 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Simplicial Neural Networks
Jan 09, 2025



Graph Neural Networks (GNNs) excel at learning from graph-structured data but are limited to modeling pairwise interactions, insufficient for capturing higher-order relationships present in many real-world systems. Topological Deep Learning (TDL) has allowed for systematic modeling of hierarchical higher-order interactions by relying on combinatorial topological spaces such as simplicial complexes. In parallel, Quantum Neural Networks (QNNs) have been introduced to leverage quantum mechanics for enhanced computational and learning power. In this work, we present the first Quantum Topological Deep Learning Model: Quantum Simplicial Networks (QSNs), being QNNs operating on simplicial complexes. QSNs are a stack of Quantum Simplicial Layers, which are inspired by the Ising model to encode higher-order structures into quantum states. Experiments on synthetic classification tasks show that QSNs can outperform classical simplicial TDL models in accuracy and efficiency, demonstrating the potential of combining quantum computing with TDL for processing data on combinatorial topological spaces.
Hyperdimensional Computing for ADHD Classification using EEG Signals
Jan 09, 2025



Following the recent interest in applying the Hyperdimensional Computing paradigm in medical context to power up the performance of general machine learning applied to biomedical data, this study represents the first attempt at employing such techniques to solve the problem of classification of Attention Deficit Hyperactivity Disorder using electroencephalogram signals. Making use of a spatio-temporal encoder, and leveraging the properties of HDC, the proposed model achieves an accuracy of 88.9%, outperforming traditional Deep Neural Networks benchmark models. The core of this research is not only to enhance the classification accuracy of the model but also to explore its efficiency in terms of the required training data: a critical finding of the study is the identification of the minimum number of patients needed in the training set to achieve a sufficient level of accuracy. To this end, the accuracy of our model trained with only $7$ of the $79$ patients is comparable to the one from benchmarks trained on the full dataset. This finding underscores the model's efficiency and its potential for quick and precise ADHD diagnosis in medical settings where large datasets are typically unattainable.
Q-SCALE: Quantum computing-based Sensor Calibration for Advanced Learning and Efficiency
Oct 03, 2024In a world burdened by air pollution, the integration of state-of-the-art sensor calibration techniques utilizing Quantum Computing (QC) and Machine Learning (ML) holds promise for enhancing the accuracy and efficiency of air quality monitoring systems in smart cities. This article investigates the process of calibrating inexpensive optical fine-dust sensors through advanced methodologies such as Deep Learning (DL) and Quantum Machine Learning (QML). The objective of the project is to compare four sophisticated algorithms from both the classical and quantum realms to discern their disparities and explore possible alternative approaches to improve the precision and dependability of particulate matter measurements in urban air quality surveillance. Classical Feed-Forward Neural Networks (FFNN) and Long Short-Term Memory (LSTM) models are evaluated against their quantum counterparts: Variational Quantum Regressors (VQR) and Quantum LSTM (QLSTM) circuits. Through meticulous testing, including hyperparameter optimization and cross-validation, the study assesses the potential of quantum models to refine calibration performance. Our analysis shows that: the FFNN model achieved superior calibration accuracy on the test set compared to the VQR model in terms of lower L1 loss function (2.92 vs 4.81); the QLSTM slightly outperformed the LSTM model (loss on the test set: 2.70 vs 2.77), despite using fewer trainable weights (66 vs 482).
From Graphs to Qubits: A Critical Review of Quantum Graph Neural Networks
Aug 12, 2024



Quantum Graph Neural Networks (QGNNs) represent a novel fusion of quantum computing and Graph Neural Networks (GNNs), aimed at overcoming the computational and scalability challenges inherent in classical GNNs that are powerful tools for analyzing data with complex relational structures but suffer from limitations such as high computational complexity and over-smoothing in large-scale applications. Quantum computing, leveraging principles like superposition and entanglement, offers a pathway to enhanced computational capabilities. This paper critically reviews the state-of-the-art in QGNNs, exploring various architectures. We discuss their applications across diverse fields such as high-energy physics, molecular chemistry, finance and earth sciences, highlighting the potential for quantum advantage. Additionally, we address the significant challenges faced by QGNNs, including noise, decoherence, and scalability issues, proposing potential strategies to mitigate these problems. This comprehensive review aims to provide a foundational understanding of QGNNs, fostering further research and development in this promising interdisciplinary field.
