 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Cloning is Not All You Need: The Optimality of On-Policy Distillation for Noisy Expert Feedback
Jun 29, 2026Imitation Learning is a natural framework for learning in sequential decision-making systems and has emerged as the dominant paradigm through which we understand language model training. A central puzzle is that, while in theory offline IL can be horizon-free and optimal, in practice online methods such as on-policy distillation often outperform offline methods such as supervised fine-tuning. We propose a noisy expert model to explain this gap, in which the learner only has access to a noisy version of the expert's policy, but wishes to compete against the reward achieved by a clean expert, motivated by the fact that in many applications, e.g. training language models to perform long chains of thought, the expert is often imperfect. In this setting, we show a sharp separation between offline and online IL. Offline learning from noisy trajectories is fundamentally hard: to compete with the clean expert, the sample complexity must grow exponentially, in contradistinction to the clean expert setting where no explicit horizon dependence exists. In contrast, we prove that online interaction with the noisy expert via a novel variant of OPD enables polynomial dependence on the horizon in general. We further show that, under a natural condition on the expert noise distribution, which we show to be necessary for any horizon-free sample complexity, one can obtain such a guarantee, although our proposed algorithm sacrifices statistical efficiency in its dependence on the size of the policy class. Our analysis leads to an alternative loss function that is commonly considered empirically for LM training. We further provide algorithms and lower bounds, and extend our results to the more realistic setting of unknown corruption when the clean expert is deterministic, thereby providing a theoretical foundation for why OPD can outperform SFT when training language models from imperfect teachers.
ContinuousBench: Can Differentially Private Synthetic Text Improve Capabilities?
Jun 01, 2026Differentially private (DP) text synthesis promises to unlock sensitive corpora for model training, but it remains unclear whether DP synthetic data transmits genuinely new knowledge and capabilities present only in those corpora. This is because existing evaluations rely on tasks that are nearly solvable without training, so strong benchmark performance does not establish that DP synthesis can substitute original data access. Thus, we introduce ContinuousBench, a continuously and automatically-regenerated benchmark that measures capability gain from DP synthetic text. Each quarter, a new release pairs a never-before-seen training corpus with a derived QA set, constructed to be: (1) unsolvable sans-corpus; and (2) learnable under DP, as the tested knowledge is supported by hundreds of independent records. Researchers produce DP synthetic data from the training corpus and run our standardized training and evaluation harness on their synthetic data to measure gains. We instantiate two tracks: Geminon, a procedurally-generated dataset about fictional creatures; and News, a stream of newly crawled public news articles. Although standard benchmarks are nearly saturated, on ContinuousBench we find that non-private synthesis transfers substantial knowledge from the original corpus, while state-of-the-art DP synthesis methods generally fail to do so, even at $\varepsilon=100$.
Privately Fine-Tuned LLMs Preserve Temporal Dynamics in Tabular Data
Feb 02, 2026Research on differentially private synthetic tabular data has largely focused on independent and identically distributed rows where each record corresponds to a unique individual. This perspective neglects the temporal complexity in longitudinal datasets, such as electronic health records, where a user contributes an entire (sub) table of sequential events. While practitioners might attempt to model such data by flattening user histories into high-dimensional vectors for use with standard marginal-based mechanisms, we demonstrate that this strategy is insufficient. Flattening fails to preserve temporal coherence even when it maintains valid marginal distributions. We introduce PATH, a novel generative framework that treats the full table as the unit of synthesis and leverages the autoregressive capabilities of privately fine-tuned large language models. Extensive evaluations show that PATH effectively captures long-range dependencies that traditional methods miss. Empirically, our method reduces the distributional distance to real trajectories by over 60% and reduces state transition errors by nearly 50% compared to leading marginal mechanisms while achieving similar marginal fidelity.
Convex Relaxation for Solving Large-Margin Classifiers in Hyperbolic Space
May 27, 2024



Hyperbolic spaces have increasingly been recognized for their outstanding performance in handling data with inherent hierarchical structures compared to their Euclidean counterparts. However, learning in hyperbolic spaces poses significant challenges. In particular, extending support vector machines to hyperbolic spaces is in general a constrained non-convex optimization problem. Previous and popular attempts to solve hyperbolic SVMs, primarily using projected gradient descent, are generally sensitive to hyperparameters and initializations, often leading to suboptimal solutions. In this work, by first rewriting the problem into a polynomial optimization, we apply semidefinite relaxation and sparse moment-sum-of-squares relaxation to effectively approximate the optima. From extensive empirical experiments, these methods are shown to perform better than the projected gradient descent approach.
