 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Renyi Differential Privacy of the Shuffle Model
May 11, 2021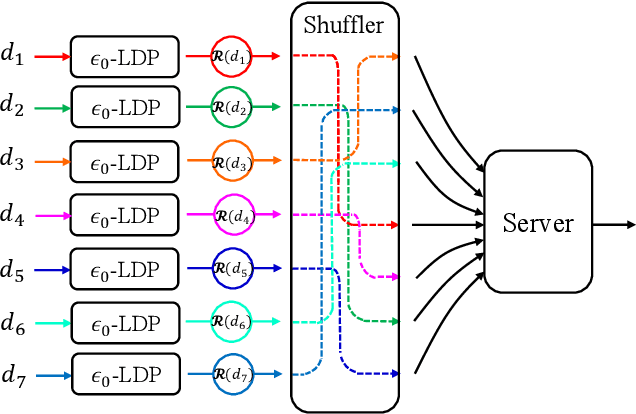
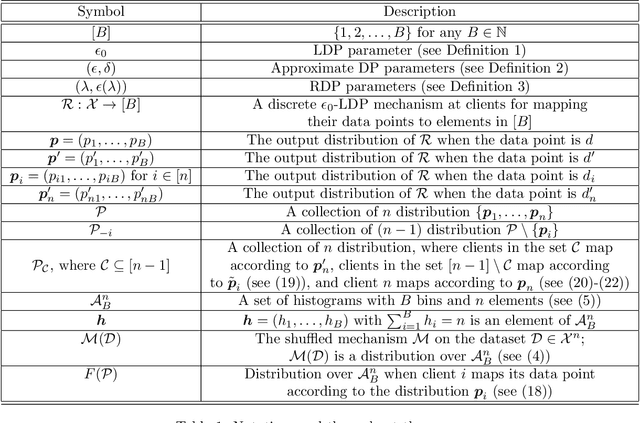
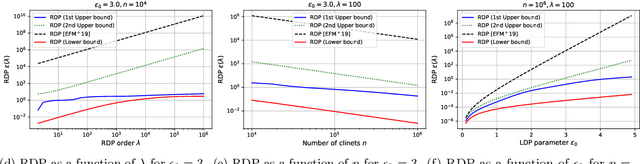
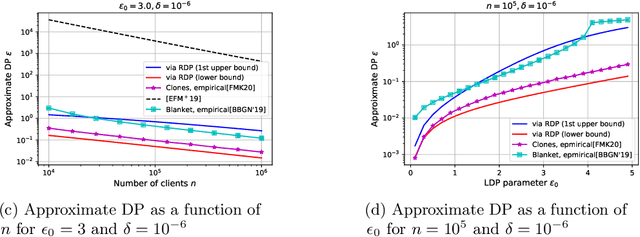
The central question studied in this paper is Renyi Differential Privacy (RDP) guarantees for general discrete local mechanisms in the shuffle privacy model. In the shuffle model, each of the $n$ clients randomizes its response using a local differentially private (LDP) mechanism and the untrusted server only receives a random permutation (shuffle) of the client responses without association to each client. The principal result in this paper is the first non-trivial RDP guarantee for general discrete local randomization mechanisms in the shuffled privacy model, and we develop new analysis techniques for deriving our results which could be of independent interest. In applications, such an RDP guarantee is most useful when we use it for composing several private interactions. We numerically demonstrate that, for important regimes, with composition our bound yields an improvement in privacy guarantee by a factor of $8\times$ over the state-of-the-art approximate Differential Privacy (DP) guarantee (with standard composition) for shuffled models. Moreover, combining with Poisson subsampling, our result leads to at least $10\times$ improvement over subsampled approximate DP with standard composition.
