwork specialized on a single task. Importantly, the weights of the foundation model are kept frozen, resulting into low additional training costs. Once trained, the masked computational units can then be removed from the network, implying significant performance gains. We assess our method on three widespread audio foundation models, each based on a different backbone architecture, and illustrate its effectiveness on common audio representation evaluation tasks, as well as its versatility on both speech, music, and general audio. Code for reproducing the results and supporting webpage are available at https://github.com/gnvIRCAM/Audio-representation-trimming
Unsupervised Composable Representations for Audio
Aug 19, 2024



Current generative models are able to generate high-quality artefacts but have been shown to struggle with compositional reasoning, which can be defined as the ability to generate complex structures from simpler elements. In this paper, we focus on the problem of compositional representation learning for music data, specifically targeting the fully-unsupervised setting. We propose a simple and extensible framework that leverages an explicit compositional inductive bias, defined by a flexible auto-encoding objective that can leverage any of the current state-of-art generative models. We demonstrate that our framework, used with diffusion models, naturally addresses the task of unsupervised audio source separation, showing that our model is able to perform high-quality separation. Our findings reveal that our proposal achieves comparable or superior performance with respect to other blind source separation methods and, furthermore, it even surpasses current state-of-art supervised baselines on signal-to-interference ratio metrics. Additionally, by learning an a-posteriori masking diffusion model in the space of composable representations, we achieve a system capable of seamlessly performing unsupervised source separation, unconditional generation, and variation generation. Finally, as our proposal works in the latent space of pre-trained neural audio codecs, it also provides a lower computational cost with respect to other neural baselines.
Combining audio control and style transfer using latent diffusion
Jul 31, 2024



Deep generative models are now able to synthesize high-quality audio signals, shifting the critical aspect in their development from audio quality to control capabilities. Although text-to-music generation is getting largely adopted by the general public, explicit control and example-based style transfer are more adequate modalities to capture the intents of artists and musicians. In this paper, we aim to unify explicit control and style transfer within a single model by separating local and global information to capture musical structure and timbre respectively. To do so, we leverage the capabilities of diffusion autoencoders to extract semantic features, in order to build two representation spaces. We enforce disentanglement between those spaces using an adversarial criterion and a two-stage training strategy. Our resulting model can generate audio matching a timbre target, while specifying structure either with explicit controls or through another audio example. We evaluate our model on one-shot timbre transfer and MIDI-to-audio tasks on instrumental recordings and show that we outperform existing baselines in terms of audio quality and target fidelity. Furthermore, we show that our method can generate cover versions of complete musical pieces by transferring rhythmic and melodic content to the style of a target audio in a different genre.
* ISMIR 2024
Continuous descriptor-based control for deep audio synthesis
Feb 27, 2023Despite significant advances in deep models for music generation, the use of these techniques remains restricted to expert users. Before being democratized among musicians, generative models must first provide expressive control over the generation, as this conditions the integration of deep generative models in creative workflows. In this paper, we tackle this issue by introducing a deep generative audio model providing expressive and continuous descriptor-based control, while remaining lightweight enough to be embedded in a hardware synthesizer. We enforce the controllability of real-time generation by explicitly removing salient musical features in the latent space using an adversarial confusion criterion. User-specified features are then reintroduced as additional conditioning information, allowing for continuous control of the generation, akin to a synthesizer knob. We assess the performance of our method on a wide variety of sounds including instrumental, percussive and speech recordings while providing both timbre and attributes transfer, allowing new ways of generating sounds.
SingSong: Generating musical accompaniments from singing
Jan 30, 2023