An Explainable Fast Deep Neural Network for Emotion Recognition
Jul 20, 2024In the context of artificial intelligence, the inherent human attribute of engaging in logical reasoning to facilitate decision-making is mirrored by the concept of explainability, which pertains to the ability of a model to provide a clear and interpretable account of how it arrived at a particular outcome. This study explores explainability techniques for binary deep neural architectures in the framework of emotion classification through video analysis. We investigate the optimization of input features to binary classifiers for emotion recognition, with face landmarks detection using an improved version of the Integrated Gradients explainability method. The main contribution of this paper consists in the employment of an innovative explainable artificial intelligence algorithm to understand the crucial facial landmarks movements during emotional feeling, using this information also for improving the performances of deep learning-based emotion classifiers. By means of explainability, we can optimize the number and the position of the facial landmarks used as input features for facial emotion recognition, lowering the impact of noisy landmarks and thus increasing the accuracy of the developed models. In order to test the effectiveness of the proposed approach, we considered a set of deep binary models for emotion classification trained initially with a complete set of facial landmarks, which are progressively reduced based on a suitable optimization procedure. The obtained results prove the robustness of the proposed explainable approach in terms of understanding the relevance of the different facial points for the different emotions, also improving the classification accuracy and diminishing the computational cost.
Quasi-Chaotic Oscillators Based on Modular Quantum Circuits
Mar 26, 2022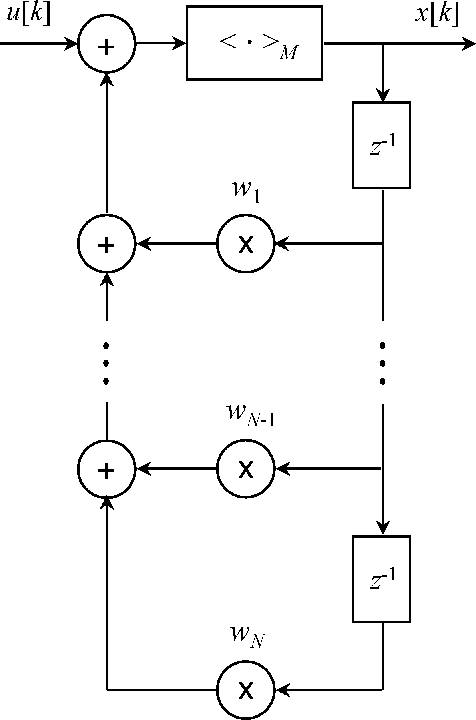
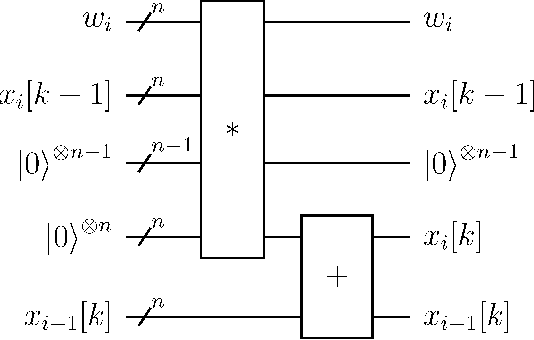
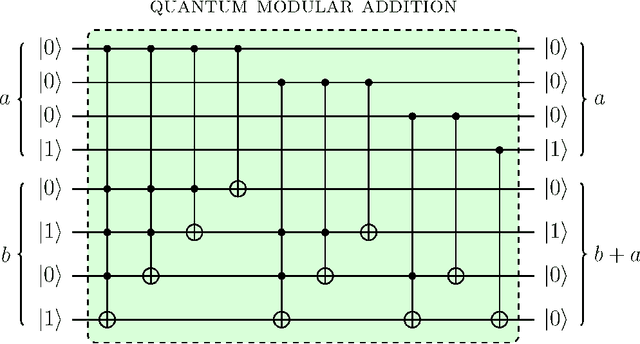
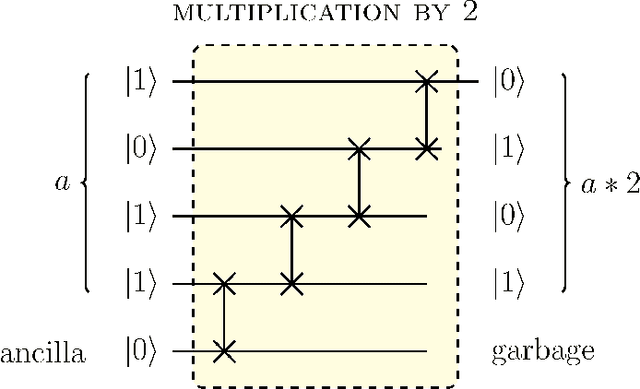
Digital circuits based on residue number systems have been considered to produce a pseudo-random behavior. The present work is an initial step towards the complete implementation of those systems for similar applications using quantum technology. We propose the implementation of a quasi-chaotic oscillator based on quantum modular addition and multiplication and we prove that quantum computing allows the parallel processing of data, paving the way for a fast and robust multi-channel encryption/decryption scheme. The resulting structure is assessed by several experiments in order to ascertain the desired noise-like behavior.