Practical and Private (Deep) Learning without Sampling or Shuffling
Feb 26, 2021
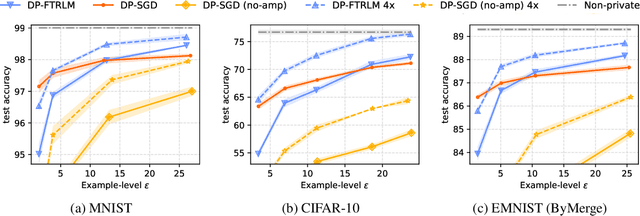
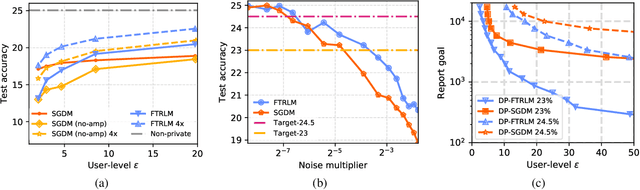
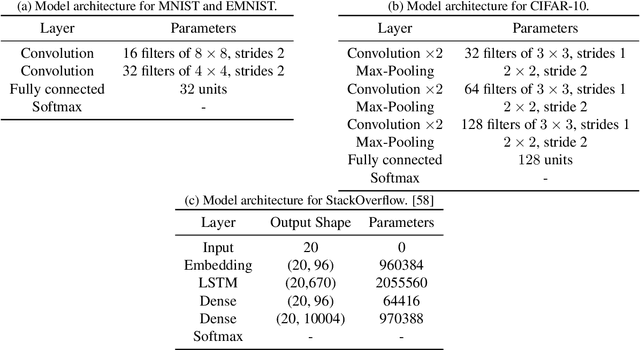
We consider training models with differential privacy (DP) using mini-batch gradients. The existing state-of-the-art, Differentially Private Stochastic Gradient Descent (DP-SGD), requires privacy amplification by sampling or shuffling to obtain the best privacy/accuracy/computation trade-offs. Unfortunately, the precise requirements on exact sampling and shuffling can be hard to obtain in important practical scenarios, particularly federated learning (FL). We design and analyze a DP variant of Follow-The-Regularized-Leader (DP-FTRL) that compares favorably (both theoretically and empirically) to amplified DP-SGD, while allowing for much more flexible data access patterns. DP-FTRL does not use any form of privacy amplification.
The Distributed Discrete Gaussian Mechanism for Federated Learning with Secure Aggregation
Feb 12, 2021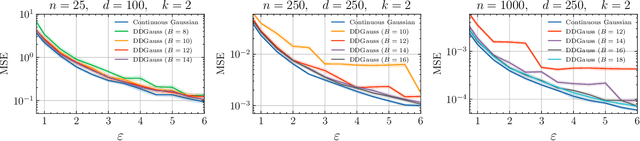
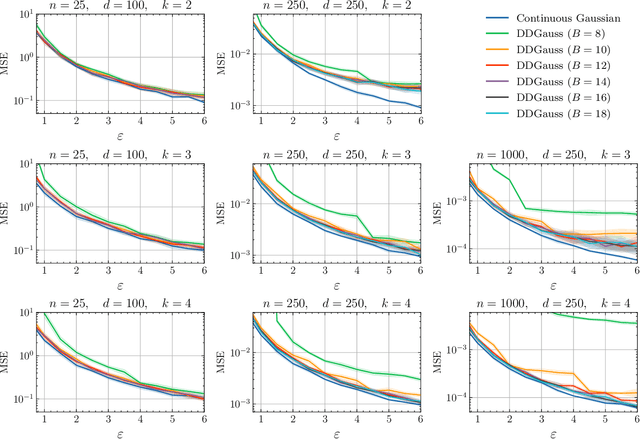
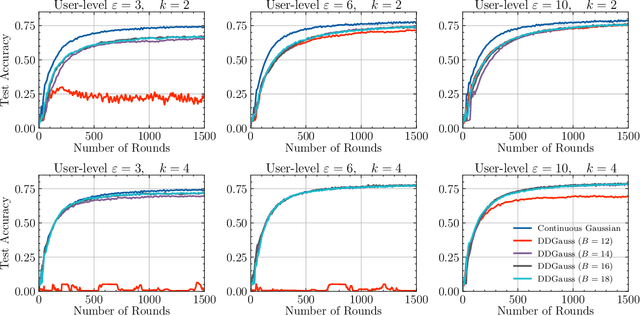
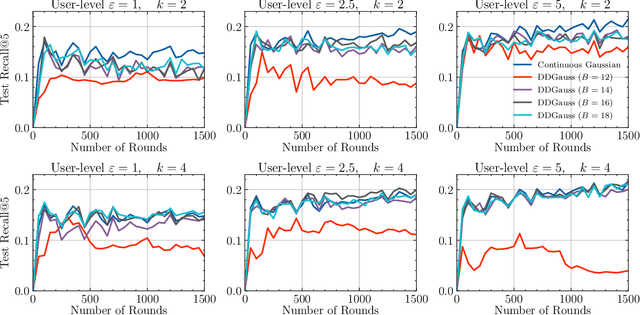
We consider training models on private data that is distributed across user devices. To ensure privacy, we add on-device noise and use secure aggregation so that only the noisy sum is revealed to the server. We present a comprehensive end-to-end system, which appropriately discretizes the data and adds discrete Gaussian noise before performing secure aggregation. We provide a novel privacy analysis for sums of discrete Gaussians. We also analyze the effect of rounding the input data and the modular summation arithmetic. Our theoretical guarantees highlight the complex tension between communication, privacy, and accuracy. Our extensive experimental results demonstrate that our solution is essentially able to achieve a comparable accuracy to central differential privacy with 16 bits of precision per value.
Shuffled Model of Federated Learning: Privacy, Communication and Accuracy Trade-offs
Aug 17, 2020
We consider a distributed empirical risk minimization (ERM) optimization problem with communication efficiency and privacy requirements, motivated by the federated learning (FL) framework. Unique challenges to the traditional ERM problem in the context of FL include (i) need to provide privacy guarantees on clients' data, (ii) compress the communication between clients and the server, since clients might have low-bandwidth links, (iii) work with a dynamic client