 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectralGPT: Spectral Foundation Model
Nov 25, 2023



The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Masking Hyperspectral Imaging Data with Pretrained Models
Nov 06, 2023



The presence of undesired background areas associated with potential noise and unknown spectral characteristics degrades the performance of hyperspectral data processing. Masking out unwanted regions is key to addressing this issue. Processing only regions of interest yields notable improvements in terms of computational costs, required memory, and overall performance. The proposed processing pipeline encompasses two fundamental parts: regions of interest mask generation, followed by the application of hyperspectral data processing techniques solely on the newly masked hyperspectral cube. The novelty of our work lies in the methodology adopted for the preliminary image segmentation. We employ the Segment Anything Model (SAM) to extract all objects within the dataset, and subsequently refine the segments with a zero-shot Grounding Dino object detector, followed by intersection and exclusion filtering steps, without the need for fine-tuning or retraining. To illustrate the efficacy of the masking procedure, the proposed method is deployed on three challenging applications scenarios that demand accurate masking; shredded plastics characterization, drill core scanning, and litter monitoring. The numerical evaluation of the proposed masking method on the three applications is provided along with the used hyperparameters. The scripts for the method will be available at https://github.com/hifexplo/Masking.
RSAdapter: Adapting Multimodal Models for Remote Sensing Visual Question Answering
Oct 19, 2023



In recent years, with the rapid advancement of transformer models, transformer-based multimodal architectures have found wide application in various downstream tasks, including but not limited to Image Captioning, Visual Question Answering (VQA), and Image-Text Generation. However, contemporary approaches to Remote Sensing (RS) VQA often involve resource-intensive techniques, such as full fine-tuning of large models or the extraction of image-text features from pre-trained multimodal models, followed by modality fusion using decoders. These approaches demand significant computational resources and time, and a considerable number of trainable parameters are introduced. To address these challenges, we introduce a novel method known as RSAdapter, which prioritizes runtime and parameter efficiency. RSAdapter comprises two key components: the Parallel Adapter and an additional linear transformation layer inserted after each fully connected (FC) layer within the Adapter. This approach not only improves adaptation to pre-trained multimodal models but also allows the parameters of the linear transformation layer to be integrated into the preceding FC layers during inference, reducing inference costs. To demonstrate the effectiveness of RSAdapter, we conduct an extensive series of experiments using three distinct RS-VQA datasets and achieve state-of-the-art results on all three datasets. The code for RSAdapter will be available online at https://github.com/Y-D-Wang/RSAdapter.
Spatial Gated Multi-Layer Perceptron for Land Use and Land Cover Mapping
Aug 09, 2023



Convolutional Neural Networks (CNNs) are models that are utilized extensively for the hierarchical extraction of features. Vision transformers (ViTs), through the use of a self-attention mechanism, have recently achieved superior modeling of global contextual information compared to CNNs. However, to realize their image classification strength, ViTs require substantial training datasets. Where the available training data are limited, current advanced multi-layer perceptrons (MLPs) can provide viable alternatives to both deep CNNs and ViTs. In this paper, we developed the SGU-MLP, a learning algorithm that effectively uses both MLPs and spatial gating units (SGUs) for precise land use land cover (LULC) mapping. Results illustrated the superiority of the developed SGU-MLP classification algorithm over several CNN and CNN-ViT-based models, including HybridSN, ResNet, iFormer, EfficientFormer and CoAtNet. The proposed SGU-MLP algorithm was tested through three experiments in Houston, USA, Berlin, Germany and Augsburg, Germany. The SGU-MLP classification model was found to consistently outperform the benchmark CNN and CNN-ViT-based algorithms. For example, for the Houston experiment, SGU-MLP significantly outperformed HybridSN, CoAtNet, Efficientformer, iFormer and ResNet by approximately 15%, 19%, 20%, 21%, and 25%, respectively, in terms of average accuracy. The code will be made publicly available at https://github.com/aj1365/SGUMLP
Universal Adversarial Defense in Remote Sensing Based on Pre-trained Denoising Diffusion Models
Aug 02, 2023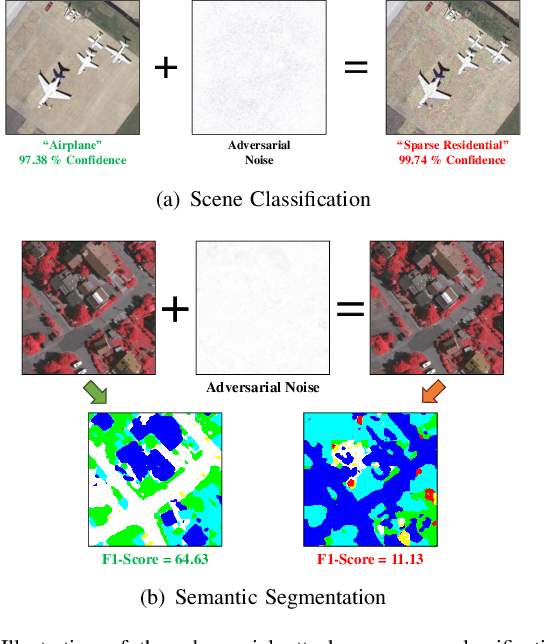
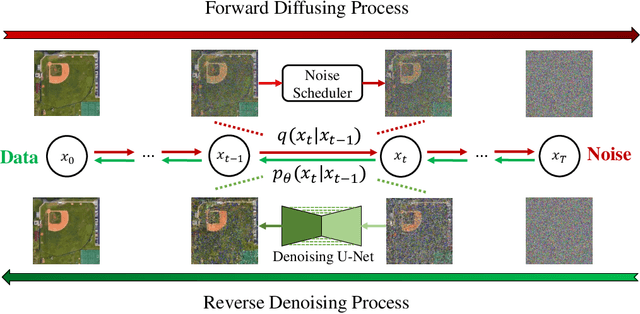
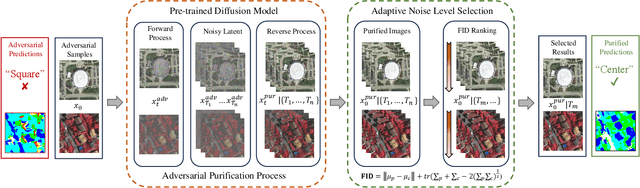

