 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspective Flow Aggregation for Data-Limited 6D Object Pose Estimation
Mar 18, 2022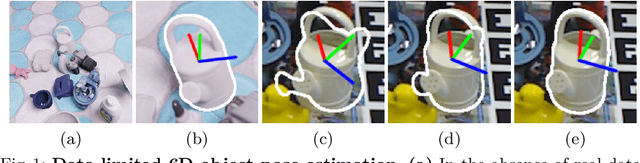

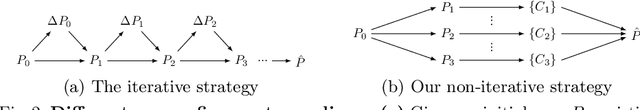
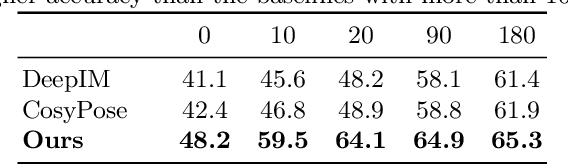
Most recent 6D object pose estimation methods, including unsupervised ones, require many real training images. Unfortunately, for some applications, such as those in space or deep under water, acquiring real images, even unannotated, is virtually impossible. In this paper, we propose a method that can be trained solely on synthetic images, or optionally using a few additional real ones. Given a rough pose estimate obtained from a first network, it uses a second network to predict a dense 2D correspondence field between the image rendered using the rough pose and the real image and infers the required pose correction. This approach is much less sensitive to the domain shift between synthetic and real images than state-of-the-art methods. It performs on par with methods that require annotated real images for training when not using any, and outperforms them considerably when using as few as twenty real images.
Overcoming the Domain Gap in Neural Action Representations
Dec 23, 2021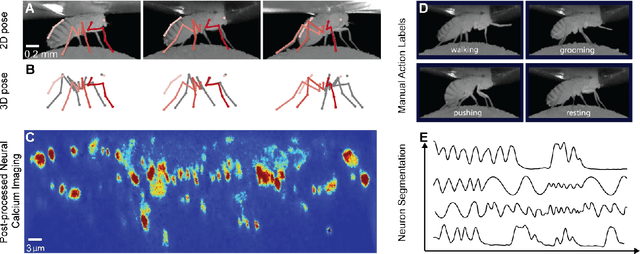
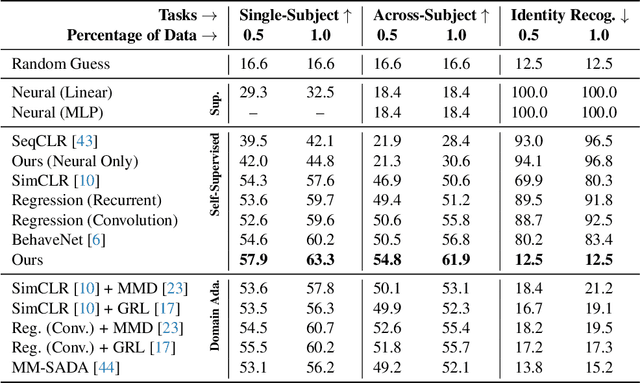