population at each round of communication between the server and the clients, as a small fraction of clients are sampled at each round. To address these challenges we develop (optimal) communication-efficient schemes for private mean estimation for several $\ell_p$ spaces, enabling efficient gradient aggregation for each iteration of the optimization solution of the ERM. We also provide lower and upper bounds for mean estimation with privacy and communication constraints for arbitrary $\ell_p$ spaces. To get the overall communication, privacy, and optimization performance operation point, we combine this with privacy amplification opportunities inherent to this setup. Our solution takes advantage of the inherent privacy amplification provided by client sampling and data sampling at each client (through Stochastic Gradient Descent) as well as the recently developed privacy framework using anonymization, which effectively presents to the server responses that are randomly shuffled with respect to the clients. Putting these together, we demonstrate that one can get the same privacy, optimization-performance operating point developed in recent methods that use full-precision communication, but at a much lower communication cost, i.e., effectively getting communication efficiency for "free".
Dimension Independence in Unconstrained Private ERM via Adaptive Preconditioning
Aug 14, 2020
In this paper we revisit the problem of private empirical risk minimziation (ERM) with differential privacy. We show that for unconstrained convex empirical risk minimization if the observed gradients of the objective function along the path of private gradient descent lie in a low-dimensional subspace (smaller than the ambient dimensionality of $p$), then using noisy adaptive preconditioning (a.k.a., noisy Adaptive Gradient Descent (AdaGrad)) we obtain a regret composed of two terms: a constant multiplicative factor of the original AdaGrad regret and an additional regret due to noise. In particular, we show that if the gradients lie in a constant rank subspace, then one can achieve an excess empirical risk of $ \tilde{O}(1/\epsilon n)$, compared to the worst-case achievable bound of $\tilde{O}(\sqrt{p}/\epsilon n)$. While previous works show dimension independent excess empirical risk bounds for the restrictive setting of convex generalized linear problems optimized over unconstrained subspaces, our results operate with general convex functions in unconstrained minimization. Along the way, we do a perturbation analysis of noisy AdaGrad, which may be of independent interest.