Deep neural networks (DNNs) have achieved tremendous success in many remote sensing (RS) applications, in which DNNs are vulnerable to adversarial perturbations. Unfortunately, current adversarial defense approaches in RS studies usually suffer from performance fluctuation and unnecessary re-training costs due to the need for prior knowledge of the adversarial perturbations among RS data. To circumvent these challenges, we propose a universal adversarial defense approach in RS imagery (UAD-RS) using pre-trained diffusion models to defend the common DNNs against multiple unknown adversarial attacks. Specifically, the generative diffusion models are first pre-trained on different RS datasets to learn generalized representations in various data domains. After that, a universal adversarial purification framework is developed using the forward and reverse process of the pre-trained diffusion models to purify the perturbations from adversarial samples. Furthermore, an adaptive noise level selection (ANLS) mechanism is built to capture the optimal noise level of the diffusion model that can achieve the best purification results closest to the clean samples according to their Frechet Inception Distance (FID) in deep feature space. As a result, only a single pre-trained diffusion model is needed for the universal purification of adversarial samples on each dataset, which significantly alleviates the re-training efforts and maintains high performance without prior knowledge of the adversarial perturbations. Experiments on four heterogeneous RS datasets regarding scene classification and semantic segmentation verify that UAD-RS outperforms state-of-the-art adversarial purification approaches with a universal defense against seven commonly existing adversarial perturbations. Codes and the pre-trained models are available online (https://github.com/EricYu97/UAD-RS).
Neighborhood Attention Makes the Encoder of ResUNet Stronger for Accurate Road Extraction
Jun 08, 2023



In the domain of remote sensing image interpretation, road extraction from high-resolution aerial imagery has already been a hot research topic. Although deep CNNs have presented excellent results for semantic segmentation, the efficiency and capabilities of vision transformers are yet to be fully researched. As such, for accurate road extraction, a deep semantic segmentation neural network that utilizes the abilities of residual learning, HetConvs, UNet, and vision transformers, which is called \texttt{ResUNetFormer}, is proposed in this letter. The developed \texttt{ResUNetFormer} is evaluated on various cutting-edge deep learning-based road extraction techniques on the public Massachusetts road dataset. Statistical and visual results demonstrate the superiority of the \texttt{ResUNetFormer} over the state-of-the-art CNNs and vision transformers for segmentation. The code will be made available publicly at \url{https://github.com/aj1365/ResUNetFormer}.
Tinto: Multisensor Benchmark for 3D Hyperspectral Point Cloud Segmentation in the Geosciences
May 17, 2023The increasing use of deep learning techniques has reduced interpretation time and, ideally, reduced interpreter bias by automatically deriving geological maps from digital outcrop models. However, accurate validation of these automated mapping approaches is a significant challenge due to the subjective nature of geological mapping and the difficulty in collecting quantitative validation data. Additionally, many state-of-the-art deep learning methods are limited to 2D image data, which is insufficient for 3D digital outcrops, such as hyperclouds. To address these challenges, we present Tinto, a multi-sensor benchmark digital outcrop dataset designed to facilitate the development and validation of deep learning approaches for geological mapping, especially for non-structured 3D data like point clouds. Tinto comprises two complementary sets: 1) a real digital outcrop model from Corta Atalaya (Spain), with spectral attributes and ground-truth data, and 2) a synthetic twin that uses latent features in the original datasets to reconstruct realistic spectral data (including sensor noise and processing artifacts) from the ground-truth. The point cloud is dense and contains 3,242,964 labeled points. We used these datasets to explore the abilities of different deep learning approaches for automated geological mapping. By making Tinto publicly available, we hope to foster the development and adaptation of new deep learning tools for 3D applications in Earth sciences. The dataset can be accessed through this link: https://doi.org/10.14278/rodare.2256.
Dsfer-Net: A Deep Supervision and Feature Retrieval Network for Bitemporal Change Detection Using Modern Hopfield Networks
Apr 03, 2023



