 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Source-LDA: Enhancing probabilistic topic models using prior knowledge sources
May 17, 2017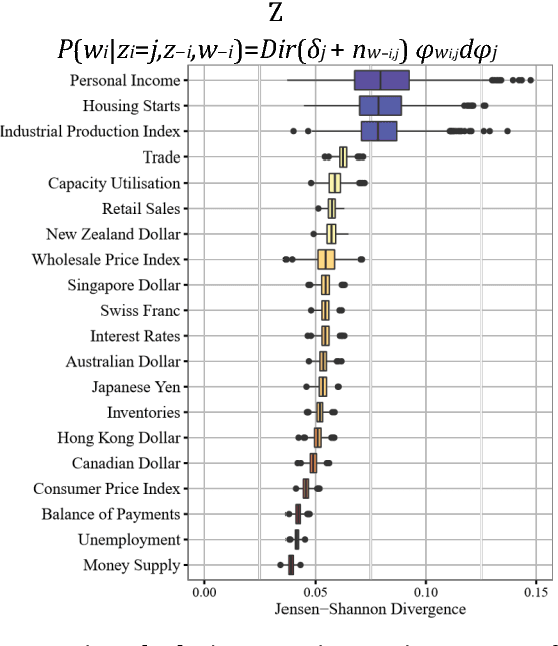
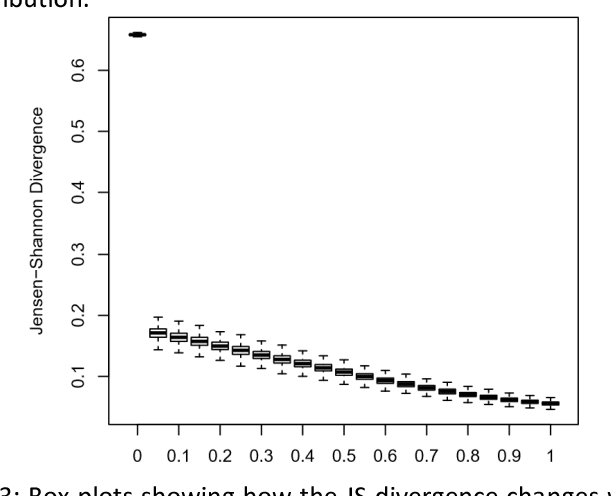
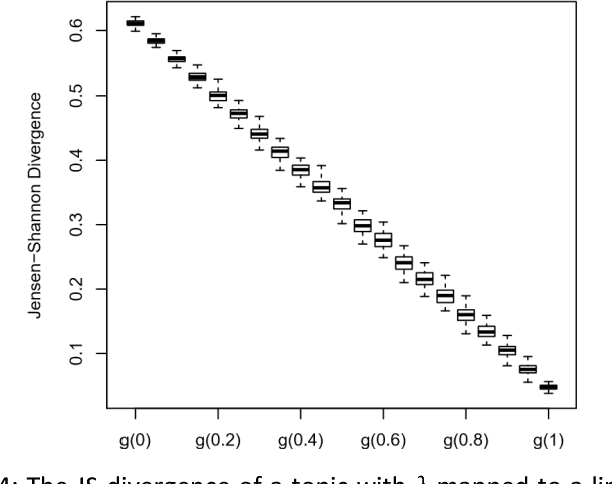
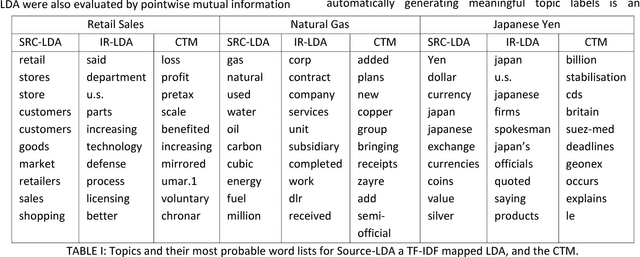
A popular approach to topic modeling involves extracting co-occurring n-grams of a corpus into semantic themes. The set of n-grams in a theme represents an underlying topic, but most topic modeling approaches are not able to label these sets of words with a single n-gram. Such labels are useful for topic identification in summarization systems. This paper introduces a novel approach to labeling a group of n-grams comprising an individual topic. The approach taken is to complement the existing topic distributions over words with a known distribution based on a predefined set of topics. This is done by integrating existing labeled knowledge sources representing known potential topics into the probabilistic topic model. These knowledge sources are translated into a distribution and used to set the hyperparameters of the Dirichlet generated distribution over words. In the inference these modified distributions guide the convergence of the latent topics to conform with the complementary distributions. This approach ensures that the topic inference process is consistent with existing knowledge. The label assignment from the complementary knowledge sources are then transferred to the latent topics of the corpus. The results show both accurate label assignment to topics as well as improved topic generation than those obtained using various labeling approaches based off Latent Dirichlet allocation (LDA).