Privacy Amplification via Random Check-Ins
Jul 30, 2020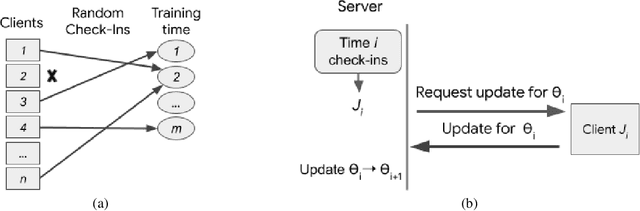

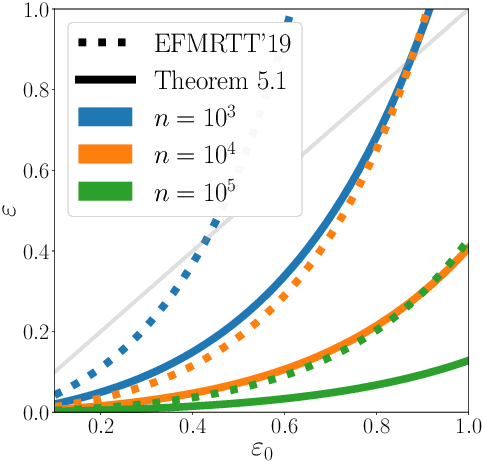
Differentially Private Stochastic Gradient Descent (DP-SGD) forms a fundamental building block in many applications for learning over sensitive data. Two standard approaches, privacy amplification by subsampling, and privacy amplification by shuffling, permit adding lower noise in DP-SGD than via na\"{\i}ve schemes. A key assumption in both these approaches is that the elements in the data set can be uniformly sampled, or be uniformly permuted -- constraints that may become prohibitive when the data is processed in a decentralized or distributed fashion. In this paper, we focus on conducting iterative methods like DP-SGD in the setting of federated learning (FL) wherein the data is distributed among many devices (clients). Our main contribution is the \emph{random check-in} distributed protocol, which crucially relies only on randomized participation decisions made locally and independently by each client. It has privacy/accuracy trade-offs similar to privacy amplification by subsampling/shuffling. However, our method does not require server-initiated communication, or even knowledge of the population size. To our knowledge, this is the first privacy amplification tailored for a distributed learning framework, and it may have broader applicability beyond FL. Along the way, we extend privacy amplification by shuffling to incorporate $(\epsilon,\delta)$-DP local randomizers, and exponentially improve its guarantees. In practical regimes, this improvement allows for similar privacy and utility using data from an order of magnitude fewer users.
