 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Generalization in Coreference Resolution
Sep 20, 2021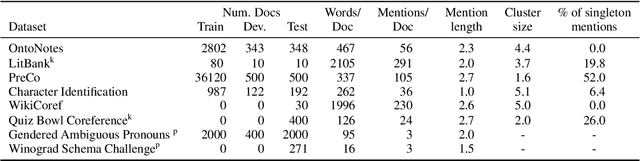
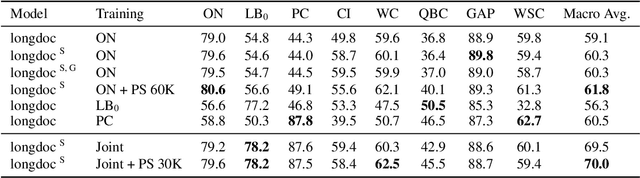

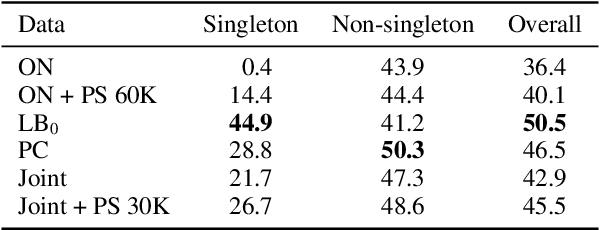
While coreference resolution is defined independently of dataset domain, most models for performing coreference resolution do not transfer well to unseen domains. We consolidate a set of 8 coreference resolution datasets targeting different domains to evaluate the off-the-shelf performance of models. We then mix three datasets for training; even though their domain, annotation guidelines, and metadata differ, we propose a method for jointly training a single model on this heterogeneous data mixture by using data augmentation to account for annotation differences and sampling to balance the data quantities. We find that in a zero-shot setting, models trained on a single dataset transfer poorly while joint training yields improved overall performance, leading to better generalization in coreference resolution models. This work contributes a new benchmark for robust coreference resolution and multiple new state-of-the-art results.
Moving on from OntoNotes: Coreference Resolution Model Transfer
Apr 17, 2021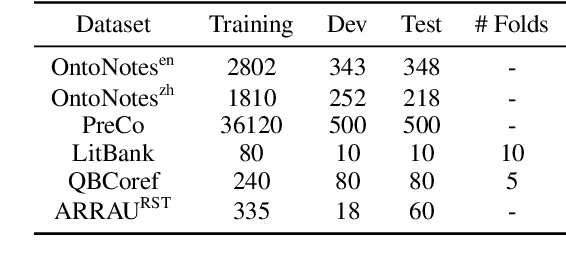
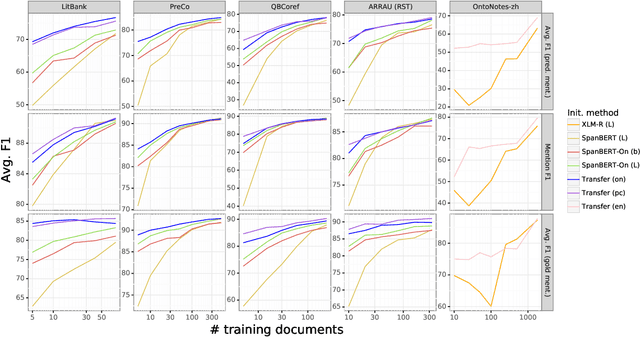
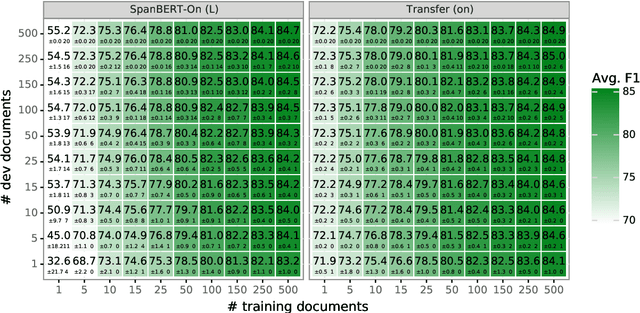
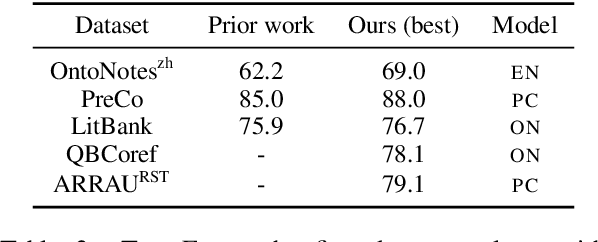