On Effects of Compression with Hyperdimensional Computing in Distributed Randomized Neural Networks
Jun 17, 2021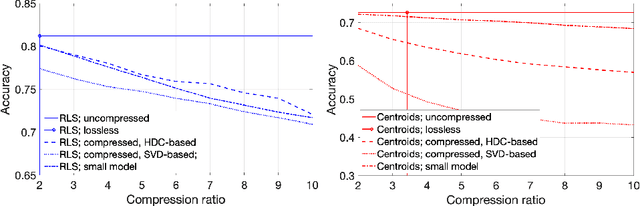
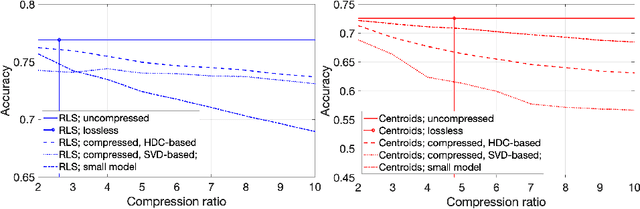
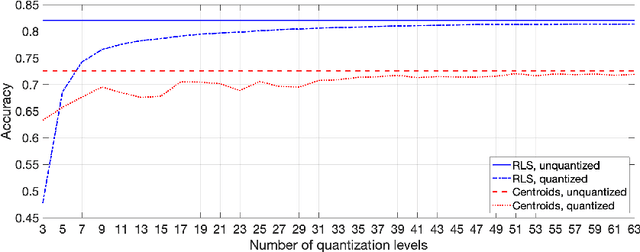
A change of the prevalent supervised learning techniques is foreseeable in the near future: from the complex, computational expensive algorithms to more flexible and elementary training ones. The strong revitalization of randomized algorithms can be framed in this prospect steering. We recently proposed a model for distributed classification based on randomized neural networks and hyperdimensional computing, which takes into account cost of information exchange between agents using compression. The use of compression is important as it addresses the issues related to the communication bottleneck, however, the original approach is rigid in the way the compression is used. Therefore, in this work, we propose a more flexible approach to compression and compare it to conventional compression algorithms, dimensionality reduction, and quantization techniques.
Hyperdimensional Computing for Efficient Distributed Classification with Randomized Neural Networks
Jun 02, 2021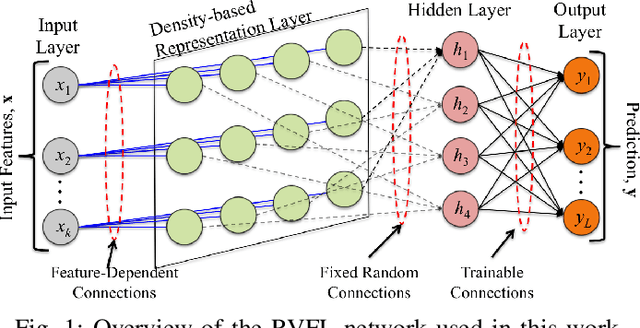
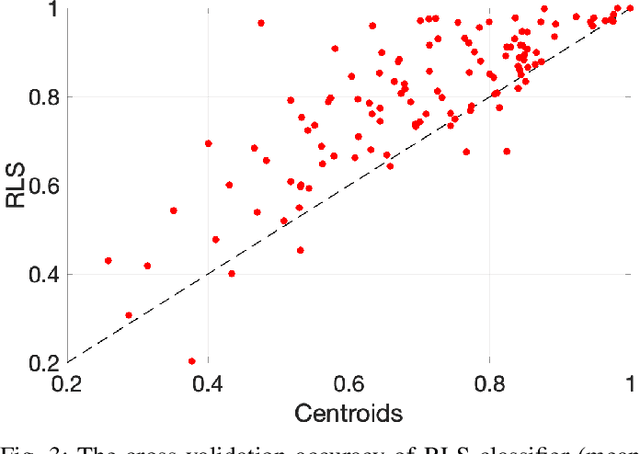
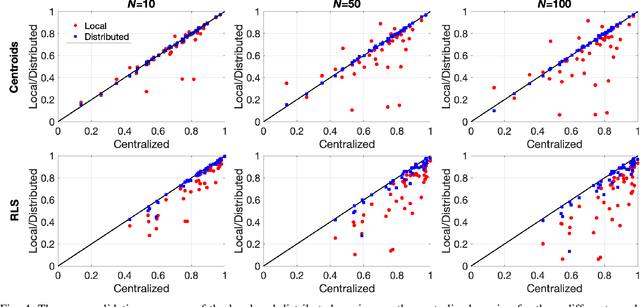
In the supervised learning domain, considering the recent prevalence of algorithms with high computational cost, the attention is steering towards simpler, lighter, and less computationally extensive training and inference approaches. In particular, randomized algorithms are currently having a resurgence, given their generalized elementary approach. By using randomized neural networks, we study distributed classification, which can be employed in situations were data cannot be stored at a central location nor shared. We propose a more efficient solution for distributed classification by making use of a lossy compression approach applied when sharing the local classifiers with other agents. This approach originates from the framework of hyperdimensional computing, and is adapted herein. The results of experiments on a collection of datasets demonstrate that the proposed approach has usually higher accuracy than local classifiers and getting close to the benchmark - the centralized classifier. This work can be considered as the first step towards analyzing the variegated horizon of distributed randomized neural networks.