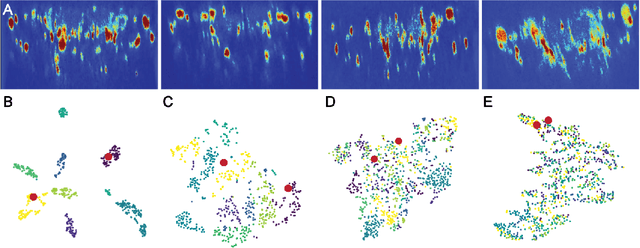
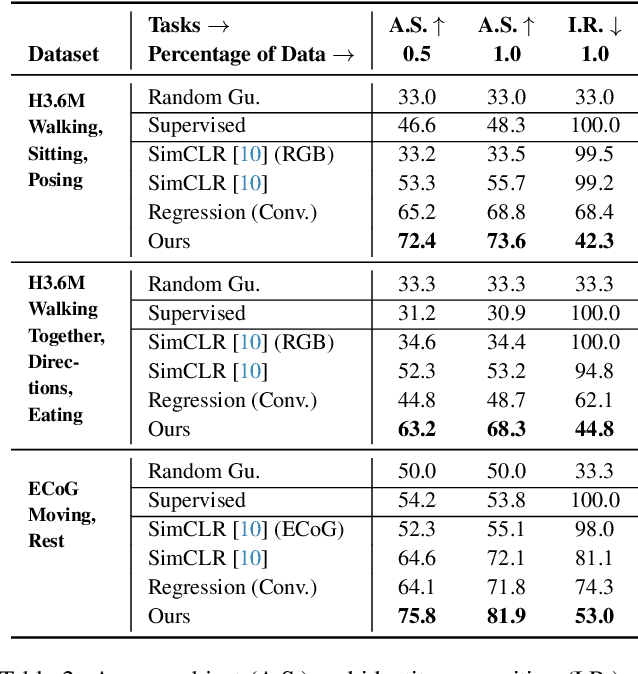
Relating animal behaviors to brain activity is a fundamental goal in neuroscience, with practical applications in building robust brain-machine interfaces. However, the domain gap between individuals is a major issue that prevents the training of general models that work on unlabeled subjects. Since 3D pose data can now be reliably extracted from multi-view video sequences without manual intervention, we propose to use it to guide the encoding of neural action representations together with a set of neural and behavioral augmentations exploiting the properties of microscopy imaging. To reduce the domain gap, during training, we swap neural and behavioral data across animals that seem to be performing similar actions. To demonstrate this, we test our methods on three very different multimodal datasets; one that features flies and their neural activity, one that contains human neural Electrocorticography (ECoG) data, and lastly the RGB video data of human activities from different viewpoints.
Adversarial Parametric Pose Prior
Dec 08, 2021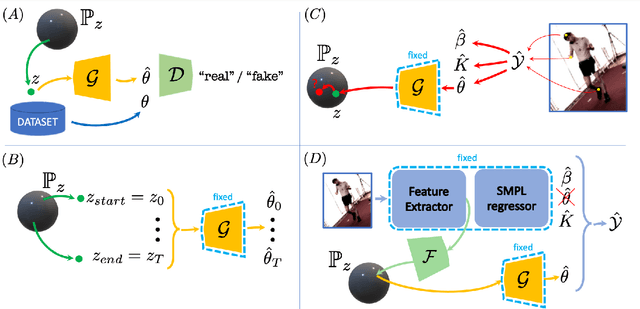
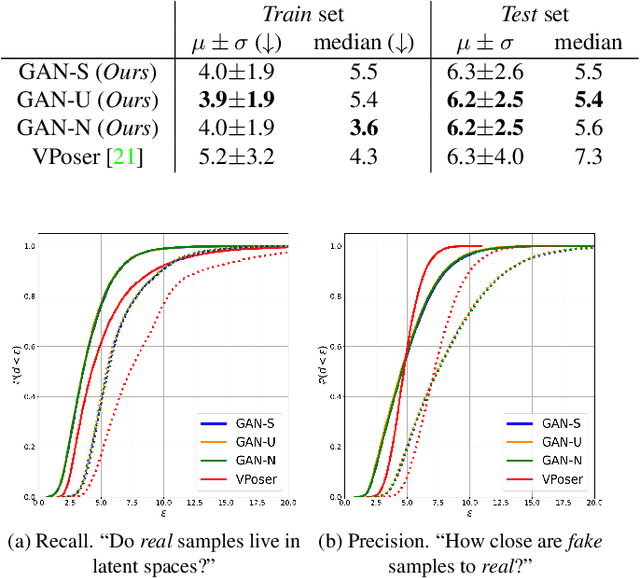
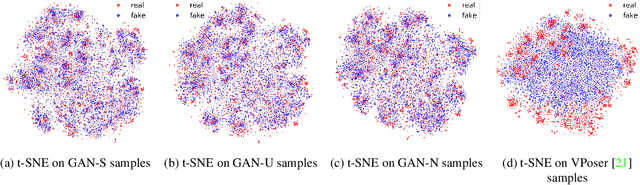
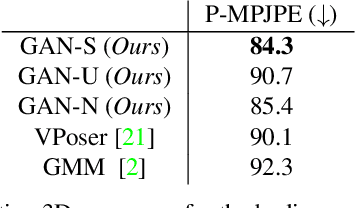
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.