Academic neural models for coreference resolution are typically trained on a single dataset (OntoNotes) and model improvements are then benchmarked on that dataset. However, real-world usages of coreference resolution models depend on the annotation guidelines and the domain of the target dataset, which often differ from those of OntoNotes. We aim to quantify transferability of coreference resolution models based on the number of annotated documents available in the target dataset. We examine five target datasets and find that continued training is consistently effective and especially beneficial when there are few target documents. We establish new benchmarks across several datasets, including state-of-the-art results on LitBank and PreCo.
Adaptive Active Learning for Coreference Resolution
Apr 15, 2021
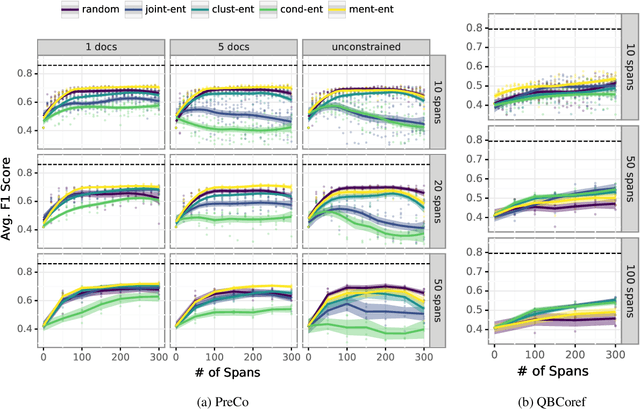

Training coreference resolution models require comprehensively labeled data. A model trained on one dataset may not successfully transfer to new domains. This paper investigates an approach to active learning for coreference resolution that feeds discrete annotations to an incremental clustering model. The recent developments in incremental coreference resolution allow for a novel approach to active learning in this setting. Through this new framework, we analyze important factors in data acquisition, like sources of model uncertainty and balancing reading and labeling costs. We explore different settings through simulated labeling with gold data. By lowering the data barrier for coreference, coreference resolvers can rapidly adapt to a series of previously unconsidered domains.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021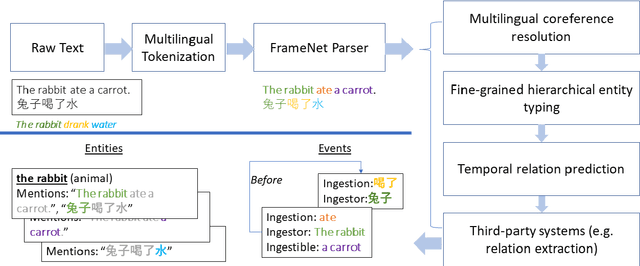
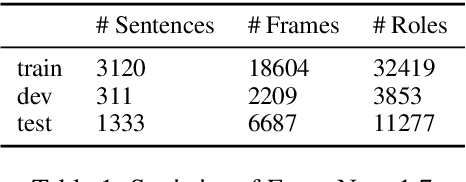
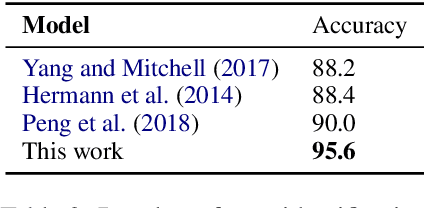
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
