 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language Foundation Model for Zero-shot Clinical Collaboration and Automated Concept Discovery in Dermatology
Feb 11, 2026Medical foundation models have shown promise in controlled benchmarks, yet widespread deployment remains hindered by reliance on task-specific fine-tuning. Here, we introduce DermFM-Zero, a dermatology vision-language foundation model trained via masked latent modelling and contrastive learning on over 4 million multimodal data points. We evaluated DermFM-Zero across 20 benchmarks spanning zero-shot diagnosis and multimodal retrieval, achieving state-of-the-art performance without task-specific adaptation. We further evaluated its zero-shot capabilities in three multinational reader studies involving over 1,100 clinicians. In primary care settings, AI assistance enabled general practitioners to nearly double their differential diagnostic accuracy across 98 skin conditions. In specialist settings, the model significantly outperformed board-certified dermatologists in multimodal skin cancer assessment. In collaborative workflows, AI assistance enabled non-experts to surpass unassisted experts while improving management appropriateness. Finally, we show that DermFM-Zero's latent representations are interpretable: sparse autoencoders unsupervisedly disentangle clinically meaningful concepts that outperform predefined-vocabulary approaches and enable targeted suppression of artifact-induced biases, enhancing robustness without retraining. These findings demonstrate that a foundation model can provide effective, safe, and transparent zero-shot clinical decision support.
Explainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
CleanPatrick: A Benchmark for Image Data Cleaning
May 16, 2025Robust machine learning depends on clean data, yet current image data cleaning benchmarks rely on synthetic noise or narrow human studies, limiting comparison and real-world relevance. We introduce CleanPatrick, the first large-scale benchmark for data cleaning in the image domain, built upon the publicly available Fitzpatrick17k dermatology dataset. We collect 496,377 binary annotations from 933 medical crowd workers, identify off-topic samples (4%), near-duplicates (21%), and label errors (22%), and employ an aggregation model inspired by item-response theory followed by expert review to derive high-quality ground truth. CleanPatrick formalizes issue detection as a ranking task and adopts typical ranking metrics mirroring real audit workflows. Benchmarking classical anomaly detectors, perceptual hashing, SSIM, Confident Learning, NoiseRank, and SelfClean, we find that, on CleanPatrick, self-supervised representations excel at near-duplicate detection, classical methods achieve competitive off-topic detection under constrained review budgets, and label-error detection remains an open challenge for fine-grained medical classification. By releasing both the dataset and the evaluation framework, CleanPatrick enables a systematic comparison of image-cleaning strategies and paves the way for more reliable data-centric artificial intelligence.
Derm1M: A Million-scale Vision-Language Dataset Aligned with Clinical Ontology Knowledge for Dermatology
Mar 19, 2025The emergence of vision-language models has transformed medical AI, enabling unprecedented advances in diagnostic capability and clinical applications. However, progress in dermatology has lagged behind other medical domains due to the lack of standard image-text pairs. Existing dermatological datasets are limited in both scale and depth, offering only single-label annotations across a narrow range of diseases instead of rich textual descriptions, and lacking the crucial clinical context needed for real-world applications. To address these limitations, we present Derm1M, the first large-scale vision-language dataset for dermatology, comprising 1,029,761 image-text pairs. Built from diverse educational resources and structured around a standard ontology collaboratively developed by experts, Derm1M provides comprehensive coverage for over 390 skin conditions across four hierarchical levels and 130 clinical concepts with rich contextual information such as medical history, symptoms, and skin tone. To demonstrate Derm1M potential in advancing both AI research and clinical application, we pretrained a series of CLIP-like models, collectively called DermLIP, on this dataset. The DermLIP family significantly outperforms state-of-the-art foundation models on eight diverse datasets across multiple tasks, including zero-shot skin disease classification, clinical and artifacts concept identification, few-shot/full-shot learning, and cross-modal retrieval. Our dataset and code will be public.
