 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023



Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.
CBR-iKB: A Case-Based Reasoning Approach for Question Answering over Incomplete Knowledge Bases
Apr 18, 2022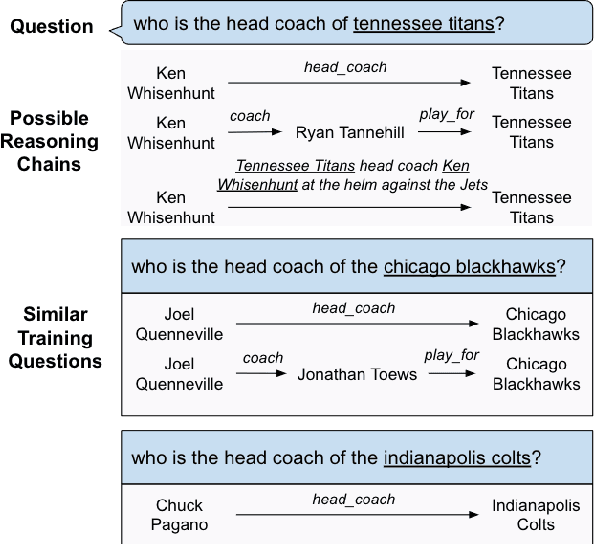
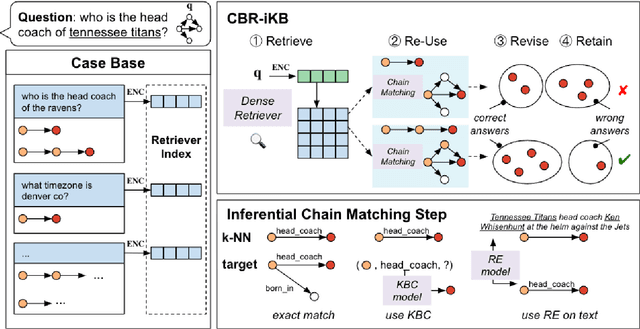
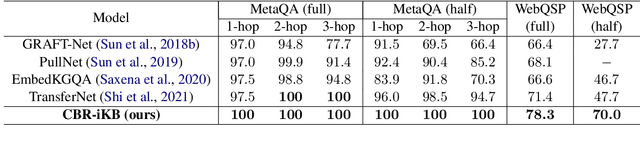
Knowledge bases (KBs) are often incomplete and constantly changing in practice. Yet, in many question answering applications coupled with knowledge bases, the sparse nature of KBs is often overlooked. To this end, we propose a case-based reasoning approach, CBR-iKB, for knowledge base question answering (KBQA) with incomplete-KB as our main focus. Our method ensembles decisions from multiple reasoning chains with a novel nonparametric reasoning algorithm. By design, CBR-iKB can seamlessly adapt to changes in KBs without any task-specific training or fine-tuning. Our method achieves 100% accuracy on MetaQA and establishes new state-of-the-art on multiple benchmarks. For instance, CBR-iKB achieves an accuracy of 70% on WebQSP under the incomplete-KB setting, outperforming the existing state-of-the-art method by 22.3%.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022



Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
Learning to Transpile AMR into SPARQL
Dec 15, 2021

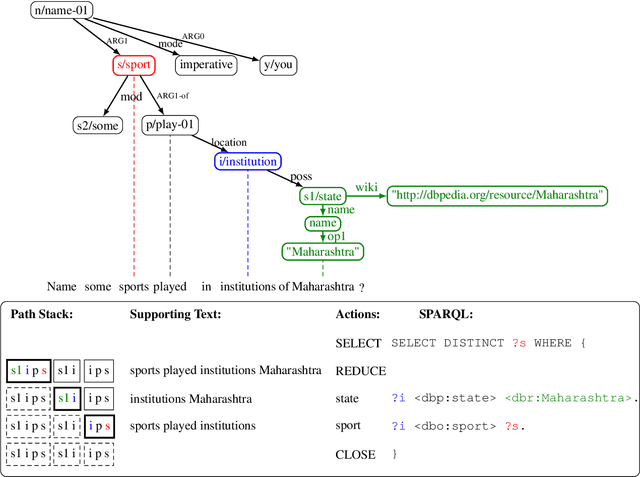
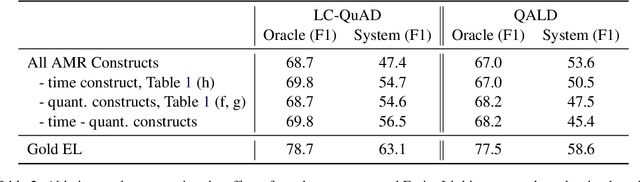
We propose a transition-based system to transpile Abstract Meaning Representation (AMR) into SPARQL for Knowledge Base Question Answering (KBQA). This allows to delegate part of the abstraction problem to a strongly pre-trained semantic parser, while learning transpiling with small amount of paired data. We departure from recent work relating AMR and SPARQL constructs, but rather than applying a set of rules, we teach the BART model to selectively use these relations. Further, we avoid explicitly encoding AMR but rather encode the parser state in the attention mechanism of BART, following recent semantic parsing works. The resulting model is simple, provides supporting text for its decisions, and outperforms recent progress in AMR-based KBQA in LC-QuAD (F1 53.4), matching it in QALD (F1 30.8), while exploiting the same inductive biases.