CopyNext: Explicit Span Copying and Alignment in Sequence to Sequence Models
Oct 28, 2020
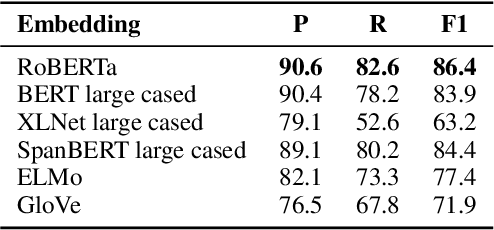
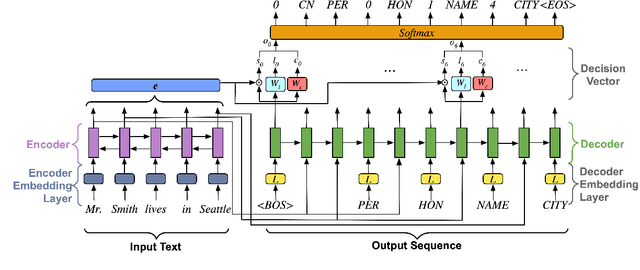
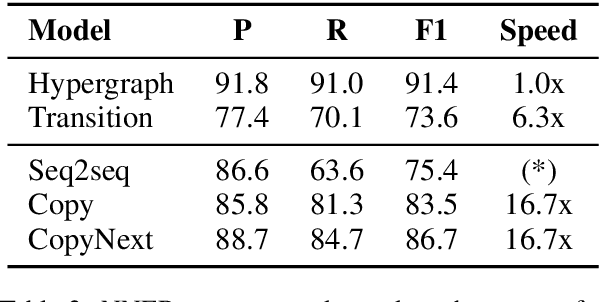
Copy mechanisms are employed in sequence to sequence models (seq2seq) to generate reproductions of words from the input to the output. These frameworks, operating at the lexical type level, fail to provide an explicit alignment that records where each token was copied from. Further, they require contiguous token sequences from the input (spans) to be copied individually. We present a model with an explicit token-level copy operation and extend it to copying entire spans. Our model provides hard alignments between spans in the input and output, allowing for nontraditional applications of seq2seq, like information extraction. We demonstrate the approach on Nested Named Entity Recognition, achieving near state-of-the-art accuracy with an order of magnitude increase in decoding speed.
Which *BERT? A Survey Organizing Contextualized Encoders
Oct 02, 2020Pretrained contextualized text encoders are now a staple of the NLP community. We present a survey on language representation learning with the aim of consolidating a series of shared lessons learned across a variety of recent efforts. While significant advancements continue at a rapid pace, we find that enough has now been discovered, in different directions, that we can begin to organize advances according to common themes. Through this organization, we highlight important considerations when interpreting recent contributions and choosing which model to use.