Safeguarding Data in Multimodal AI: A Differentially Private Approach to CLIP Training
Jun 13, 2023



The surge in multimodal AI's success has sparked concerns over data privacy in vision-and-language tasks. While CLIP has revolutionized multimodal learning through joint training on images and text, its potential to unintentionally disclose sensitive information necessitates the integration of privacy-preserving mechanisms. We introduce a differentially private adaptation of the Contrastive Language-Image Pretraining (CLIP) model that effectively addresses privacy concerns while retaining accuracy. Our proposed method, Dp-CLIP, is rigorously evaluated on benchmark datasets encompassing diverse vision-and-language tasks such as image classification and visual question answering. We demonstrate that our approach retains performance on par with the standard non-private CLIP model. Furthermore, we analyze our proposed algorithm under linear representation settings. We derive the convergence rate of our algorithm and show a trade-off between utility and privacy when gradients are clipped per-batch and the loss function does not satisfy smoothness conditions assumed in the literature for the analysis of DP-SGD.
Improving Adversarial Transferability with Scheduled Step Size and Dual Example
Jan 30, 2023Deep neural networks are widely known to be vulnerable to adversarial examples, especially showing significantly poor performance on adversarial examples generated under the white-box setting. However, most white-box attack methods rely heavily on the target model and quickly get stuck in local optima, resulting in poor adversarial transferability. The momentum-based methods and their variants are proposed to escape the local optima for better transferability. In this work, we notice that the transferability of adversarial examples generated by the iterative fast gradient sign method (I-FGSM) exhibits a decreasing trend when increasing the number of iterations. Motivated by this finding, we argue that the information of adversarial perturbations near the benign sample, especially the direction, benefits more on the transferability. Thus, we propose a novel strategy, which uses the Scheduled step size and the Dual example (SD), to fully utilize the adversarial information near the benign sample. Our proposed strategy can be easily integrated with existing adversarial attack methods for better adversarial transferability. Empirical evaluations on the standard ImageNet dataset demonstrate that our proposed method can significantly enhance the transferability of existing adversarial attacks.
How Robust is your Fair Model? Exploring the Robustness of Diverse Fairness Strategies
Jul 12, 2022
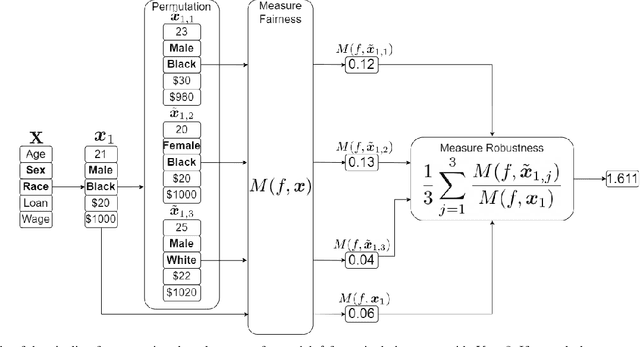
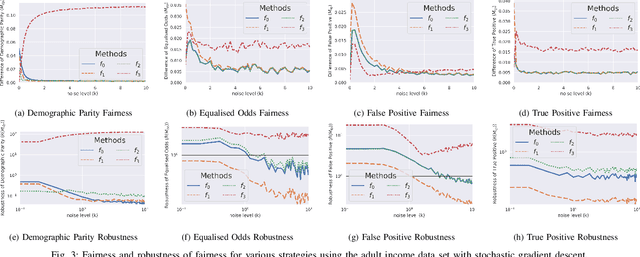
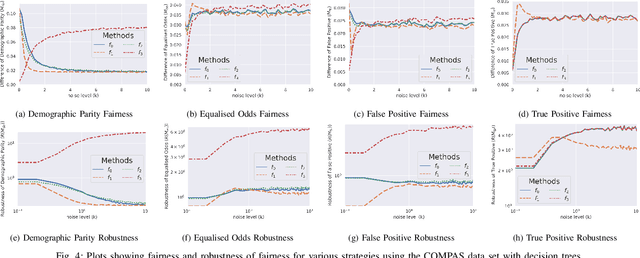
With the introduction of machine learning in high-stakes decision making, ensuring algorithmic fairness has become an increasingly important problem to solve. In response to this, many mathematical definitions of fairness have been proposed, and a variety of optimisation techniques have been developed, all designed to maximise a defined notion of fairness. However, fair solutions are reliant on the quality of the training data, and can be highly sensitive to noise. Recent studies have shown that robustness (the ability for a model to perform well on unseen data) plays a significant role in the type of strategy that should be used when approaching a new problem and, hence, measuring the robustness of these strategies has become a fundamental problem. In this work, we therefore propose a new criterion to measure the robustness of various fairness optimisation strategies - the robustness ratio. We conduct multiple extensive experiments on five bench mark fairness data sets using three of the most popular fairness strategies with respect to four of the most popular definitions of fairness. Our experiments empirically show that fairness methods that rely on threshold optimisation are very sensitive to noise in all the evaluated data sets, despite mostly outperforming other methods. This is in contrast to the other two methods, which are less fair for low noise scenarios but fairer for high noise ones. To the best of our knowledge, we are the first to quantitatively evaluate the robustness of fairness optimisation strategies. This can potentially can serve as a guideline in choosing the most suitable fairness strategy for various data sets.