 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Ingredients of an Effective Zero-shot Semantic Parser
Oct 15, 2021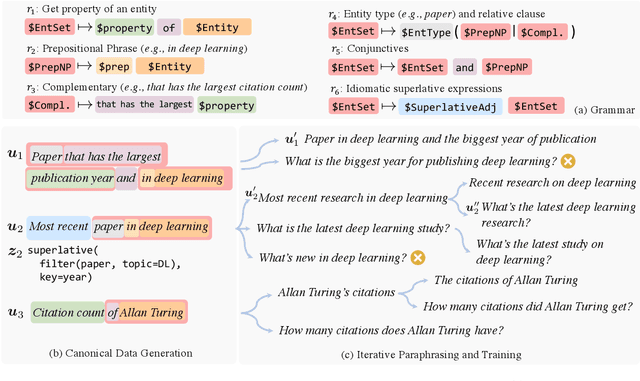
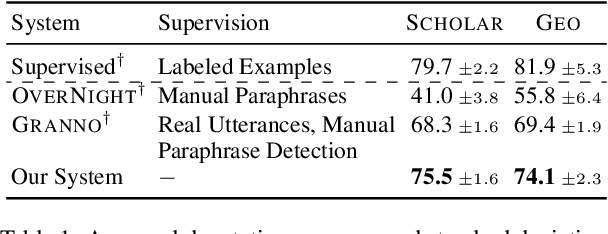
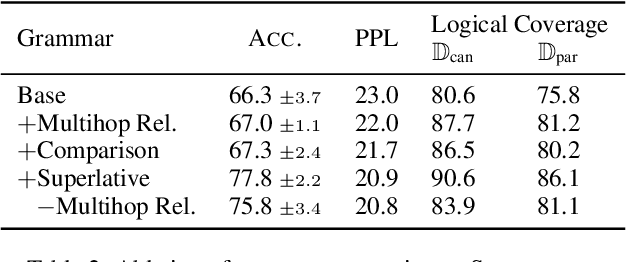

Semantic parsers map natural language utterances into meaning representations (e.g., programs). Such models are typically bottlenecked by the paucity of training data due to the required laborious annotation efforts. Recent studies have performed zero-shot learning by synthesizing training examples of canonical utterances and programs from a grammar, and further paraphrasing these utterances to improve linguistic diversity. However, such synthetic examples cannot fully capture patterns in real data. In this paper we analyze zero-shot parsers through the lenses of the language and logical gaps (Herzig and Berant, 2019), which quantify the discrepancy of language and programmatic patterns between the canonical examples and real-world user-issued ones. We propose bridging these gaps using improved grammars, stronger paraphrasers, and efficient learning methods using canonical examples that most likely reflect real user intents. Our model achieves strong performance on two semantic parsing benchmarks (Scholar, Geo) with zero labeled data.
Learning to Superoptimize Real-world Programs
Sep 28, 2021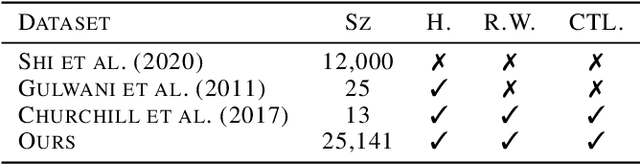
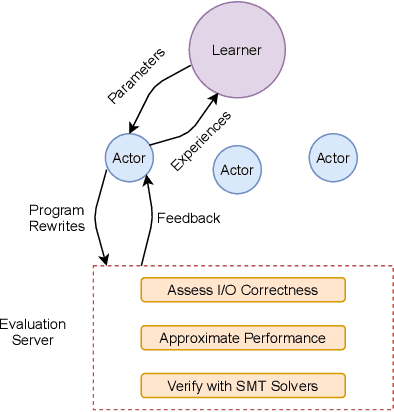

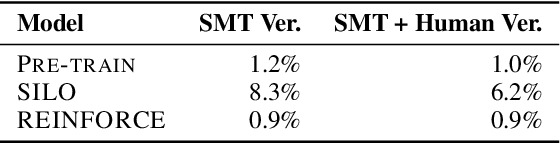
Program optimization is the process of modifying software to execute more efficiently. Because finding the optimal program is generally undecidable, modern compilers usually resort to expert-written heuristic optimizations. In contrast, superoptimizers attempt to find the optimal program by employing significantly more expensive search and constraint solving techniques. Generally, these methods do not scale well to programs in real development scenarios, and as a result superoptimization has largely been confined to small-scale, domain-specific, and/or synthetic program benchmarks. In this paper, we propose a framework to learn to superoptimize real-world programs by using neural sequence-to-sequence models. We introduce the Big Assembly benchmark, a dataset consisting of over 25K real-world functions mined from open-source projects in x86-64 assembly, which enables experimentation on large-scale optimization of real-world programs. We propose an approach, Self Imitation Learning for Optimization (SILO) that is easy to implement and outperforms a standard policy gradient learning approach on our Big Assembly benchmark. Our method, SILO, superoptimizes programs an expected 6.2% of our test set when compared with the gcc version 10.3 compiler's aggressive optimization level -O3. We also report that SILO's rate of superoptimization on our test set is over five times that of a standard policy gradient approach and a model pre-trained on compiler optimization demonstration.