Breaking the Communication-Privacy-Accuracy Trilemma
Jul 22, 2020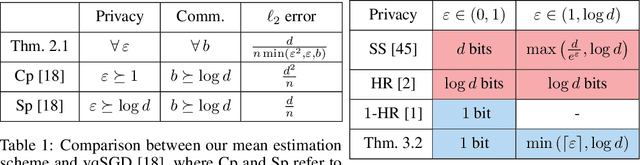
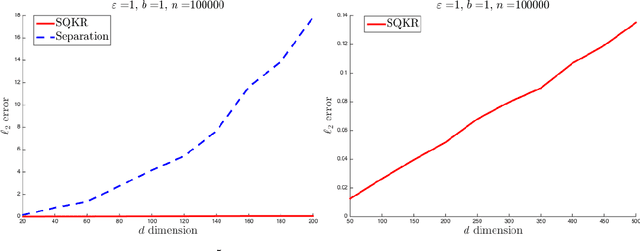
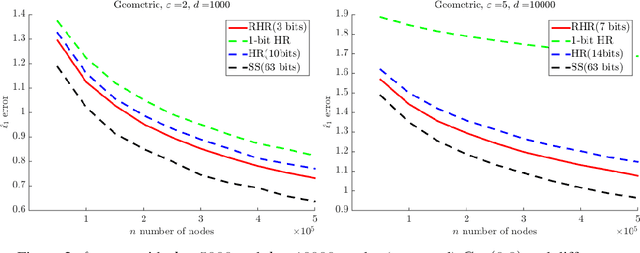

Two major challenges in distributed learning and estimation are 1) preserving the privacy of the local samples; and 2) communicating them efficiently to a central server, while achieving high accuracy for the end-to-end task. While there has been significant interest in addressing each of these challenges separately in the recent literature, treatments that simultaneously address both challenges are still largely missing. In this paper, we develop novel encoding and decoding mechanisms that simultaneously achieve optimal privacy and communication efficiency in various canonical settings. In particular, we consider the problems of mean estimation and frequency estimation under $\varepsilon$-local differential privacy and $b$-bit communication constraints. For mean estimation, we propose a scheme based on Kashin's representation and random sampling, with order-optimal estimation error under both constraints. For frequency estimation, we present a mechanism that leverages the recursive structure of Walsh-Hadamard matrices and achieves order-optimal estimation error for all privacy levels and communication budgets. As a by-product, we also construct a distribution estimation mechanism that is rate-optimal for all privacy regimes and communication constraints, extending recent work that is limited to $b=1$ and $\varepsilon=O(1)$. Our results demonstrate that intelligent encoding under joint privacy and communication constraints can yield a performance that matches the optimal accuracy achievable under either constraint alone.
DP-CGAN: Differentially Private Synthetic Data and Label Generation
Jan 27, 2020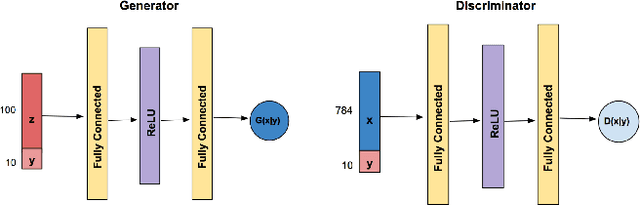

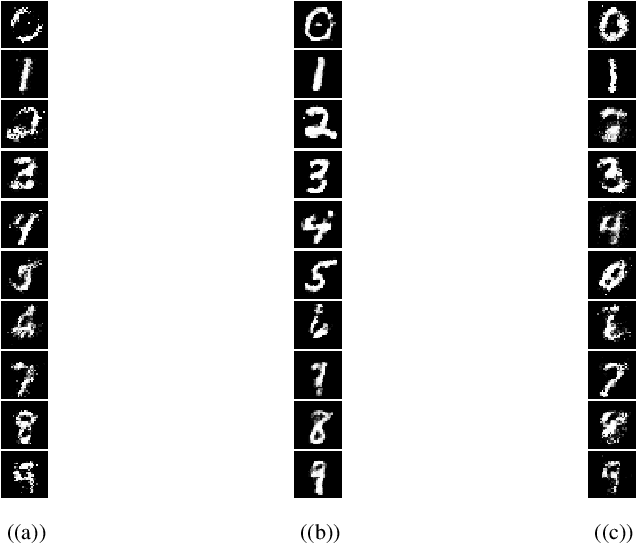
Generative Adversarial Networks (GANs) are one of the well-known models to generate synthetic data including images, especially for research communities that cannot use original sensitive datasets because they are not publicly accessible. One of the main challenges in this area is to preserve the privacy of individuals who participate in the training of the GAN models. To address this challenge, we introduce a Differentially Private Conditional GAN (DP-CGAN) training framework based on a new clipping and perturbation strategy, which improves the performance of the model while preserving privacy of the training dataset. DP-CGAN generates both synthetic data and corresponding labels and leverages the recently introduced Renyi differential privacy accountant to track the spent privacy budget. The experimental results show that DP-CGAN can generate visually and empirically promising results on the MNIST dataset with a single-digit epsilon parameter in differential privacy.