Revisiting Memory-Efficient Incremental Coreference Resolution
Apr 30, 2020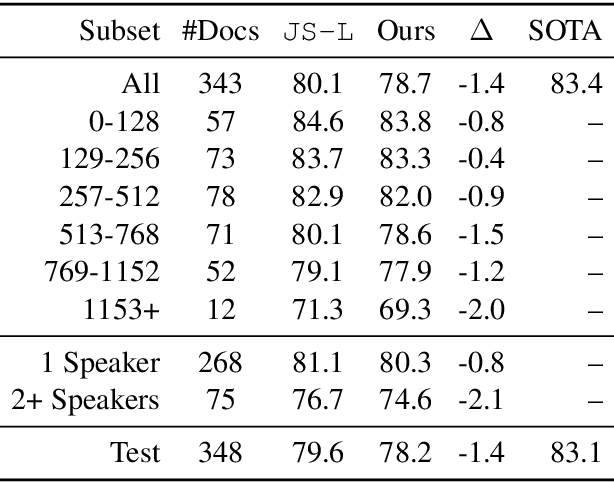
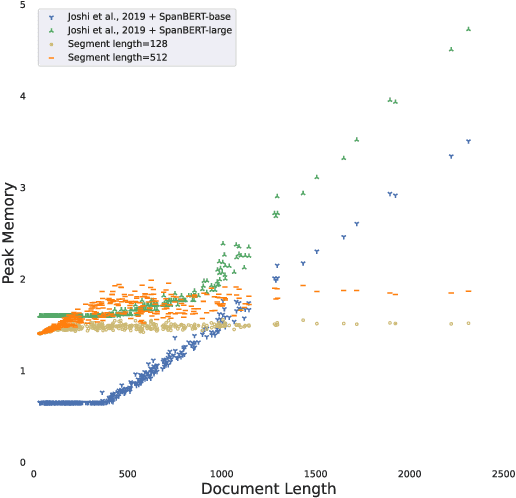
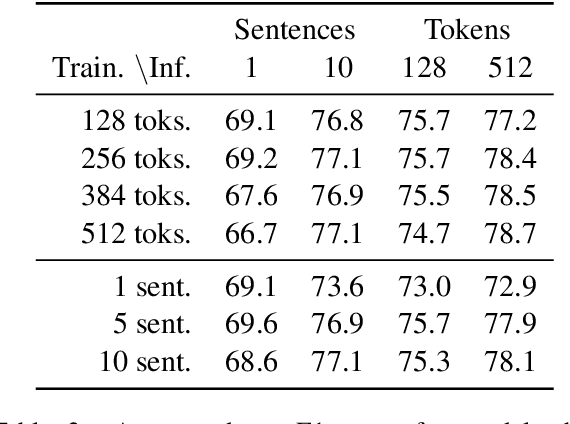
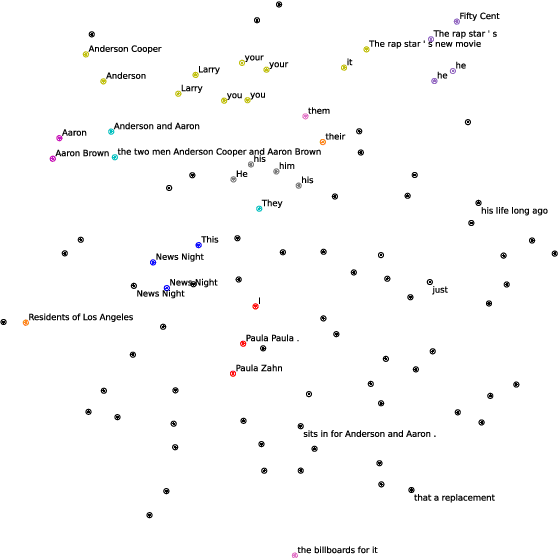
We explore the task of coreference resolution under fixed memory by extending an incremental clustering algorithm to utilize contextualized encoders and neural components. Our algorithm creates explicit representations for each entity, where given a new sentence, spans are proposed and subsequently scored against each entity representation, leading to emergent clusters. Our approach is end-to-end trainable and can be used to transform existing models, leading to an asymptotic reduction in memory usage while remaining competitive on task performance, which allows for more efficient use of computational resources for short documents, and making coreference more feasible across very long document contexts.