Hierarchical Control of Situated Agents through Natural Language
Sep 16, 2021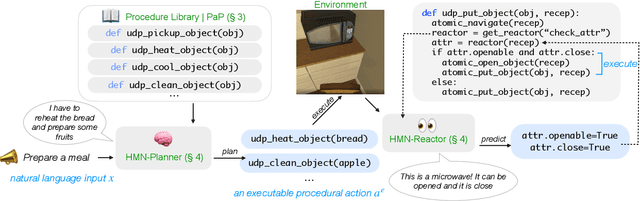


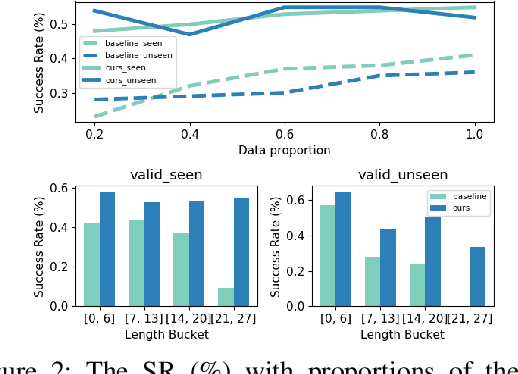
When humans conceive how to perform a particular task, they do so hierarchically: splitting higher-level tasks into smaller sub-tasks. However, in the literature on natural language (NL) command of situated agents, most works have treated the procedures to be executed as flat sequences of simple actions, or any hierarchies of procedures have been shallow at best. In this paper, we propose a formalism of procedures as programs, a powerful yet intuitive method of representing hierarchical procedural knowledge for agent command and control. We further propose a modeling paradigm of hierarchical modular networks, which consist of a planner and reactors that convert NL intents to predictions of executable programs and probe the environment for information necessary to complete the program execution. We instantiate this framework on the IQA and ALFRED datasets for NL instruction following. Our model outperforms reactive baselines by a large margin on both datasets. We also demonstrate that our framework is more data-efficient, and that it allows for fast iterative development.
Learning Structural Edits via Incremental Tree Transformations
Jan 28, 2021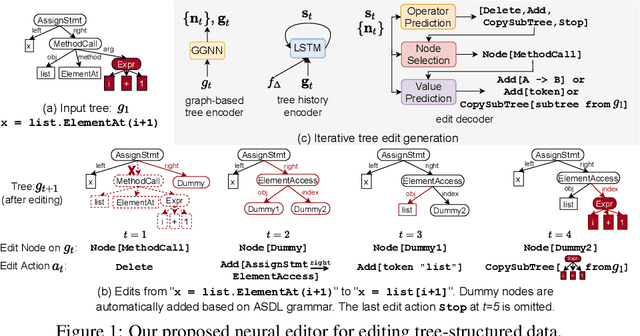


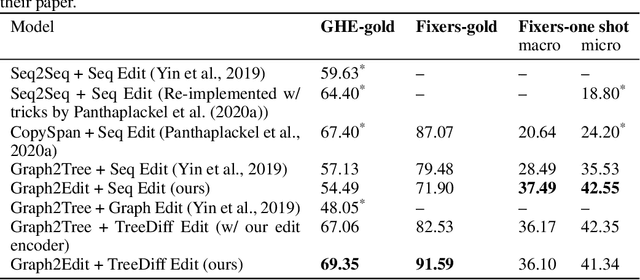
While most neural generative models generate outputs in a single pass, the human creative process is usually one of iterative building and refinement. Recent work has proposed models of editing processes, but these mostly focus on editing sequential data and/or only model a single editing pass. In this paper, we present a generic model for incremental editing of structured data (i.e., "structural edits"). Particularly, we focus on tree-structured data, taking abstract syntax trees of computer programs as our canonical example. Our editor learns to iteratively generate tree edits (e.g., deleting or adding a subtree) and applies them to the partially edited data, thereby the entire editing process can be formulated as consecutive, incremental tree transformations. To show the unique benefits of modeling tree edits directly, we further propose a novel edit encoder for learning to represent edits, as well as an imitation learning method that allows the editor to be more robust. We evaluate our proposed editor on two source code edit datasets, where results show that, with the proposed edit encoder, our editor significantly improves accuracy over previous approaches that generate the edited program directly in one pass. Finally, we demonstrate that training our editor to imitate experts and correct its mistakes dynamically can further improve its performance.