Adjusting the Ground Truth Annotations for Connectivity-Based Learning to Delineate
Dec 06, 2021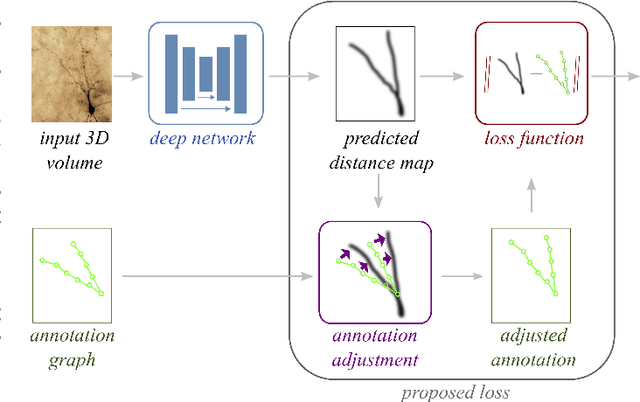
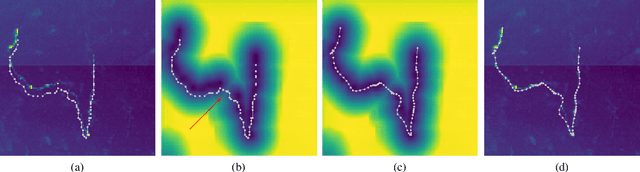
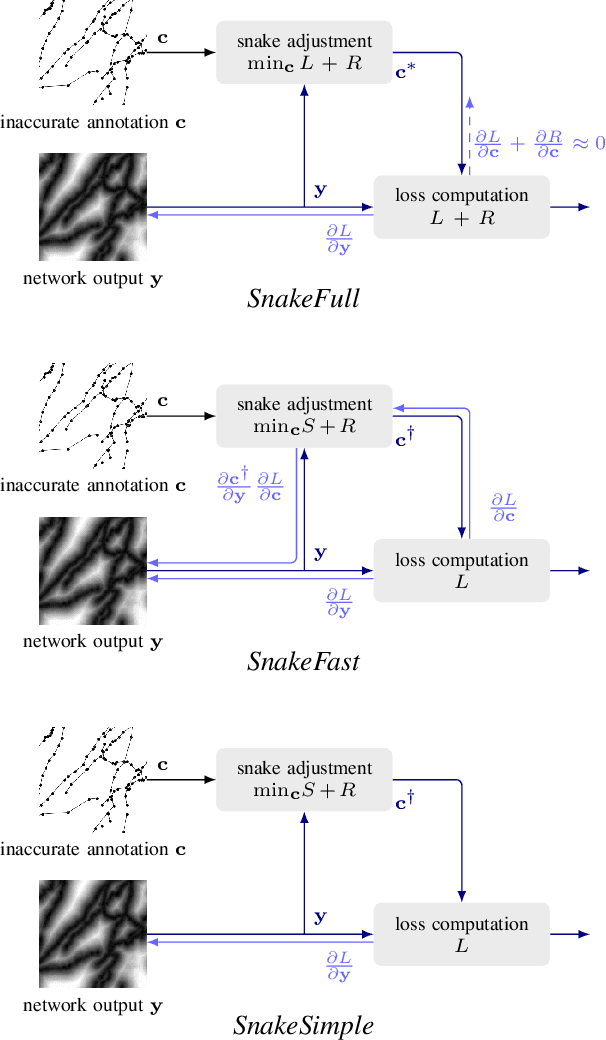

Deep learning-based approaches to delineating 3D structure depend on accurate annotations to train the networks. Yet, in practice, people, no matter how conscientious, have trouble precisely delineating in 3D and on a large scale, in part because the data is often hard to interpret visually and in part because the 3D interfaces are awkward to use. In this paper, we introduce a method that explicitly accounts for annotation inaccuracies. To this end, we treat the annotations as active contour models that can deform themselves while preserving their topology. This enables us to jointly train the network and correct potential errors in the original annotations. The result is an approach that boosts performance of deep networks trained with potentially inaccurate annotations.