Advances and Open Problems in Federated Learning
Dec 10, 2019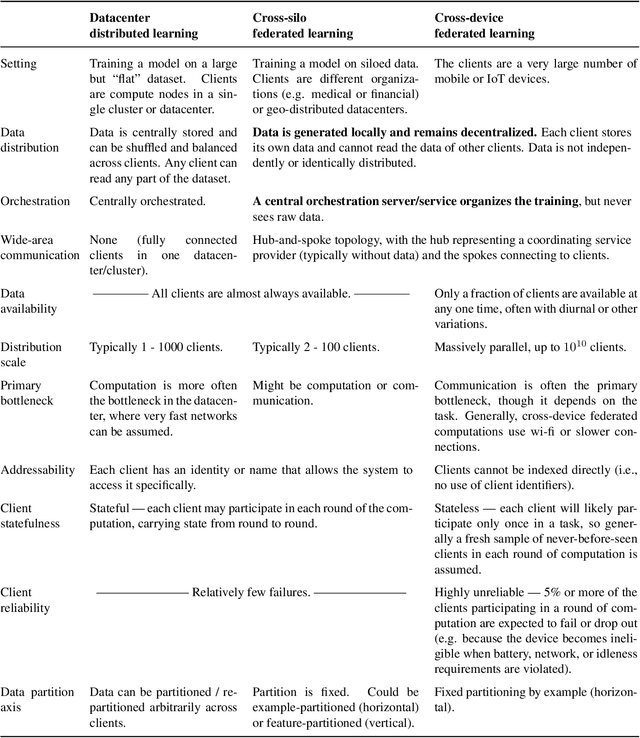
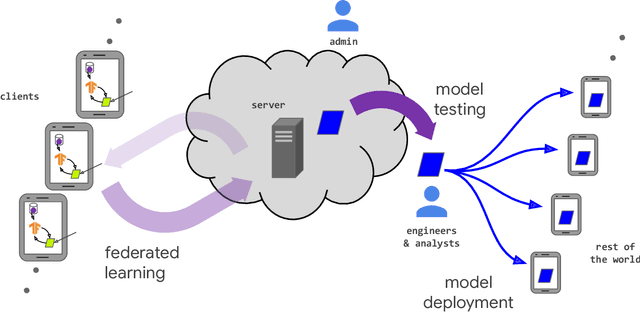
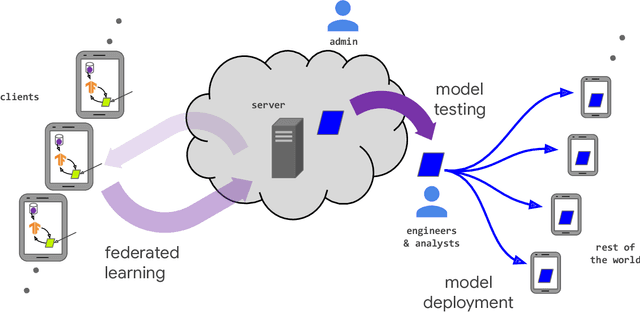

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Can You Really Backdoor Federated Learning?