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
May 17, 2020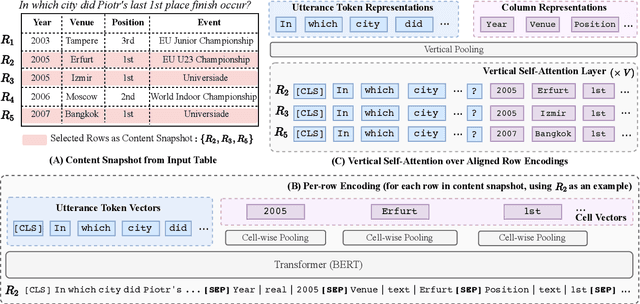
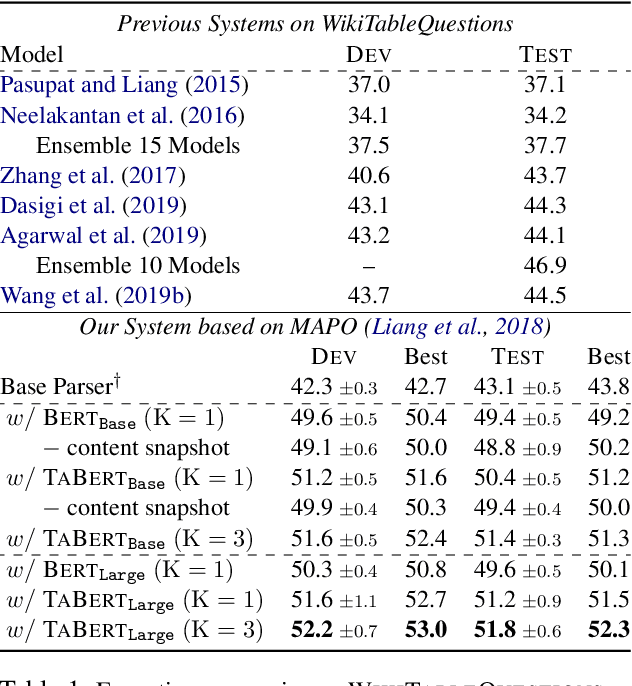
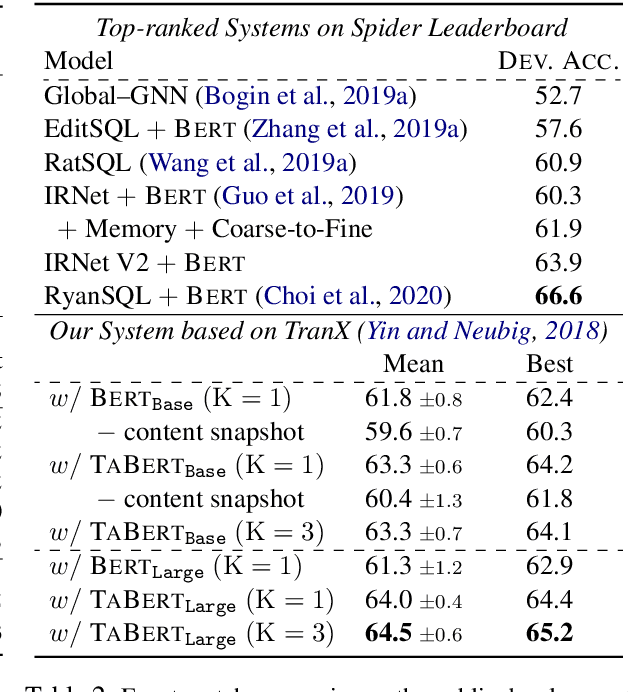
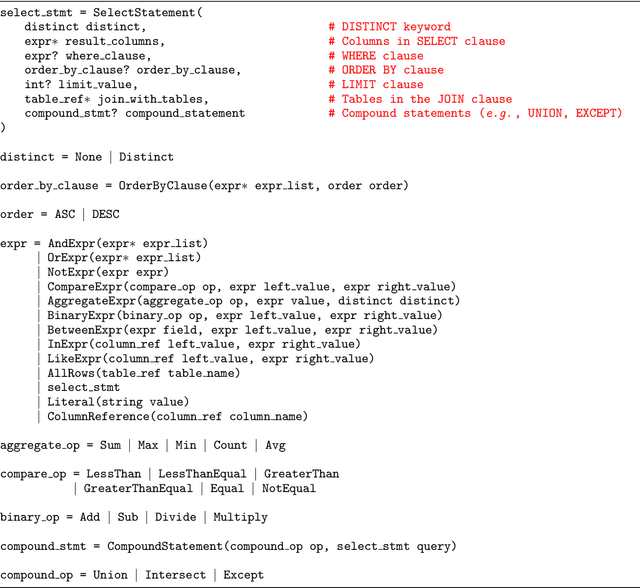
Recent years have witnessed the burgeoning of pretrained language models (LMs) for text-based natural language (NL) understanding tasks. Such models are typically trained on free-form NL text, hence may not be suitable for tasks like semantic parsing over structured data, which require reasoning over both free-form NL questions and structured tabular data (e.g., database tables). In this paper we present TaBERT, a pretrained LM that jointly learns representations for NL sentences and (semi-)structured tables. TaBERT is trained on a large corpus of 26 million tables and their English contexts. In experiments, neural semantic parsers using TaBERT as feature representation layers achieve new best results on the challenging weakly-supervised semantic parsing benchmark WikiTableQuestions, while performing competitively on the text-to-SQL dataset Spider. Implementation of the model will be available at http://fburl.com/TaBERT .
