 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorruptible Neural Networks: Training Models that can Generalize to Large Internal Perturbations
Feb 07, 2026Flat regions of the neural network loss landscape have long been hypothesized to correlate with better generalization properties. A closely related but distinct problem is training models that are robust to internal perturbations to their weights, which may be an important need for future low-power hardware platforms. In this paper, we explore the usage of two methods, sharpness-aware minimization (SAM) and random-weight perturbation (RWP), to find minima robust to a variety of random corruptions to weights. We consider the problem from two angles: generalization (how do we reduce the noise-robust generalization gap) and optimization (how do we maximize performance from optimizers when subject to strong perturbations). First, we establish, both theoretically and empirically, that an over-regularized RWP training objective is optimal for noise-robust generalization. For small-magnitude noise, we find that SAM's adversarial objective further improves performance over any RWP configuration, but performs poorly for large-magnitude noise. We link the cause of this to a vanishing-gradient effect, caused by unevenness in the loss landscape, affecting both SAM and RWP. Lastly, we demonstrate that dynamically adjusting the perturbation strength to match the evolution of the loss landscape improves optimizing for these perturbed objectives.
TrajSSL: Trajectory-Enhanced Semi-Supervised 3D Object Detection
Sep 17, 2024



Semi-supervised 3D object detection is a common strategy employed to circumvent the challenge of manually labeling large-scale autonomous driving perception datasets. Pseudo-labeling approaches to semi-supervised learning adopt a teacher-student framework in which machine-generated pseudo-labels on a large unlabeled dataset are used in combination with a small manually-labeled dataset for training. In this work, we address the problem of improving pseudo-label quality through leveraging long-term temporal information captured in driving scenes. More specifically, we leverage pre-trained motion-forecasting models to generate object trajectories on pseudo-labeled data to further enhance the student model training. Our approach improves pseudo-label quality in two distinct manners: first, we suppress false positive pseudo-labels through establishing consistency across multiple frames of motion forecasting outputs. Second, we compensate for false negative detections by directly inserting predicted object tracks into the pseudo-labeled scene. Experiments on the nuScenes dataset demonstrate the effectiveness of our approach, improving the performance of standard semi-supervised approaches in a variety of settings.
Doubly Robust Self-Training
Jun 01, 2023



Self-training is an important technique for solving semi-supervised learning problems. It leverages unlabeled data by generating pseudo-labels and combining them with a limited labeled dataset for training. The effectiveness of self-training heavily relies on the accuracy of these pseudo-labels. In this paper, we introduce doubly robust self-training, a novel semi-supervised algorithm that provably balances between two extremes. When the pseudo-labels are entirely incorrect, our method reduces to a training process solely using labeled data. Conversely, when the pseudo-labels are completely accurate, our method transforms into a training process utilizing all pseudo-labeled data and labeled data, thus increasing the effective sample size. Through empirical evaluations on both the ImageNet dataset for image classification and the nuScenes autonomous driving dataset for 3D object detection, we demonstrate the superiority of the doubly robust loss over the standard self-training baseline.
Center Feature Fusion: Selective Multi-Sensor Fusion of Center-based Objects
Sep 26, 2022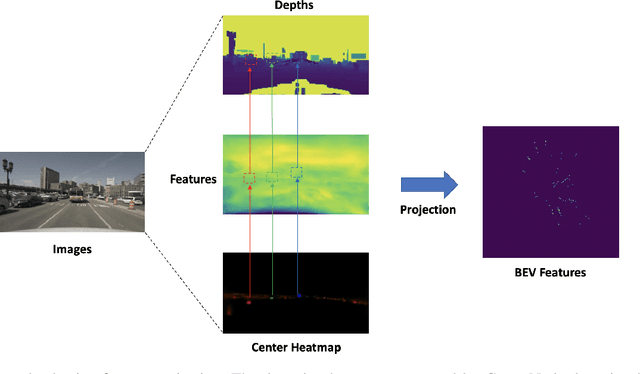
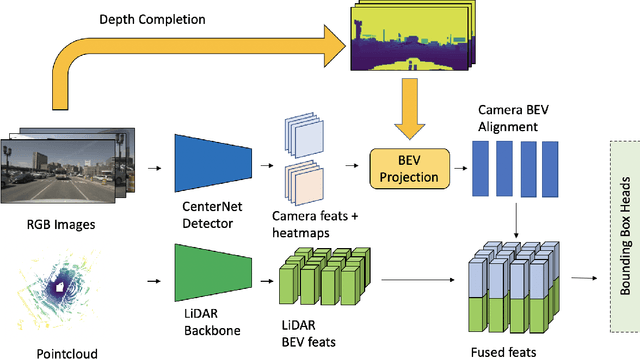

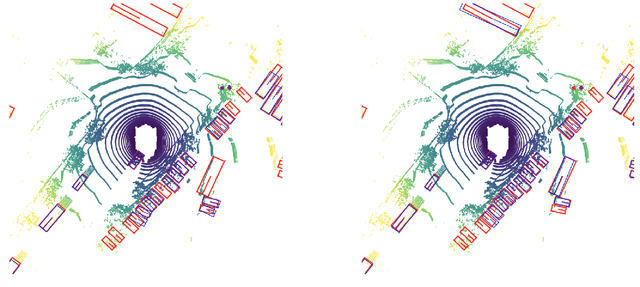
Leveraging multi-modal fusion, especially between camera and LiDAR, has become essential for building accurate and robust 3D object detection systems for autonomous vehicles. Until recently, point decorating approaches, in which point clouds are augmented with camera features, have been the dominant approach in the field. However, these approaches fail to utilize the higher resolution images from cameras. Recent works projecting camera features to the bird's-eye-view (BEV) space for fusion have also been proposed, however they require projecting millions of pixels, most of which only contain background information. In this work, we propose a novel approach Center Feature Fusion (CFF), in which we leverage center-based detection networks in both the camera and LiDAR streams to identify relevant object locations. We then use the center-based detection to identify the locations of pixel features relevant to object locations, a small fraction of the total number in the image. These are then projected and fused in the BEV frame. On the nuScenes dataset, we outperform the LiDAR-only baseline by 4.9% mAP while fusing up to 100x fewer features than other fusion methods.