 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Mar 10, 2018

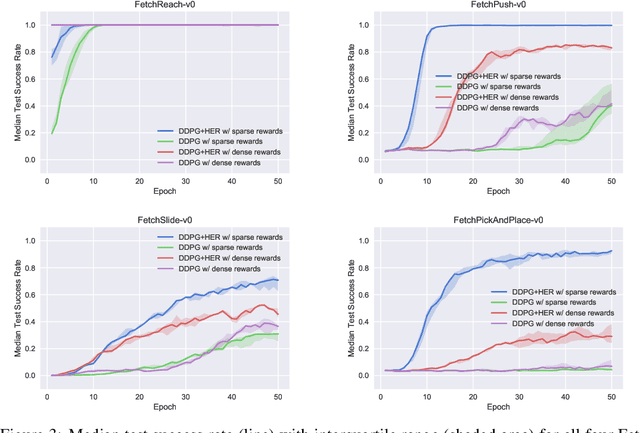
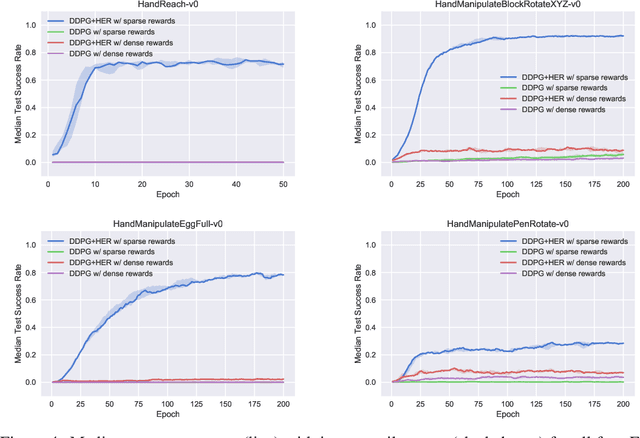
The purpose of this technical report is two-fold. First of all, it introduces a suite of challenging continuous control tasks (integrated with OpenAI Gym) based on currently existing robotics hardware. The tasks include pushing, sliding and pick & place with a Fetch robotic arm as well as in-hand object manipulation with a Shadow Dexterous Hand. All tasks have sparse binary rewards and follow a Multi-Goal Reinforcement Learning (RL) framework in which an agent is told what to do using an additional input. The second part of the paper presents a set of concrete research ideas for improving RL algorithms, most of which are related to Multi-Goal RL and Hindsight Experience Replay.
Hindsight Experience Replay
Feb 23, 2018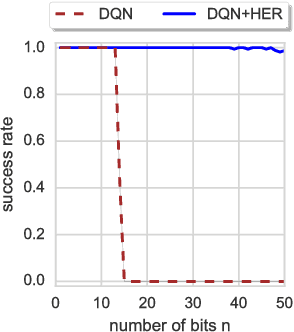
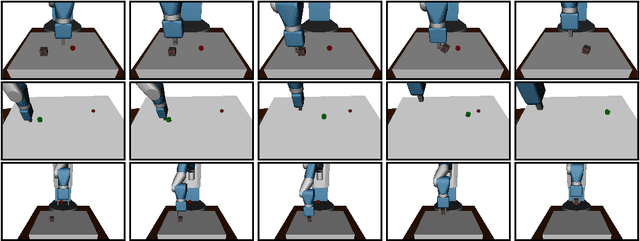
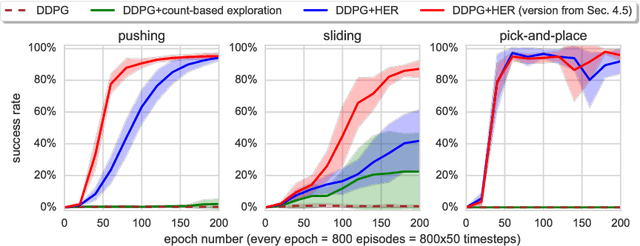
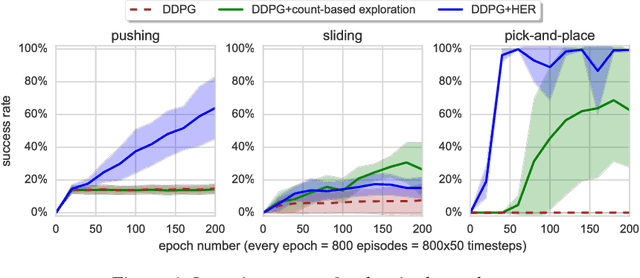
Dealing with sparse rewards is one of the biggest challenges in Reinforcement Learning (RL). We present a novel technique called Hindsight Experience Replay which allows sample-efficient learning from rewards which are sparse and binary and therefore avoid the need for complicated reward engineering. It can be combined with an arbitrary off-policy RL algorithm and may be seen as a form of implicit curriculum. We demonstrate our approach on the task of manipulating objects with a robotic arm. In particular, we run experiments on three different tasks: pushing, sliding, and pick-and-place, in each case using only binary rewards indicating whether or not the task is completed. Our ablation studies show that Hindsight Experience Replay is a crucial ingredient which makes training possible in these challenging environments. We show that our policies trained on a physics simulation can be deployed on a physical robot and successfully complete the task.