Incorporating External Knowledge through Pre-training for Natural Language to Code Generation
Apr 20, 2020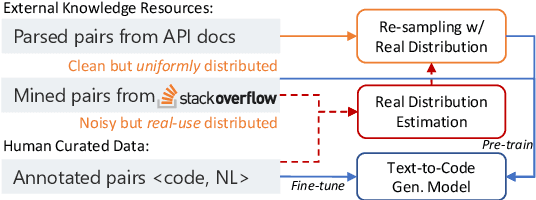
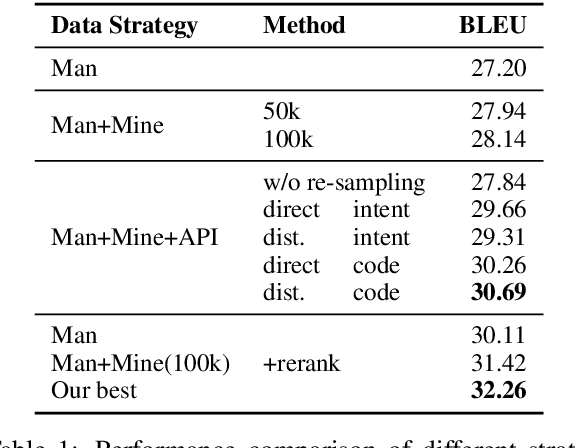


Open-domain code generation aims to generate code in a general-purpose programming language (such as Python) from natural language (NL) intents. Motivated by the intuition that developers usually retrieve resources on the web when writing code, we explore the effectiveness of incorporating two varieties of external knowledge into NL-to-code generation: automatically mined NL-code pairs from the online programming QA forum StackOverflow and programming language API documentation. Our evaluations show that combining the two sources with data augmentation and retrieval-based data re-sampling improves the current state-of-the-art by up to 2.2% absolute BLEU score on the code generation testbed CoNaLa. The code and resources are available at https://github.com/neulab/external-knowledge-codegen.