Dyadic Human Motion Prediction
Dec 01, 2021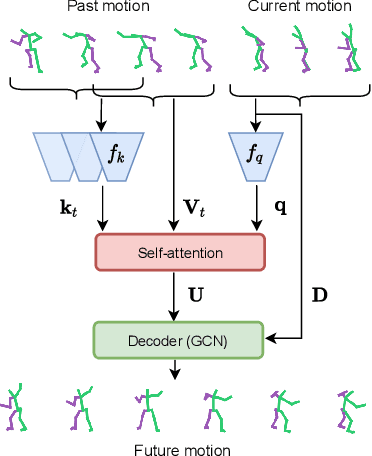
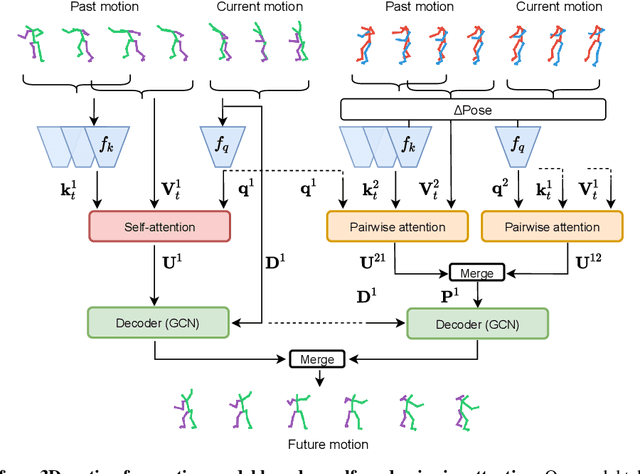

Prior work on human motion forecasting has mostly focused on predicting the future motion of single subjects in isolation from their past pose sequence. In the presence of closely interacting people, however, this strategy fails to account for the dependencies between the different subject's motions. In this paper, we therefore introduce a motion prediction framework that explicitly reasons about the interactions of two observed subjects. Specifically, we achieve this by introducing a pairwise attention mechanism that models the mutual dependencies in the motion history of the two subjects. This allows us to preserve the long-term motion dynamics in a more realistic way and more robustly predict unusual and fast-paced movements, such as the ones occurring in a dance scenario. To evaluate this, and because no existing motion prediction datasets depict two closely-interacting subjects, we introduce the LindyHop600K dance dataset. Our results evidence that our approach outperforms the state-of-the-art single person motion prediction techniques.