We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
Creative divergent synthesis with generative models
Nov 16, 2022Machine learning approaches now achieve impressive generation capabilities in numerous domains such as image, audio or video. However, most training \& evaluation frameworks revolve around the idea of strictly modelling the original data distribution rather than trying to extrapolate from it. This precludes the ability of such models to diverge from the original distribution and, hence, exhibit some creative traits. In this paper, we propose various perspectives on how this complicated goal could ever be achieved, and provide preliminary results on our novel training objective called \textit{Bounded Adversarial Divergence} (BAD).
Challenges in creative generative models for music: a divergence maximization perspective
Nov 16, 2022The development of generative Machine Learning (ML) models in creative practices, enabled by the recent improvements in usability and availability of pre-trained models, is raising more and more interest among artists, practitioners and performers. Yet, the introduction of such techniques in artistic domains also revealed multiple limitations that escape current evaluation methods used by scientists. Notably, most models are still unable to generate content that lay outside of the domain defined by the training dataset. In this paper, we propose an alternative prospective framework, starting from a new general formulation of ML objectives, that we derive to delineate possible implications and solutions that already exist in the ML literature (notably for the audio and musical domain). We also discuss existing relations between generative models and computational creativity and how our framework could help address the lack of creativity in existing models.
Streamable Neural Audio Synthesis With Non-Causal Convolutions
Apr 14, 2022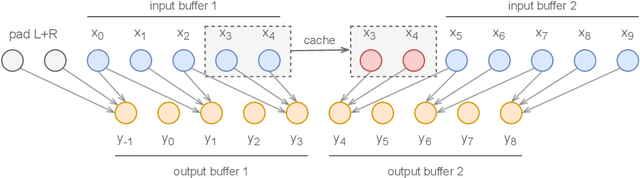
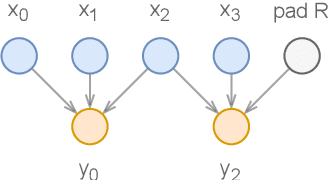
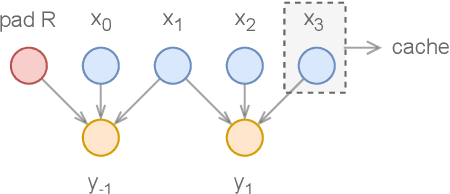
Deep learning models are mostly used in an offline inference fashion. However, this strongly limits the use of these models inside audio generation setups, as most creative workflows are based on real-time digital signal processing. Although approaches based on recurrent networks can be naturally adapted to this buffer-based computation, the use of convolutions still poses some serious challenges. To tackle this issue, the use of causal streaming convolutions have been proposed. However, this requires specific complexified training and can impact the resulting audio quality. In this paper, we introduce a new method allowing to produce non-causal streaming models. This allows to make any convolutional model compatible with real-time buffer-based processing. As our method is based on a post-training reconfiguration of the model, we show that it is able to transform models trained without causal constraints into a streaming model. We show how our method can be adapted to fit complex architectures with parallel branches. To evaluate our method, we apply it on the recent RAVE model, which provides high-quality real-time audio synthesis. We test our approach on multiple music and speech datasets and show that it is faster than overlap-add methods, while having no impact on the generation quality. Finally, we introduce two open-source implementation of our work as Max/MSP and PureData externals, and as a VST audio plugin. This allows to endow traditional digital audio workstation with real-time neural audio synthesis on a laptop CPU.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022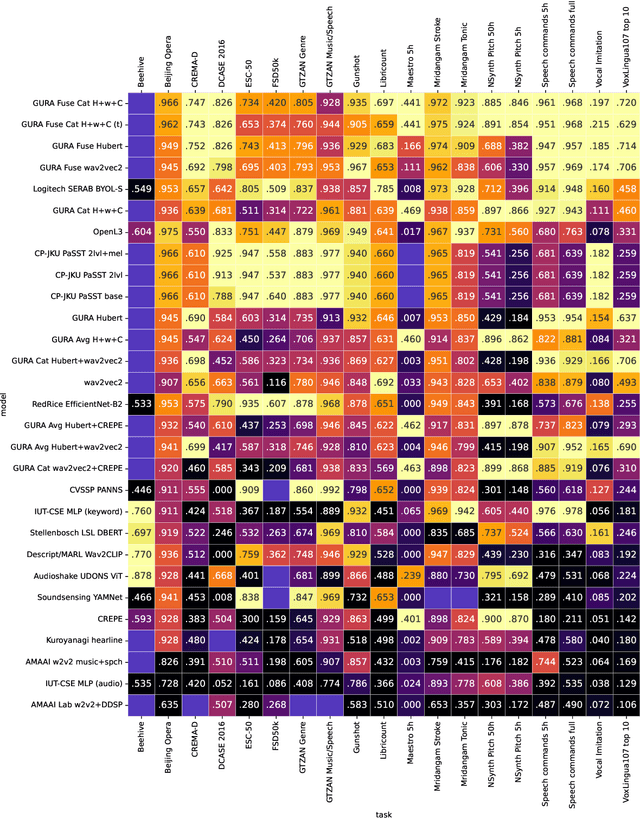
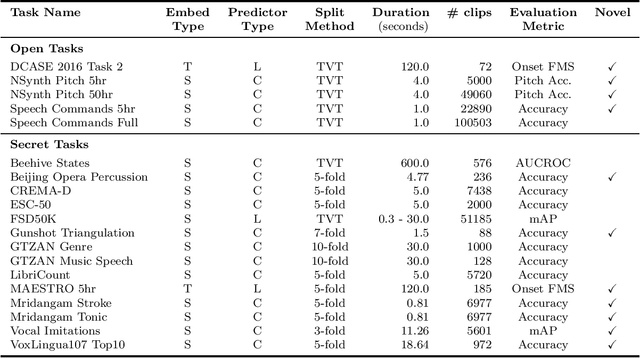