Merging Weak and Active Supervision for Semantic Parsing
Nov 29, 2019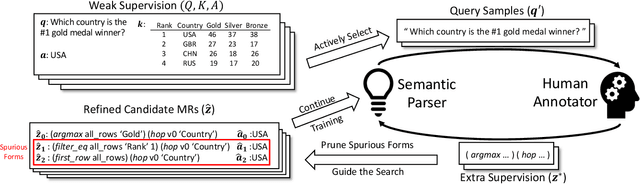

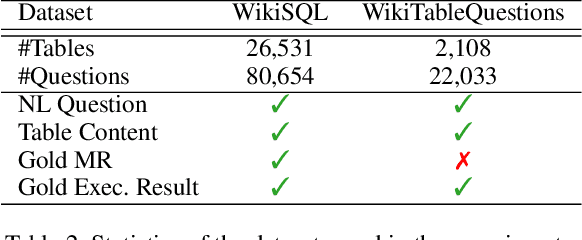
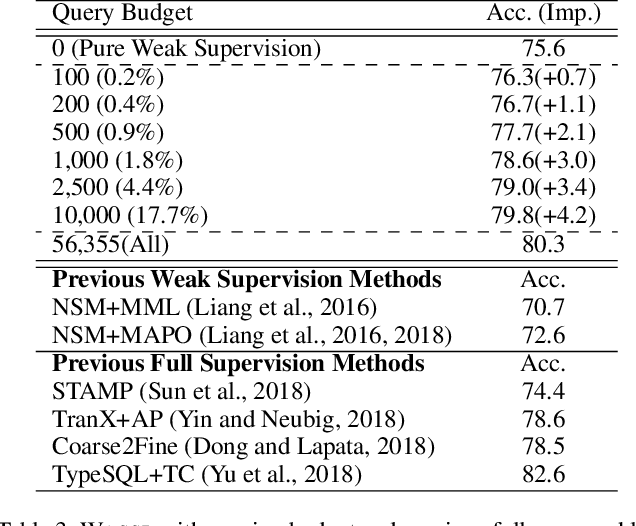
A semantic parser maps natural language commands (NLs) from the users to executable meaning representations (MRs), which are later executed in certain environment to obtain user-desired results. The fully-supervised training of such parser requires NL/MR pairs, annotated by domain experts, which makes them expensive to collect. However, weakly-supervised semantic parsers are learnt only from pairs of NL and expected execution results, leaving the MRs latent. While weak supervision is cheaper to acquire, learning from this input poses difficulties. It demands that parsers search a large space with a very weak learning signal and it is hard to avoid spurious MRs that achieve the correct answer in the wrong way. These factors lead to a performance gap between parsers trained in weakly- and fully-supervised setting. To bridge this gap, we examine the intersection between weak supervision and active learning, which allows the learner to actively select examples and query for manual annotations as extra supervision to improve the model trained under weak supervision. We study different active learning heuristics for selecting examples to query, and various forms of extra supervision for such queries. We evaluate the effectiveness of our method on two different datasets. Experiments on the WikiSQL show that by annotating only 1.8% of examples, we improve over a state-of-the-art weakly-supervised baseline by 6.4%, achieving an accuracy of 79.0%, which is only 1.3% away from the model trained with full supervision. Experiments on WikiTableQuestions with human annotators show that our method can improve the performance with only 100 active queries, especially for weakly-supervised parsers learnt from a cold start.
Improving Open Information Extraction via Iterative Rank-Aware Learning
May 31, 2019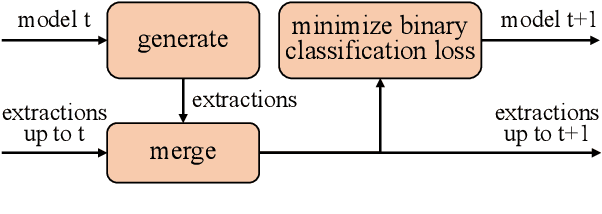


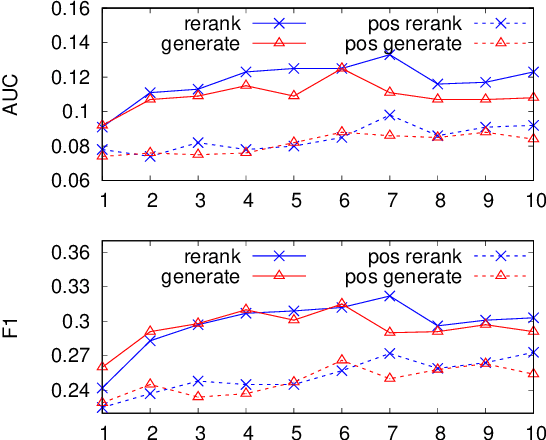
Open information extraction (IE) is the task of extracting open-domain assertions from natural language sentences. A key step in open IE is confidence modeling, ranking the extractions based on their estimated quality to adjust precision and recall of extracted assertions. We found that the extraction likelihood, a confidence measure used by current supervised open IE systems, is not well calibrated when comparing the quality of assertions extracted from different sentences. We propose an additional binary classification loss to calibrate the likelihood to make it more globally comparable, and an iterative learning process, where extractions generated by the open IE model are incrementally included as training samples to help the model learn from trial and error. Experiments on OIE2016 demonstrate the effectiveness of our method. Code and data are available at https://github.com/jzbjyb/oie_rank.