Overcoming the Domain Gap in Contrastive Learning of Neural Action Representations
Nov 29, 2021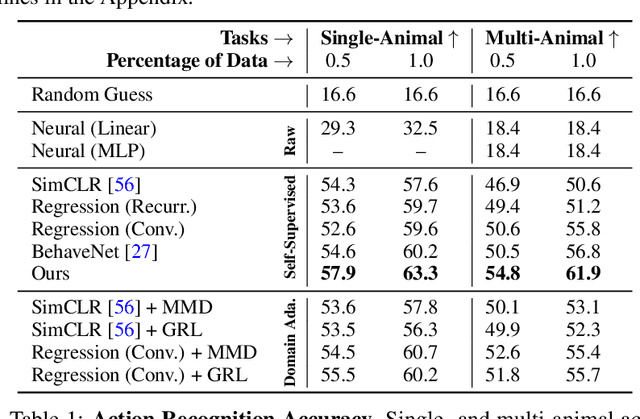
A fundamental goal in neuroscience is to understand the relationship between neural activity and behavior. For example, the ability to extract behavioral intentions from neural data, or neural decoding, is critical for developing effective brain machine interfaces. Although simple linear models have been applied to this challenge, they cannot identify important non-linear relationships. Thus, a self-supervised means of identifying non-linear relationships between neural dynamics and behavior, in order to compute neural representations, remains an important open problem. To address this challenge, we generated a new multimodal dataset consisting of the spontaneous behaviors generated by fruit flies, Drosophila melanogaster -- a popular model organism in neuroscience research. The dataset includes 3D markerless motion capture data from six camera views of the animal generating spontaneous actions, as well as synchronously acquired two-photon microscope images capturing the activity of descending neuron populations that are thought to drive actions. Standard contrastive learning and unsupervised domain adaptation techniques struggle to learn neural action representations (embeddings computed from the neural data describing action labels) due to large inter-animal differences in both neural and behavioral modalities. To overcome this deficiency, we developed simple yet effective augmentations that close the inter-animal domain gap, allowing us to extract behaviorally relevant, yet domain agnostic, information from neural data. This multimodal dataset and our new set of augmentations promise to accelerate the application of self-supervised learning methods in neuroscience.
MeshUDF: Fast and Differentiable Meshing of Unsigned Distance Field Networks
Nov 29, 2021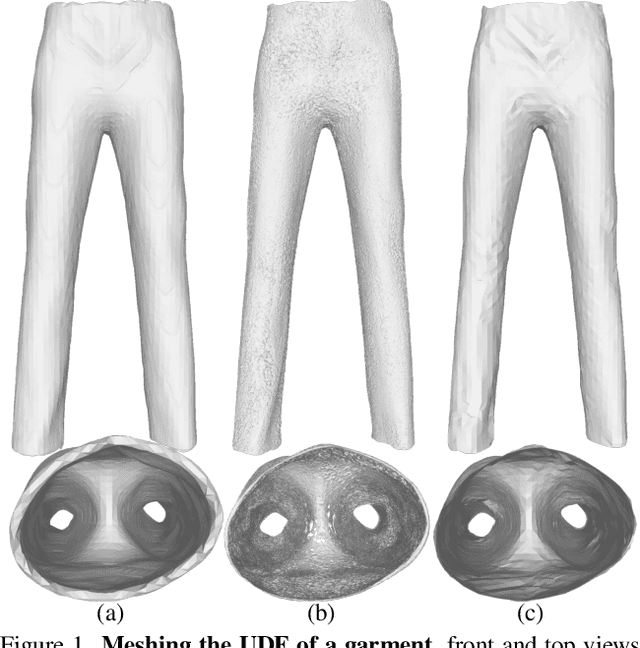
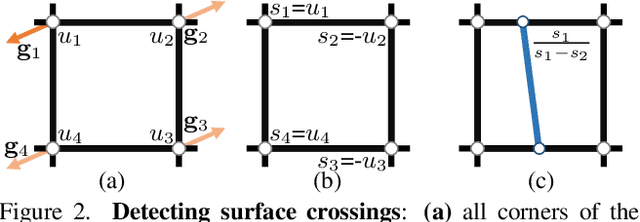
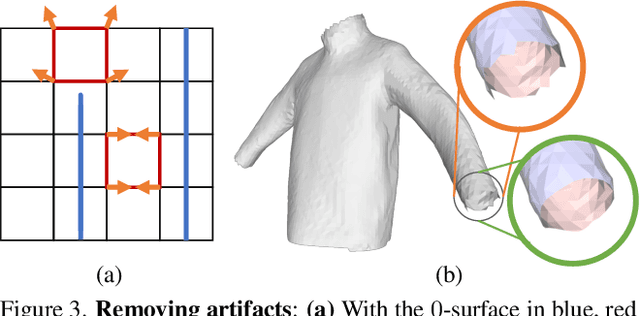

Recent work modelling 3D open surfaces train deep neural networks to approximate Unsigned Distance Fields (UDFs) and implicitly represent shapes. To convert this representation to an explicit mesh, they either use computationally expensive methods to mesh a dense point cloud sampling of the surface, or distort the surface by inflating it into a Signed Distance Field (SDF). By contrast, we propose to directly mesh deep UDFs as open surfaces with an extension of marching cubes, by locally detecting surface crossings. Our method is order of magnitude faster than meshing a dense point cloud, and more accurate than inflating open surfaces. Moreover, we make our surface extraction differentiable, and show it can help fit sparse supervision signals.