Multi-Sentence Argument Linking
Nov 09, 2019
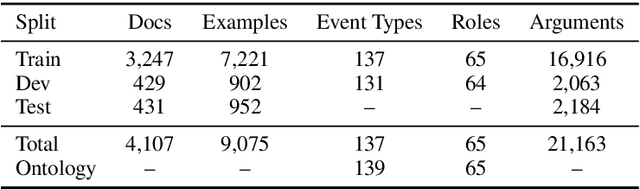
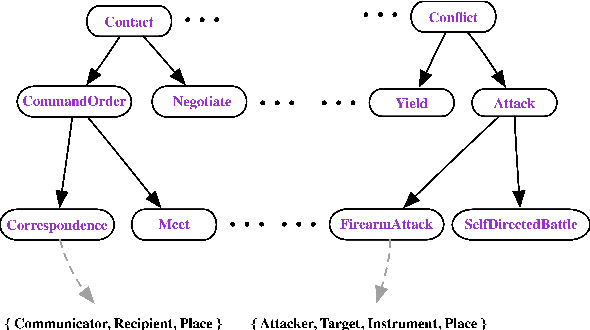
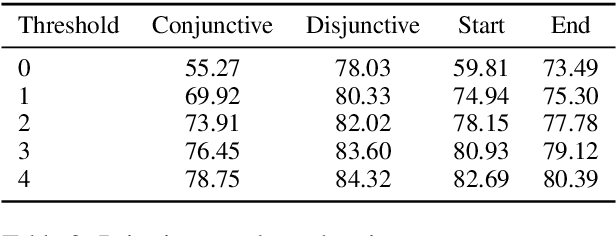
We introduce a dataset with annotated Roles Across Multiple Sentences (RAMS), consisting of over 9,000 annotated events. This enables the development of a novel span-based labeling framework that operates at the document level, which connects related ideas in sentence-level semantic role labeling and coreference resolution. We achieve 68.1 F1 on RAMS when given argument span boundaries and 73.2 F1 when also given gold event types. We additionally illustrate the applicability of the approach to the slot filling task in the Gun Violence Database.
What do you learn from context? Probing for sentence structure in contextualized word representations
May 15, 2019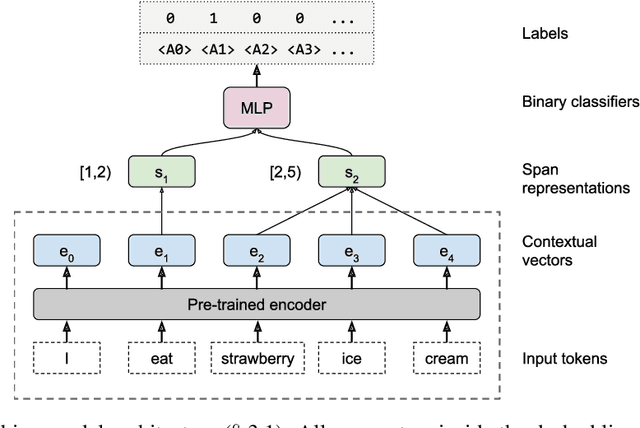

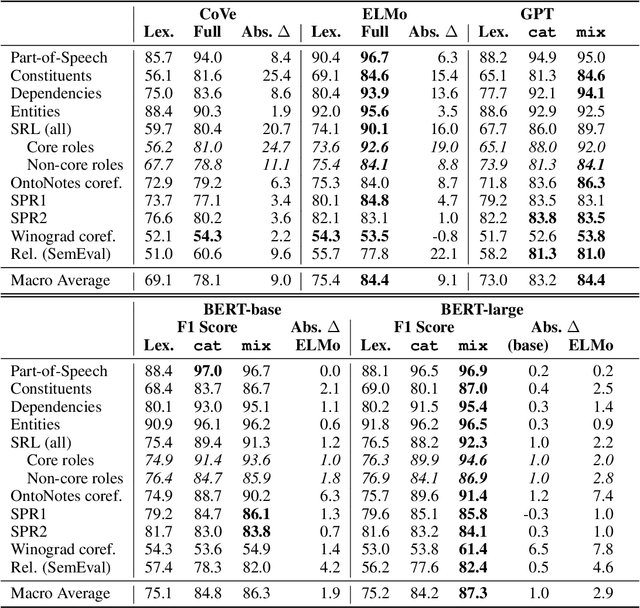
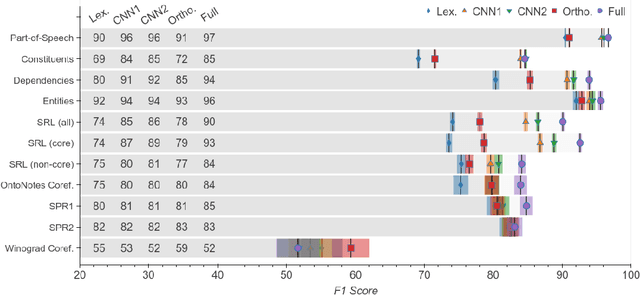
Contextualized representation models such as ELMo (Peters et al., 2018a) and BERT (Devlin et al., 2018) have recently achieved state-of-the-art results on a diverse array of downstream NLP tasks. Building on recent token-level probing work, we introduce a novel edge probing task design and construct a broad suite of sub-sentence tasks derived from the traditional structured NLP pipeline. We probe word-level contextual representations from four recent models and investigate how they encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena. We find that existing models trained on language modeling and translation produce strong representations for syntactic phenomena, but only offer comparably small improvements on semantic tasks over a non-contextual baseline.