A Two-Stage Approach towards Generalization in Knowledge Base Question Answering
Nov 17, 2021
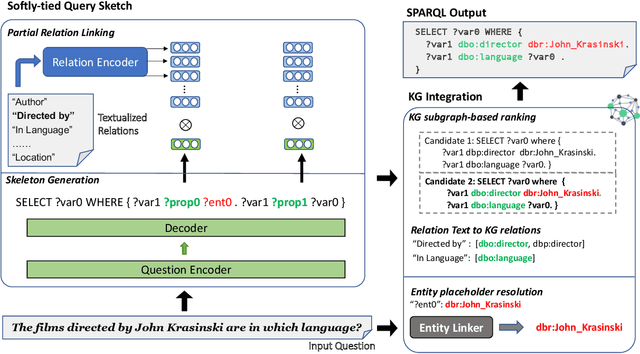
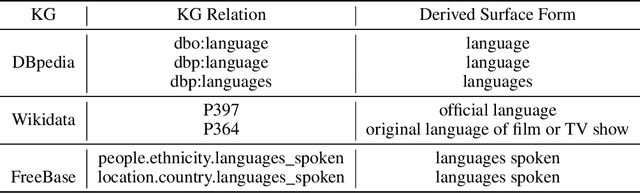
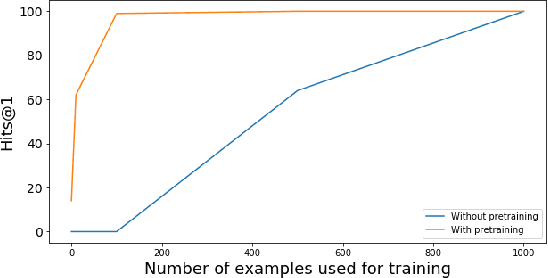
Most existing approaches for Knowledge Base Question Answering (KBQA) focus on a specific underlying knowledge base either because of inherent assumptions in the approach, or because evaluating it on a different knowledge base requires non-trivial changes. However, many popular knowledge bases share similarities in their underlying schemas that can be leveraged to facilitate generalization across knowledge bases. To achieve this generalization, we introduce a KBQA framework based on a 2-stage architecture that explicitly separates semantic parsing from the knowledge base interaction, facilitating transfer learning across datasets and knowledge graphs. We show that pretraining on datasets with a different underlying knowledge base can nevertheless provide significant performance gains and reduce sample complexity. Our approach achieves comparable or state-of-the-art performance for LC-QuAD (DBpedia), WebQSP (Freebase), SimpleQuestions (Wikidata) and MetaQA (Wikimovies-KG).