Learning to Align Sequential Actions in the Wild
Nov 17, 2021
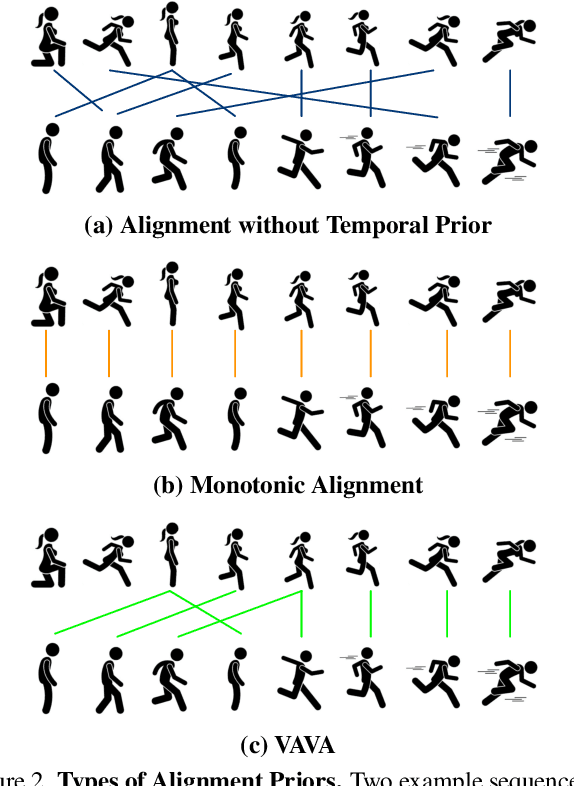
State-of-the-art methods for self-supervised sequential action alignment rely on deep networks that find correspondences across videos in time. They either learn frame-to-frame mapping across sequences, which does not leverage temporal information, or assume monotonic alignment between each video pair, which ignores variations in the order of actions. As such, these methods are not able to deal with common real-world scenarios that involve background frames or videos that contain non-monotonic sequence of actions. In this paper, we propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we propose an approach to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the state-of-the-art in self-supervised sequential action representation learning on four different benchmark datasets.