Dec 02, 2019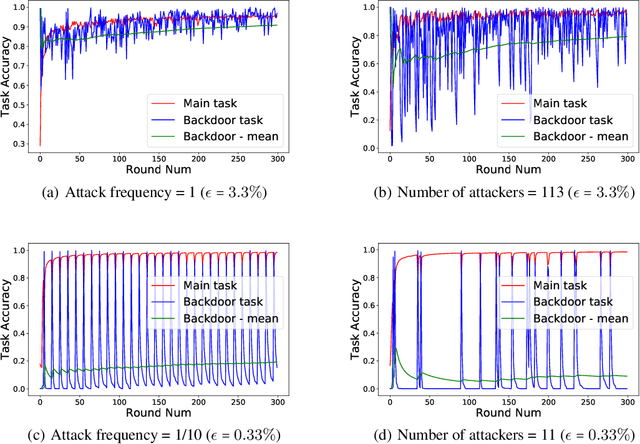
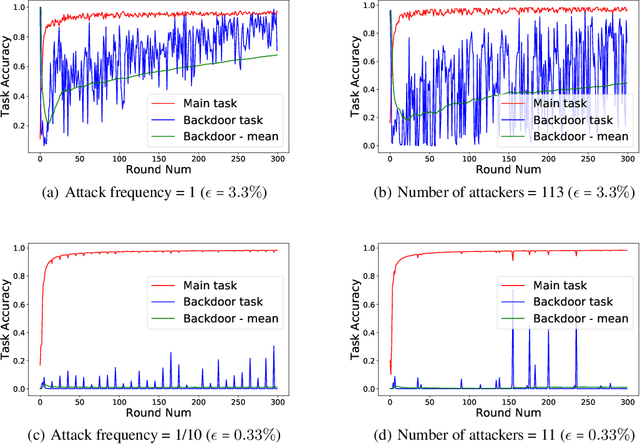
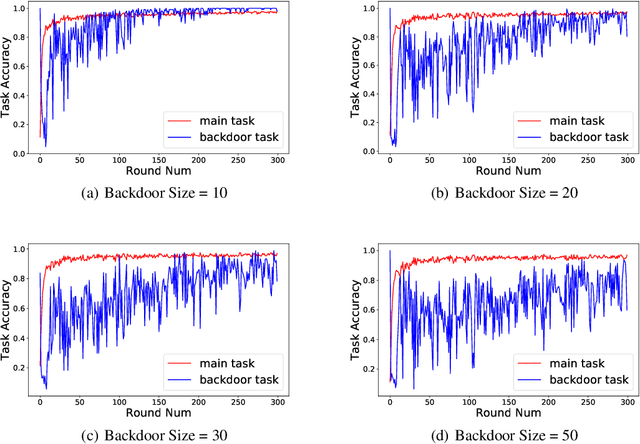
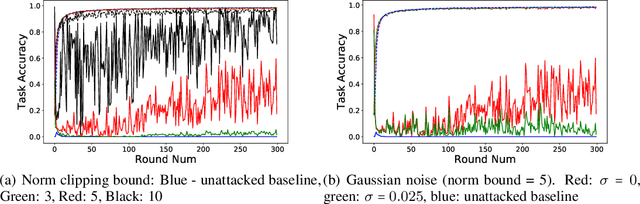
The decentralized nature of federated learning makes detecting and defending against adversarial attacks a challenging task. This paper focuses on backdoor attacks in the federated learning setting, where the goal of the adversary is to reduce the performance of the model on targeted tasks while maintaining good performance on the main task. Unlike existing works, we allow non-malicious clients to have correctly labeled samples from the targeted tasks. We conduct a comprehensive study of backdoor attacks and defenses for the EMNIST dataset, a real-life, user-partitioned, and non-iid dataset. We observe that in the absence of defenses, the performance of the attack largely depends on the fraction of adversaries present and the "complexity'' of the targeted task. Moreover, we show that norm clipping and "weak'' differential privacy mitigate the attacks without hurting the overall performance. We have implemented the attacks and defenses in TensorFlow Federated (TFF), a TensorFlow framework for federated learning. In open-sourcing our code, our goal is to encourage researchers to contribute new attacks and defenses and evaluate them on standard federated datasets.