Asymmetric Actor Critic for Image-Based Robot Learning
Oct 18, 2017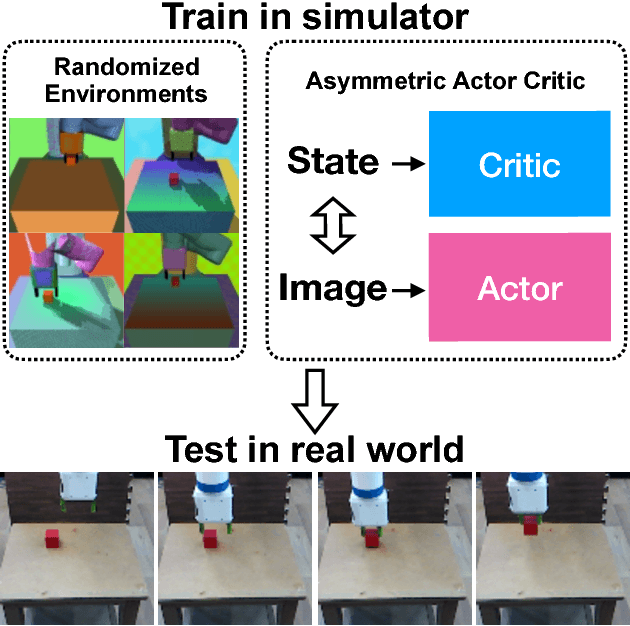
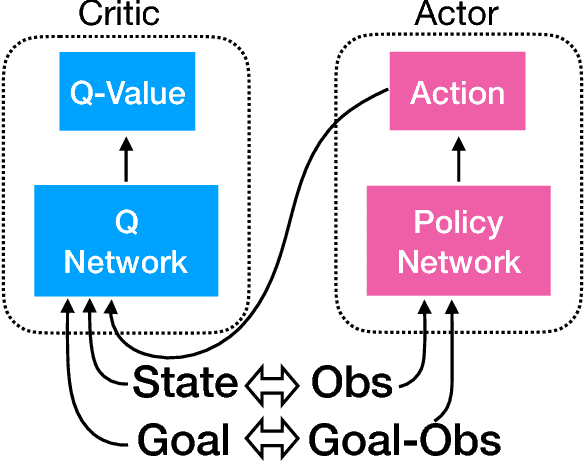


Deep reinforcement learning (RL) has proven a powerful technique in many sequential decision making domains. However, Robotics poses many challenges for RL, most notably training on a physical system can be expensive and dangerous, which has sparked significant interest in learning control policies using a physics simulator. While several recent works have shown promising results in transferring policies trained in simulation to the real world, they often do not fully utilize the advantage of working with a simulator. In this work, we exploit the full state observability in the simulator to train better policies which take as input only partial observations (RGBD images). We do this by employing an actor-critic training algorithm in which the critic is trained on full states while the actor (or policy) gets rendered images as input. We show experimentally on a range of simulated tasks that using these asymmetric inputs significantly improves performance. Finally, we combine this method with domain randomization and show real robot experiments for several tasks like picking, pushing, and moving a block. We achieve this simulation to real world transfer without training on any real world data.
Semisupervised Classifier Evaluation and Recalibration
Oct 08, 2012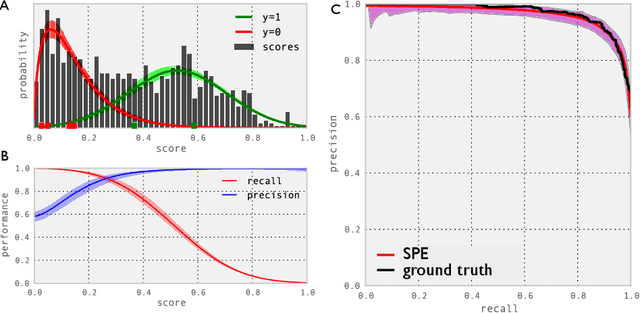
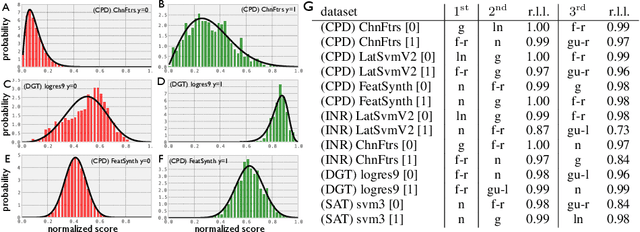
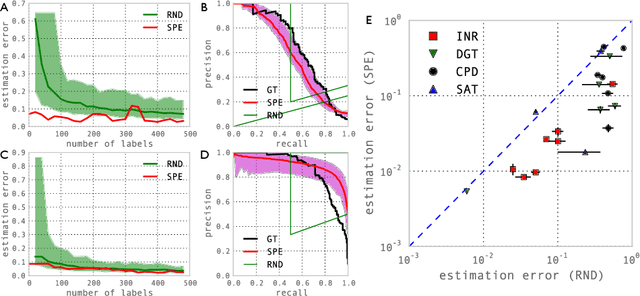
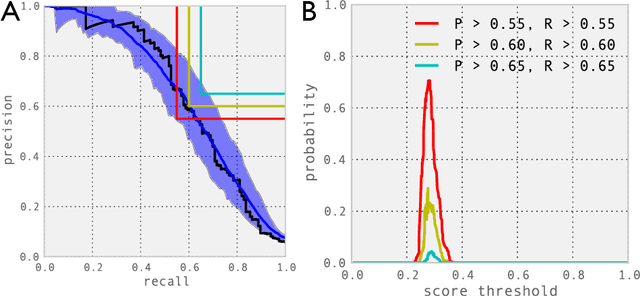
How many labeled examples are needed to estimate a classifier's performance on a new dataset? We study the case where data is plentiful, but labels are expensive. We show that by making a few reasonable assumptions on the structure of the data, it is possible to estimate performance curves, with confidence bounds, using a small number of ground truth labels. Our approach, which we call Semisupervised Performance Evaluation (SPE), is based on a generative model for the classifier's confidence scores. In addition to estimating the performance of classifiers on new datasets, SPE can be used to recalibrate a classifier by re-estimating the class-conditional confidence distributions.