Perceptron Theory for Predicting the Accuracy of Neural Networks
Dec 14, 2020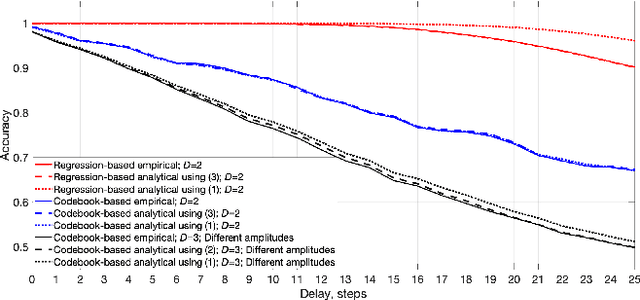
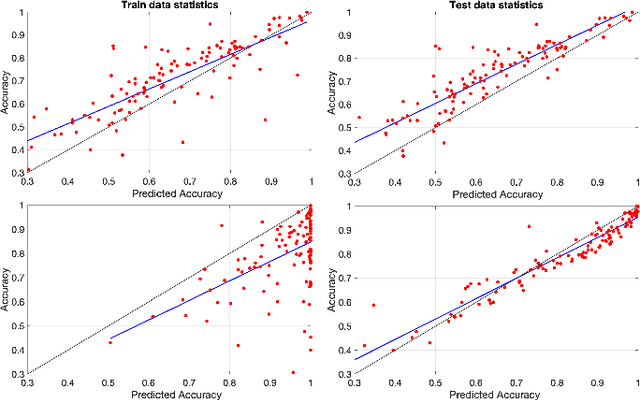
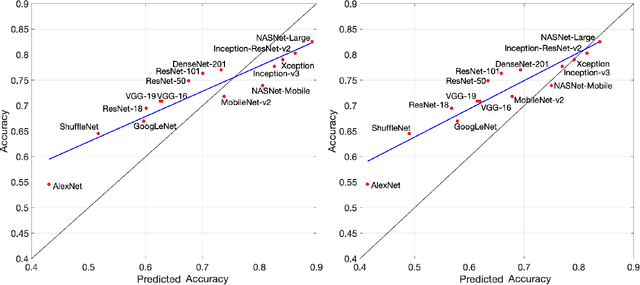
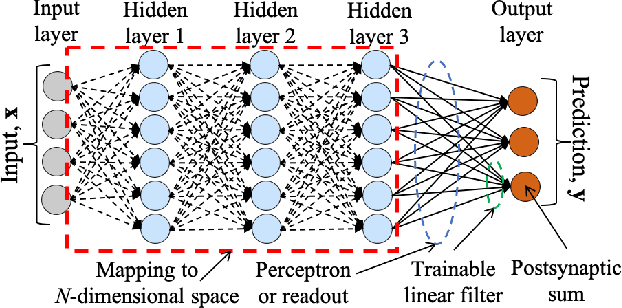
Many neural network models have been successful at classification problems, but their operation is still treated as a black box. Here, we developed a theory for one-layer perceptrons that can predict performance on classification tasks. This theory is a generalization of an existing theory for predicting the performance of Echo State Networks and connectionist models for symbolic reasoning known as Vector Symbolic Architectures. In this paper, we first show that the proposed perceptron theory can predict the performance of Echo State Networks, which could not be described by the previous theory. Second, we apply our perceptron theory to the last layers of shallow randomly connected and deep multi-layer networks. The full theory is based on Gaussian statistics, but it is analytically intractable. We explore numerical methods to predict network performance for problems with a small number of classes. For problems with a large number of classes, we investigate stochastic sampling methods and a tractable approximation to the full theory. The quality of predictions is assessed in three experimental settings, using reservoir computing networks on a memorization task, shallow randomly connected networks on a collection of classification datasets, and deep convolutional networks with the ImageNet dataset. This study offers a simple, bipartite approach to understand deep neural networks: the input is encoded by the last-but-one layers into a high-dimensional representation. This representation is mapped through the weights of the last layer into the postsynaptic sums of the output neurons. Specifically, the proposed perceptron theory uses the mean vector and covariance matrix of the postsynaptic sums to compute classification accuracies for the different classes. The first two moments of the distribution of the postsynaptic sums can predict the overall network performance quite accurately.