Temporally-Consistent Surface Reconstruction using Metrically-Consistent Atlases
Nov 12, 2021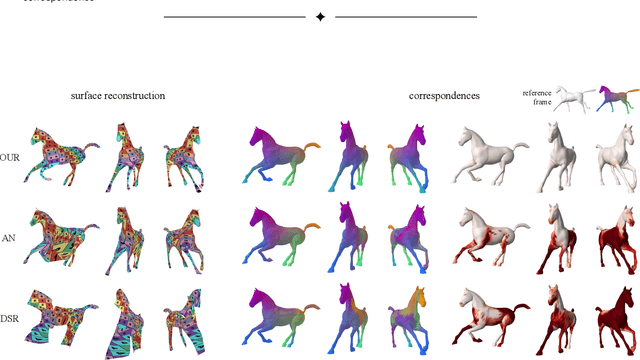
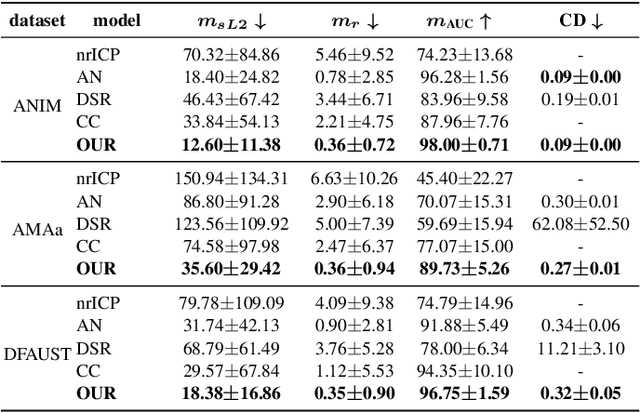
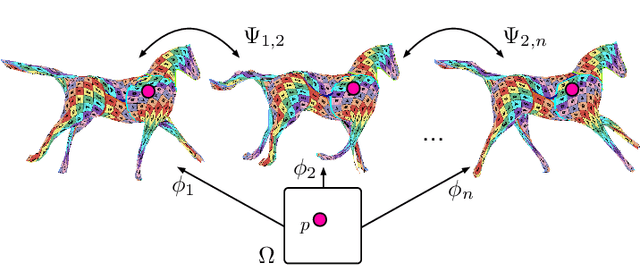
We propose a method for unsupervised reconstruction of a temporally-consistent sequence of surfaces from a sequence of time-evolving point clouds. It yields dense and semantically meaningful correspondences between frames. We represent the reconstructed surfaces as atlases computed by a neural network, which enables us to establish correspondences between frames. The key to making these correspondences semantically meaningful is to guarantee that the metric tensors computed at corresponding points are as similar as possible. We have devised an optimization strategy that makes our method robust to noise and global motions, without a priori correspondences or pre-alignment steps. As a result, our approach outperforms state-of-the-art ones on several challenging datasets. The code is available at https://github.com/bednarikjan/temporally_coherent_surface_reconstruction.
3D Reconstruction of Curvilinear Structures with Stereo Matching DeepConvolutional Neural Networks
Oct 14, 2021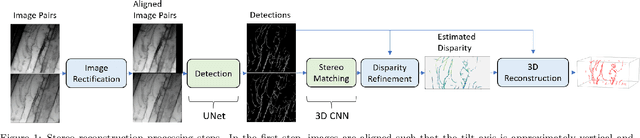

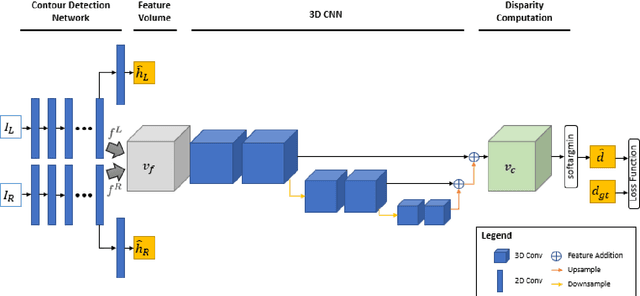
Curvilinear structures frequently appear in microscopy imaging as the object of interest. Crystallographic defects, i.e., dislocations, are one of the curvilinear structures that have been repeatedly investigated under transmission electron microscopy (TEM) and their 3D structural information is of great importance for understanding the properties of materials. 3D information of dislocations is often obtained by tomography which is a cumbersome process since it is required to acquire many images with different tilt angles and similar imaging conditions. Although, alternative stereoscopy methods lower the number of required images to two, they still require human intervention and shape priors for accurate 3D estimation. We propose a fully automated pipeline for both detection and matching of curvilinear structures in stereo pairs by utilizing deep convolutional neural networks (CNNs) without making any prior assumption on 3D shapes. In this work, we mainly focus on 3D reconstruction of dislocations from stereo pairs of TEM images.