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021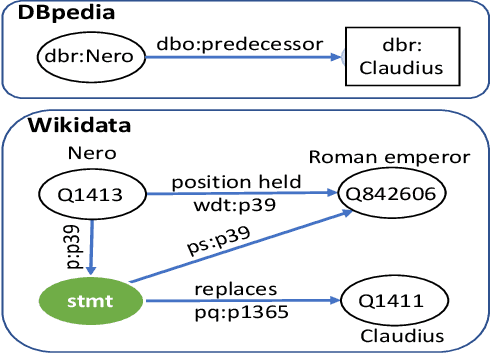


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Combining Rules and Embeddings via Neuro-Symbolic AI for Knowledge Base Completion
Sep 16, 2021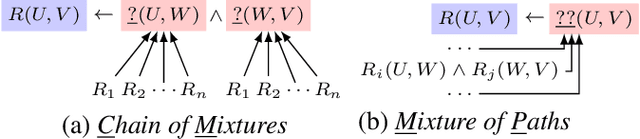
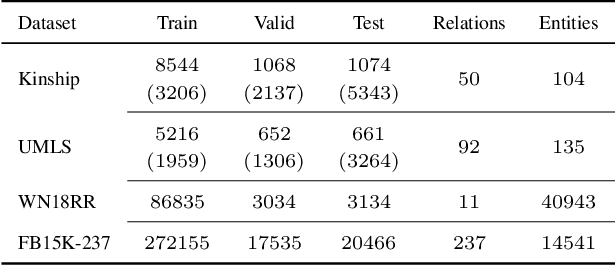
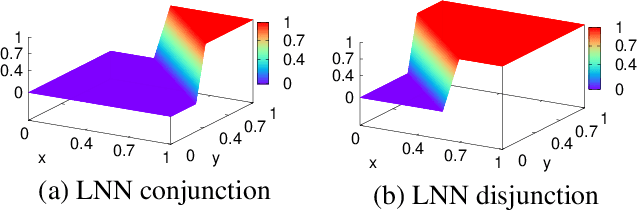
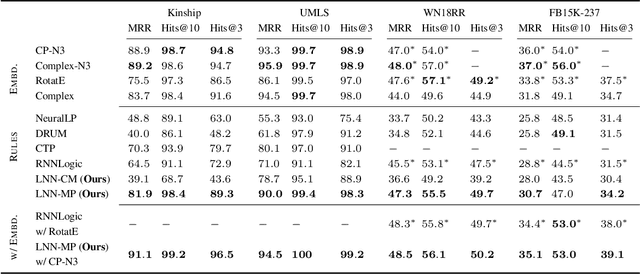
Recent interest in Knowledge Base Completion (KBC) has led to a plethora of approaches based on reinforcement learning, inductive logic programming and graph embeddings. In particular, rule-based KBC has led to interpretable rules while being comparable in performance with graph embeddings. Even within rule-based KBC, there exist different approaches that lead to rules of varying quality and previous work has not always been precise in highlighting these differences. Another issue that plagues most rule-based KBC is the non-uniformity of relation paths: some relation sequences occur in very few paths while others appear very frequently. In this paper, we show that not all rule-based KBC models are the same and propose two distinct approaches that learn in one case: 1) a mixture of relations and the other 2) a mixture of paths. When implemented on top of neuro-symbolic AI, which learns rules by extending Boolean logic to real-valued logic, the latter model leads to superior KBC accuracy outperforming state-of-the-art rule-based KBC by 2-10% in terms of mean reciprocal rank. Furthermore, to address the non-uniformity of relation paths, we combine rule-based KBC with graph embeddings thus improving our results even further and achieving the best of both worlds.
Generative Relation Linking for Question Answering over Knowledge Bases
Aug 16, 2021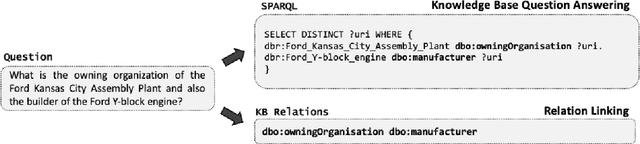
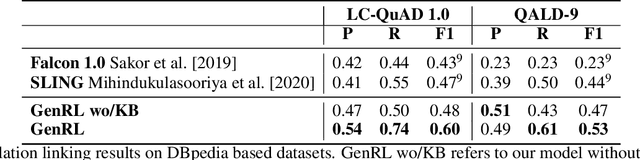
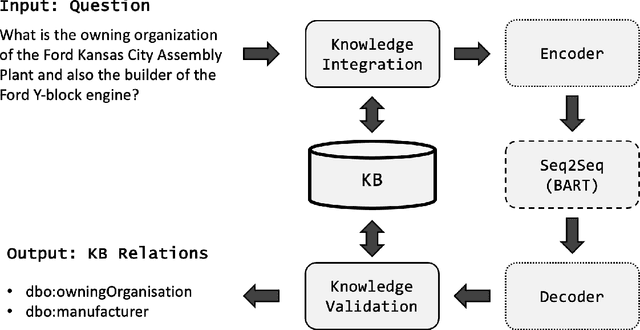
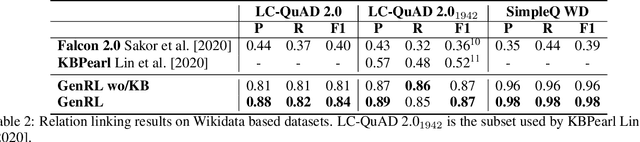
Relation linking is essential to enable question answering over knowledge bases. Although there are various efforts to improve relation linking performance, the current state-of-the-art methods do not achieve optimal results, therefore, negatively impacting the overall end-to-end question answering performance. In this work, we propose a novel approach for relation linking framing it as a generative problem facilitating the use of pre-trained sequence-to-sequence models. We extend such sequence-to-sequence models with the idea of infusing structured data from the target knowledge base, primarily to enable these models to handle the nuances of the knowledge base. Moreover, we train the model with the aim to generate a structured output consisting of a list of argument-relation pairs, enabling a knowledge validation step. We compared our method against the existing relation linking systems on four different datasets derived from DBpedia and Wikidata. Our method reports large improvements over the state-of-the-art while using a much simpler model that can be easily adapted to different knowledge bases.