Change detection, as an important application for high-resolution remote sensing images, aims to monitor and analyze changes in the land surface over time. With the rapid growth in the quantity of high-resolution remote sensing data and the complexity of texture features, a number of quantitative deep learning-based methods have been proposed. Although these methods outperform traditional change detection methods by extracting deep features and combining spatial-temporal information, reasonable explanations about how deep features work on improving the detection performance are still lacking. In our investigations, we find that modern Hopfield network layers achieve considerable performance in semantic understandings. In this paper, we propose a Deep Supervision and FEature Retrieval network (Dsfer-Net) for bitemporal change detection. Specifically, the highly representative deep features of bitemporal images are jointly extracted through a fully convolutional Siamese network. Based on the sequential geo-information of the bitemporal images, we then design a feature retrieval module to retrieve the difference feature and leverage discriminative information in a deeply supervised manner. We also note that the deeply supervised feature retrieval module gives explainable proofs about the semantic understandings of the proposed network in its deep layers. Finally, this end-to-end network achieves a novel framework by aggregating the retrieved features and feature pairs from different layers. Experiments conducted on three public datasets (LEVIR-CD, WHU-CD, and CDD) confirm the superiority of the proposed Dsfer-Net over other state-of-the-art methods. Code will be available online (https://github.com/ShizhenChang/Dsfer-Net).
Changes to Captions: An Attentive Network for Remote Sensing Change Captioning
Apr 03, 2023



In recent years, advanced research has focused on the direct learning and analysis of remote sensing images using natural language processing (NLP) techniques. The ability to accurately describe changes occurring in multi-temporal remote sensing images is becoming increasingly important for geospatial understanding and land planning. Unlike natural image change captioning tasks, remote sensing change captioning aims to capture the most significant changes, irrespective of various influential factors such as illumination, seasonal effects, and complex land covers. In this study, we highlight the significance of accurately describing changes in remote sensing images and present a comparison of the change captioning task for natural and synthetic images and remote sensing images. To address the challenge of generating accurate captions, we propose an attentive changes-to-captions network, called Chg2Cap for short, for bi-temporal remote sensing images. The network comprises three main components: 1) a Siamese CNN-based feature extractor to collect high-level representations for each image pair; 2) an attentive decoder that includes a hierarchical self-attention block to locate change-related features and a residual block to generate the image embedding; and 3) a transformer-based caption generator to decode the relationship between the image embedding and the word embedding into a description. The proposed Chg2Cap network is evaluated on two representative remote sensing datasets, and a comprehensive experimental analysis is provided. The code and pre-trained models will be available online at https://github.com/ShizhenChang/Chg2Cap.
AI Security for Geoscience and Remote Sensing: Challenges and Future Trends
Dec 19, 2022Recent advances in artificial intelligence (AI) have significantly intensified research in the geoscience and remote sensing (RS) field. AI algorithms, especially deep learning-based ones, have been developed and applied widely to RS data analysis. The successful application of AI covers almost all aspects of Earth observation (EO) missions, from low-level vision tasks like super-resolution, denoising, and inpainting, to high-level vision tasks like scene classification, object detection, and semantic segmentation. While AI techniques enable researchers to observe and understand the Earth more accurately, the vulnerability and uncertainty of AI models deserve further attention, considering that many geoscience and RS tasks are highly safety-critical. This paper reviews the current development of AI security in the geoscience and RS field, covering the following five important aspects: adversarial attack, backdoor attack, federated learning, uncertainty, and explainability. Moreover, the potential opportunities and trends are discussed to provide insights for future research. To the best of the authors' knowledge, this paper is the first attempt to provide a systematic review of AI security-related research in the geoscience and RS community. Available code and datasets are also listed in the paper to move this vibrant field of research forward.