A General-Purpose Multimodal Foundation Model for Dermatology
Oct 19, 2024



Diagnosing and treating skin diseases require advanced visual skills across multiple domains and the ability to synthesize information from various imaging modalities. Current deep learning models, while effective at specific tasks such as diagnosing skin cancer from dermoscopic images, fall short in addressing the complex, multimodal demands of clinical practice. Here, we introduce PanDerm, a multimodal dermatology foundation model pretrained through self-supervised learning on a dataset of over 2 million real-world images of skin diseases, sourced from 11 clinical institutions across 4 imaging modalities. We evaluated PanDerm on 28 diverse datasets covering a range of clinical tasks, including skin cancer screening, phenotype assessment and risk stratification, diagnosis of neoplastic and inflammatory skin diseases, skin lesion segmentation, change monitoring, and metastasis prediction and prognosis. PanDerm achieved state-of-the-art performance across all evaluated tasks, often outperforming existing models even when using only 5-10% of labeled data. PanDerm's clinical utility was demonstrated through reader studies in real-world clinical settings across multiple imaging modalities. It outperformed clinicians by 10.2% in early-stage melanoma detection accuracy and enhanced clinicians' multiclass skin cancer diagnostic accuracy by 11% in a collaborative human-AI setting. Additionally, PanDerm demonstrated robust performance across diverse demographic factors, including different body locations, age groups, genders, and skin tones. The strong results in benchmark evaluations and real-world clinical scenarios suggest that PanDerm could enhance the management of skin diseases and serve as a model for developing multimodal foundation models in other medical specialties, potentially accelerating the integration of AI support in healthcare.
Automated dermatoscopic pattern discovery by clustering neural network output for human-computer interaction
Sep 15, 2023Background: As available medical image datasets increase in size, it becomes infeasible for clinicians to review content manually for knowledge extraction. The objective of this study was to create an automated clustering resulting in human-interpretable pattern discovery. Methods: Images from the public HAM10000 dataset, including 7 common pigmented skin lesion diagnoses, were tiled into 29420 tiles and clustered via k-means using neural network-extracted image features. The final number of clusters per diagnosis was chosen by either the elbow method or a compactness metric balancing intra-lesion variance and cluster numbers. The amount of resulting non-informative clusters, defined as those containing less than six image tiles, was compared between the two methods. Results: Applying k-means, the optimal elbow cutoff resulted in a mean of 24.7 (95%-CI: 16.4-33) clusters for every included diagnosis, including 14.9% (95% CI: 0.8-29.0) non-informative clusters. The optimal cutoff, as estimated by the compactness metric, resulted in significantly fewer clusters (13.4; 95%-CI 11.8-15.1; p=0.03) and less non-informative ones (7.5%; 95% CI: 0-19.5; p=0.017). The majority of clusters (93.6%) from the compactness metric could be manually mapped to previously described dermatoscopic diagnostic patterns. Conclusions: Automatically constraining unsupervised clustering can produce an automated extraction of diagnostically relevant and human-interpretable clusters of visual patterns from a large image dataset.
Dermatologist-like explainable AI enhances trust and confidence in diagnosing melanoma
Mar 17, 2023Although artificial intelligence (AI) systems have been shown to improve the accuracy of initial melanoma diagnosis, the lack of transparency in how these systems identify melanoma poses severe obstacles to user acceptance. Explainable artificial intelligence (XAI) methods can help to increase transparency, but most XAI methods are unable to produce precisely located domain-specific explanations, making the explanations difficult to interpret. Moreover, the impact of XAI methods on dermatologists has not yet been evaluated. Extending on two existing classifiers, we developed an XAI system that produces text and region based explanations that are easily interpretable by dermatologists alongside its differential diagnoses of melanomas and nevi. To evaluate this system, we conducted a three-part reader study to assess its impact on clinicians' diagnostic accuracy, confidence, and trust in the XAI-support. We showed that our XAI's explanations were highly aligned with clinicians' explanations and that both the clinicians' trust in the support system and their confidence in their diagnoses were significantly increased when using our XAI compared to using a conventional AI system. The clinicians' diagnostic accuracy was numerically, albeit not significantly, increased. This work demonstrates that clinicians are willing to adopt such an XAI system, motivating their future use in the clinic.