Learning to Guide a Saturation-Based Theorem Prover
Jun 07, 2021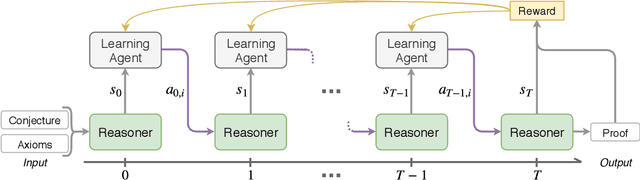
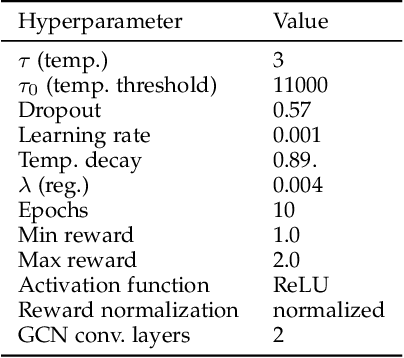
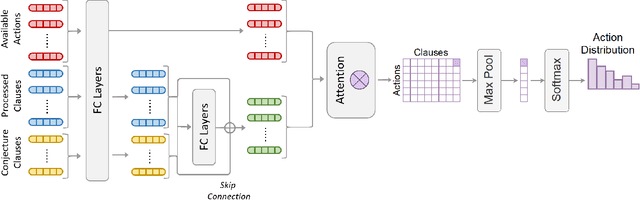
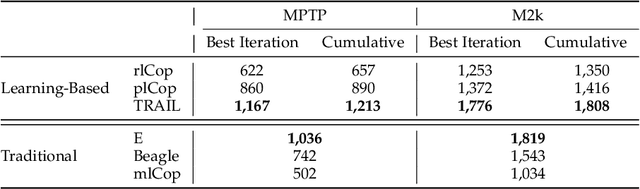
Traditional automated theorem provers have relied on manually tuned heuristics to guide how they perform proof search. Recently, however, there has been a surge of interest in the design of learning mechanisms that can be integrated into theorem provers to improve their performance automatically. In this work, we introduce TRAIL, a deep learning-based approach to theorem proving that characterizes core elements of saturation-based theorem proving within a neural framework. TRAIL leverages (a) an effective graph neural network for representing logical formulas, (b) a novel neural representation of the state of a saturation-based theorem prover in terms of processed clauses and available actions, and (c) a novel representation of the inference selection process as an attention-based action policy. We show through a systematic analysis that these components allow TRAIL to significantly outperform previous reinforcement learning-based theorem provers on two standard benchmark datasets (up to 36% more theorems proved). In addition, to the best of our knowledge, TRAIL is the first reinforcement learning-based approach to exceed the performance of a state-of-the-art traditional theorem prover on a standard theorem proving benchmark (solving up to 17% more problems).
Logic Embeddings for Complex Query Answering
Feb 28, 2021Answering logical queries over incomplete knowledge bases is challenging because: 1) it calls for implicit link prediction, and 2) brute force answering of existential first-order logic queries is exponential in the number of existential variables. Recent work of query embeddings provides fast querying, but most approaches model set logic with closed regions, so lack negation. Query embeddings that do support negation use densities that suffer drawbacks: 1) only improvise logic, 2) use expensive distributions, and 3) poorly model answer uncertainty. In this paper, we propose Logic Embeddings, a new approach to embedding complex queries that uses Skolemisation to eliminate existential variables for efficient querying. It supports negation, but improves on density approaches: 1) integrates well-studied t-norm logic and directly evaluates satisfiability, 2) simplifies modeling with truth values, and 3) models uncertainty with truth bounds. Logic Embeddings are competitively fast and accurate in query answering over large, incomplete knowledge graphs, outperform on negation queries, and in particular, provide improved modeling of answer uncertainty as evidenced by a superior correlation between answer set size and embedding entropy.