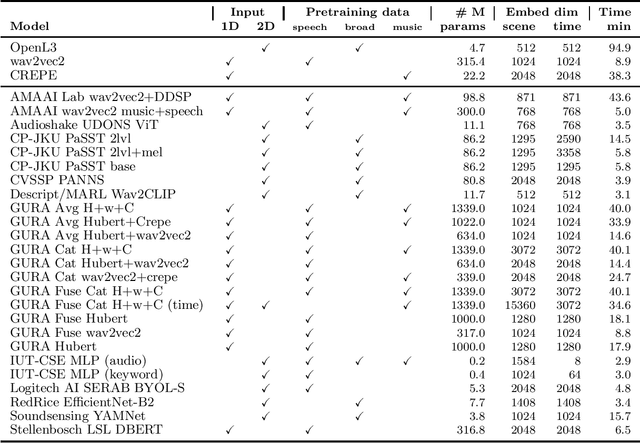
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
RAVE: A variational autoencoder for fast and high-quality neural audio synthesis
Nov 09, 2021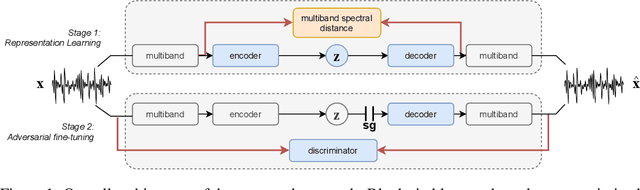
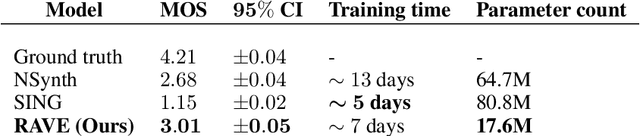
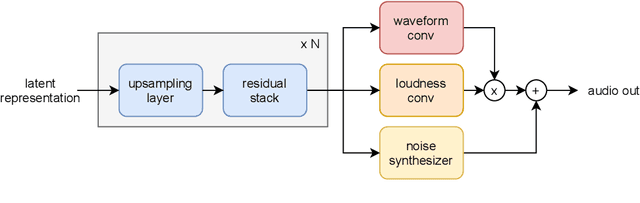

Deep generative models applied to audio have improved by a large margin the state-of-the-art in many speech and music related tasks. However, as raw waveform modelling remains an inherently difficult task, audio generative models are either computationally intensive, rely on low sampling rates, are complicated to control or restrict the nature of possible signals. Among those models, Variational AutoEncoders (VAE) give control over the generation by exposing latent variables, although they usually suffer from low synthesis quality. In this paper, we introduce a Realtime Audio Variational autoEncoder (RAVE) allowing both fast and high-quality audio waveform synthesis. We introduce a novel two-stage training procedure, namely representation learning and adversarial fine-tuning. We show that using a post-training analysis of the latent space allows a direct control between the reconstruction fidelity and the representation compactness. By leveraging a multi-band decomposition of the raw waveform, we show that our model is the first able to generate 48kHz audio signals, while simultaneously running 20 times faster than real-time on a standard laptop CPU. We evaluate synthesis quality using both quantitative and qualitative subjective experiments and show the superiority of our approach compared to existing models. Finally, we present applications of our model for timbre transfer and signal compression. All of our source code and audio examples are publicly available.