The Effects of Skin Lesion Segmentation on the Performance of Dermatoscopic Image Classification
Aug 28, 2020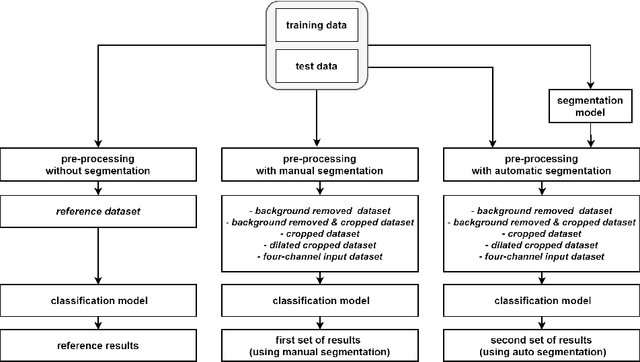
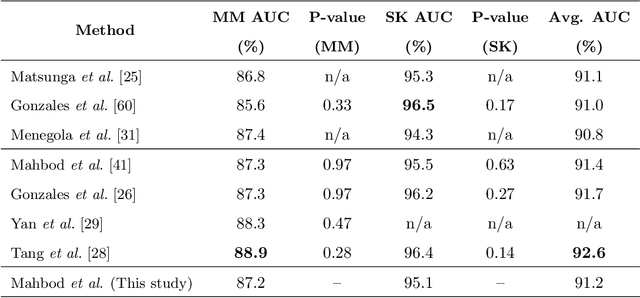
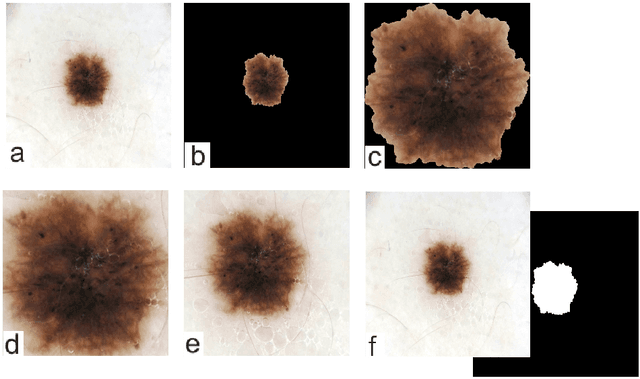
Malignant melanoma (MM) is one of the deadliest types of skin cancer. Analysing dermatoscopic images plays an important role in the early detection of MM and other pigmented skin lesions. Among different computer-based methods, deep learning-based approaches and in particular convolutional neural networks have shown excellent classification and segmentation performances for dermatoscopic skin lesion images. These models can be trained end-to-end without requiring any hand-crafted features. However, the effect of using lesion segmentation information on classification performance has remained an open question. In this study, we explicitly investigated the impact of using skin lesion segmentation masks on the performance of dermatoscopic image classification. To do this, first, we developed a baseline classifier as the reference model without using any segmentation masks. Then, we used either manually or automatically created segmentation masks in both training and test phases in different scenarios and investigated the classification performances. Evaluated on the ISIC 2017 challenge dataset which contained two binary classification tasks (i.e. MM vs. all and seborrheic keratosis (SK) vs. all) and based on the derived area under the receiver operating characteristic curve scores, we observed four main outcomes. Our results show that 1) using segmentation masks did not significantly improve the MM classification performance in any scenario, 2) in one of the scenarios (using segmentation masks for dilated cropping), SK classification performance was significantly improved, 3) removing