 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
CleanPatrick: A Benchmark for Image Data Cleaning
May 16, 2025Robust machine learning depends on clean data, yet current image data cleaning benchmarks rely on synthetic noise or narrow human studies, limiting comparison and real-world relevance. We introduce CleanPatrick, the first large-scale benchmark for data cleaning in the image domain, built upon the publicly available Fitzpatrick17k dermatology dataset. We collect 496,377 binary annotations from 933 medical crowd workers, identify off-topic samples (4%), near-duplicates (21%), and label errors (22%), and employ an aggregation model inspired by item-response theory followed by expert review to derive high-quality ground truth. CleanPatrick formalizes issue detection as a ranking task and adopts typical ranking metrics mirroring real audit workflows. Benchmarking classical anomaly detectors, perceptual hashing, SSIM, Confident Learning, NoiseRank, and SelfClean, we find that, on CleanPatrick, self-supervised representations excel at near-duplicate detection, classical methods achieve competitive off-topic detection under constrained review budgets, and label-error detection remains an open challenge for fine-grained medical classification. By releasing both the dataset and the evaluation framework, CleanPatrick enables a systematic comparison of image-cleaning strategies and paves the way for more reliable data-centric artificial intelligence.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022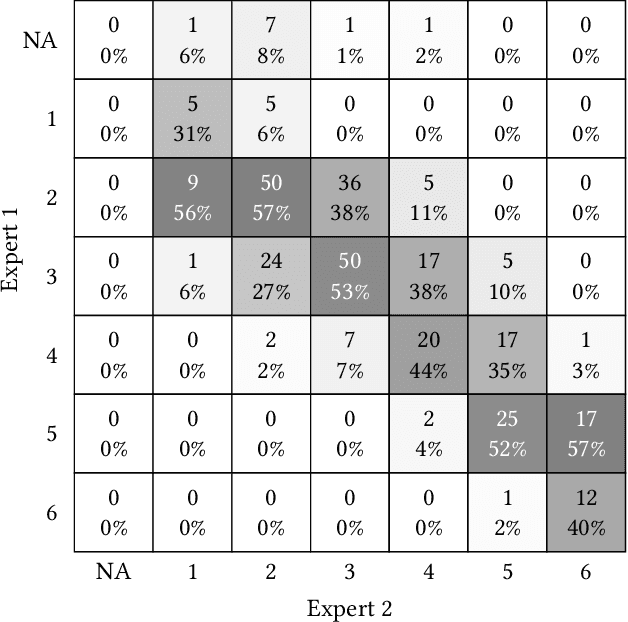
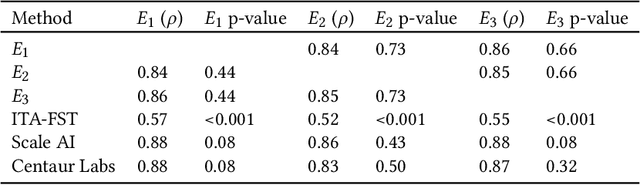
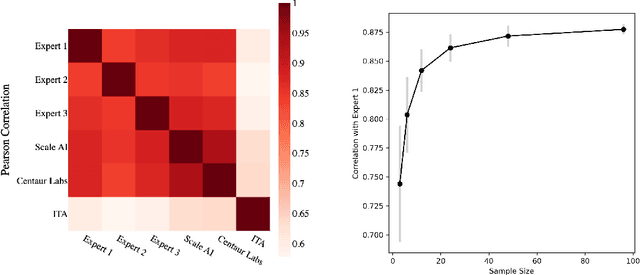
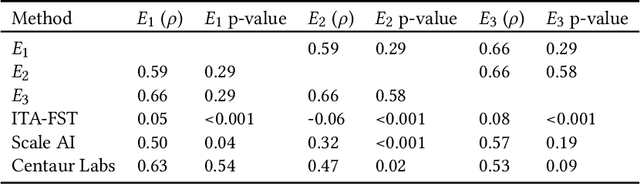
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Evaluating Deep Neural Networks Trained on Clinical Images in Dermatology with the Fitzpatrick 17k Dataset
Apr 20, 2021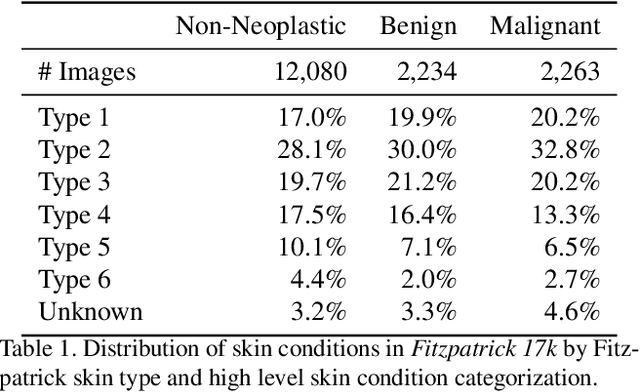
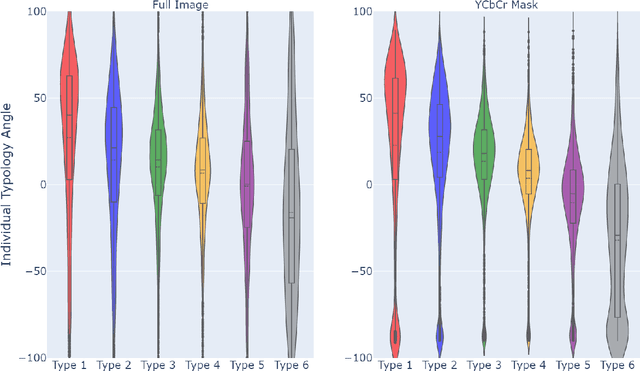

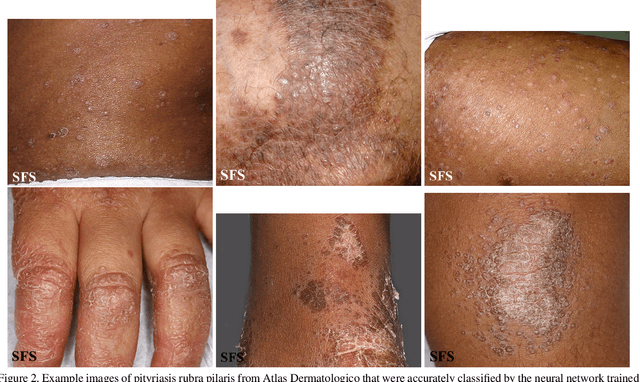
How does the accuracy of deep neural network models trained to classify clinical images of skin conditions vary across skin color? While recent studies demonstrate computer vision models can serve as a useful decision support tool in healthcare and provide dermatologist-level classification on a number of specific tasks, darker skin is underrepresented in the data. Most publicly available data sets do not include Fitzpatrick skin type labels. We annotate 16,577 clinical images sourced from two dermatology atlases with Fitzpatrick skin type labels and open-source these annotations. Based on these labels, we find that there are significantly more images of light skin types than dark skin types in this dataset. We train a deep neural network model to classify 114 skin conditions and find that the model is most accurate on skin types similar to those it was trained on. In addition, we evaluate how an algorithmic approach to identifying skin tones, individual typology angle, compares with Fitzpatrick skin type labels annotated by a team of human labelers.