Probing What Different NLP Tasks Teach Machines about Function Word Comprehension
Apr 25, 2019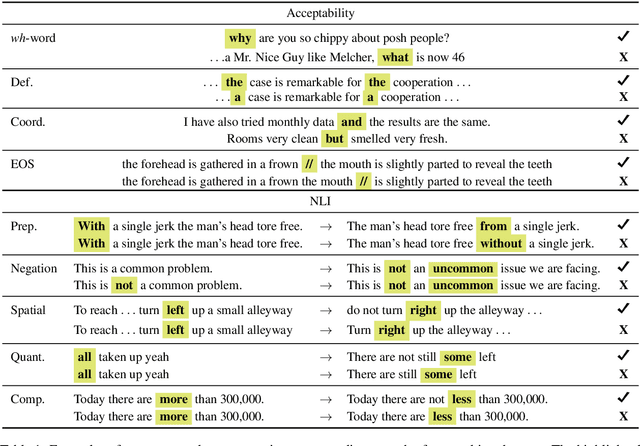
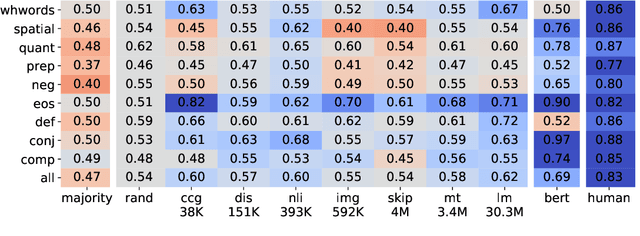

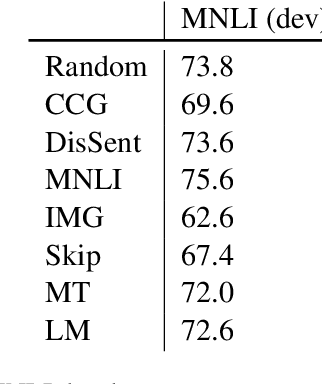
We introduce a set of nine challenge tasks that test for the understanding of function words. These tasks are created by structurally mutating sentences from existing datasets to target the comprehension of specific types of function words (e.g., prepositions, wh-words). Using these probing tasks, we explore the effects of various pretraining objectives for sentence encoders (e.g., language modeling, CCG supertagging and natural language inference (NLI)) on the learned representations. Our results show that pretraining on CCG---our most syntactic objective---performs the best on average across our probing tasks, suggesting that syntactic knowledge helps function word comprehension. Language modeling also shows strong performance, supporting its widespread use for pretraining state-of-the-art NLP models. Overall, no pretraining objective dominates across the board, and our function word probing tasks highlight several intuitive differences between pretraining objectives, e.g., that NLI helps the comprehension of negation.