all background information by the segmentation masks significantly degraded the overall classification performance, and 4) in case of using the appropriate scenario (using segmentation for dilated cropping), there is no significant difference of using manually or automatically created segmentation masks.
A Patient-Centric Dataset of Images and Metadata for Identifying Melanomas Using Clinical Context
Aug 07, 2020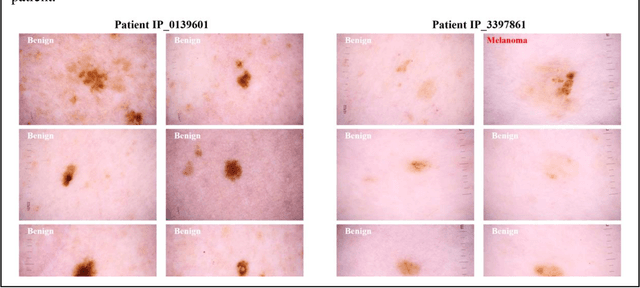
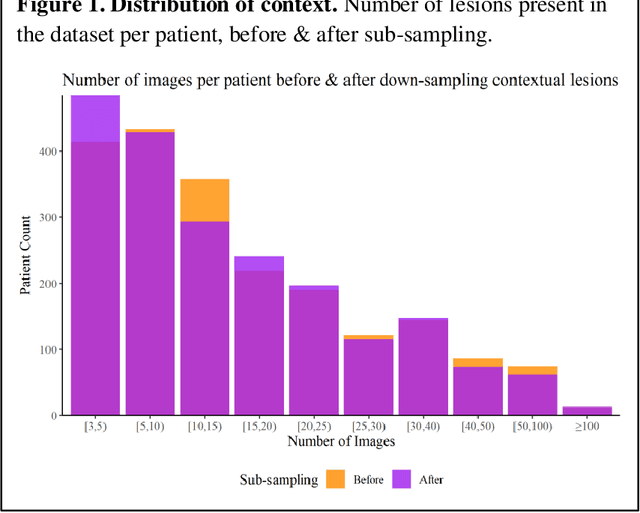
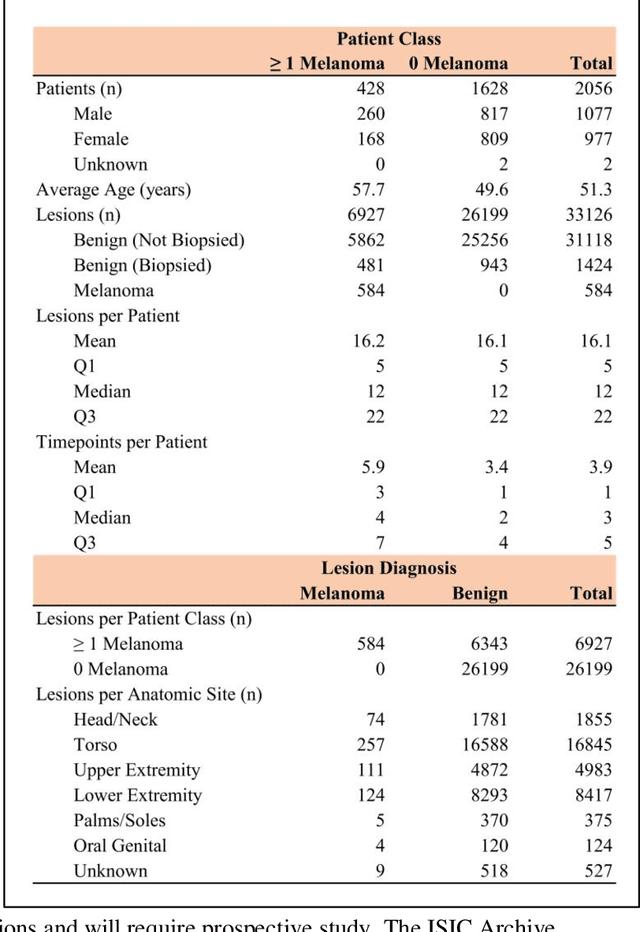
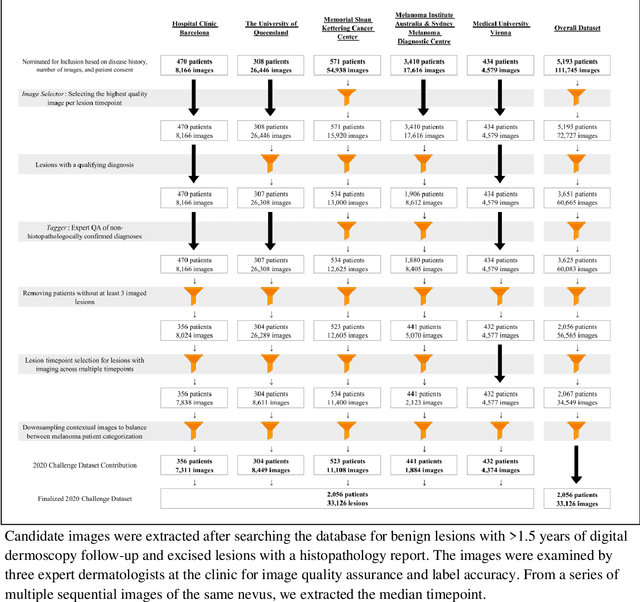
Prior skin image datasets have not addressed patient-level information obtained from multiple skin lesions from the same patient. Though artificial intelligence classification algorithms have achieved expert-level performance in controlled studies examining single images, in practice dermatologists base their judgment holistically from multiple lesions on the same patient. The 2020 SIIM-ISIC Melanoma Classification challenge dataset described herein was constructed to address this discrepancy between prior challenges and clinical practice, providing for each image in the dataset an identifier allowing lesions from the same patient to be mapped to one another. This patient-level contextual information is frequently used by clinicians to diagnose melanoma and is especially useful in ruling out false positives in patients with many atypical nevi. The dataset represents 2,056 patients from three continents with an average of 16 lesions per patient, consisting of 33,126 dermoscopic images and 584 histopathologically confirmed melanomas compared with benign melanoma mimickers.
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Dec 02, 2019

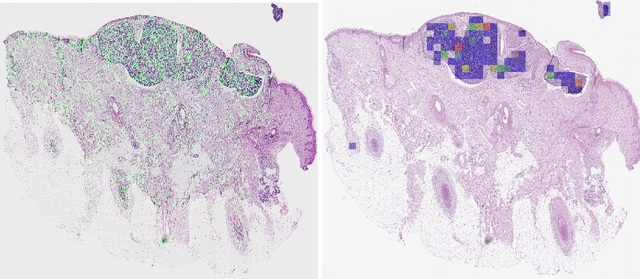
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.99.