High Frequency Component Helps Explain the Generalization of Convolutional Neural Networks
May 28, 2019
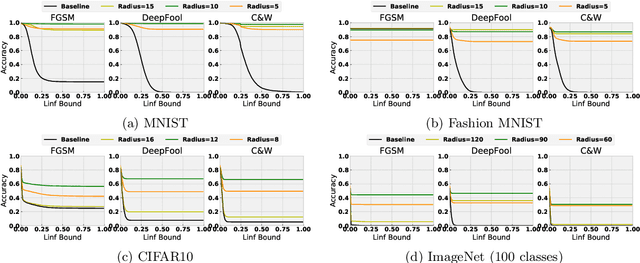
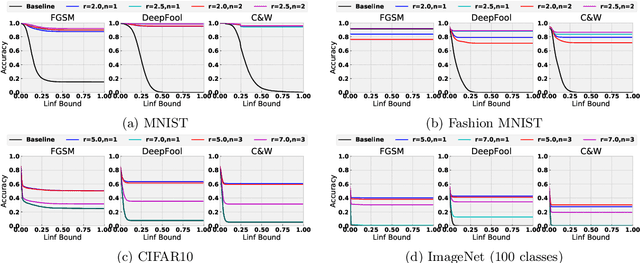
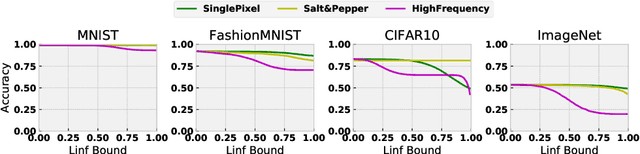
We investigate the relationship between the frequency spectrum of image data and the generalization behavior of convolutional neural networks (CNN). We first notice CNN's ability in capturing the high-frequency components of images. These high-frequency components are almost imperceptible to a human. Thus the observation can serve as one of the explanations of the existence of adversarial examples, and can also help verify CNN's trade-off between robustness and accuracy. Our observation also immediately leads to methods that can improve the adversarial robustness of trained CNN. Finally, we also utilize this observation to design a (semi) black-box adversarial attack method.
Learning to Represent Edits
Oct 31, 2018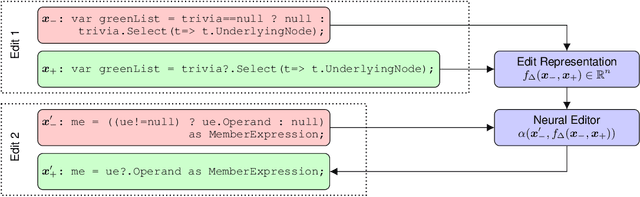
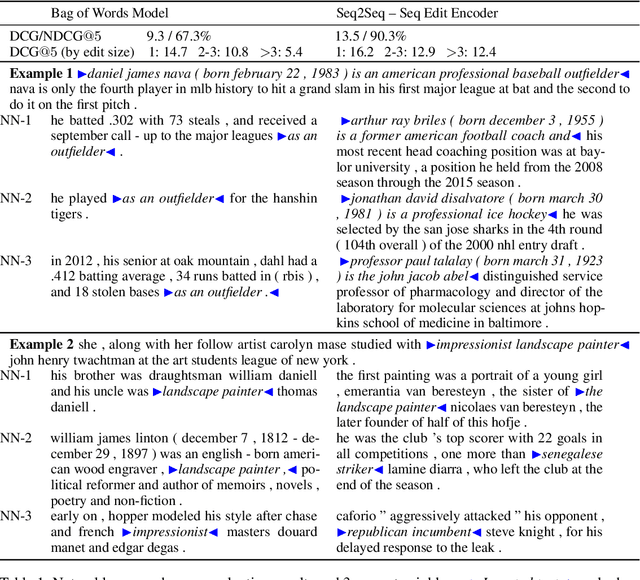
We introduce the problem of learning distributed representations of edits. By combining a "neural editor" with an "edit encoder", our models learn to represent the salient information of an edit and can be used to apply edits to new inputs. We experiment on natural language and source code edit data. Our evaluation yields promising results that suggest that our neural network models learn to capture the structure and semantics of edits. We hope that this interesting task and data source will inspire other researchers to work further on this problem.