 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Learners: Adapting Reinforcement Learning Agents to be Competitive in a Card Game
Apr 08, 2020
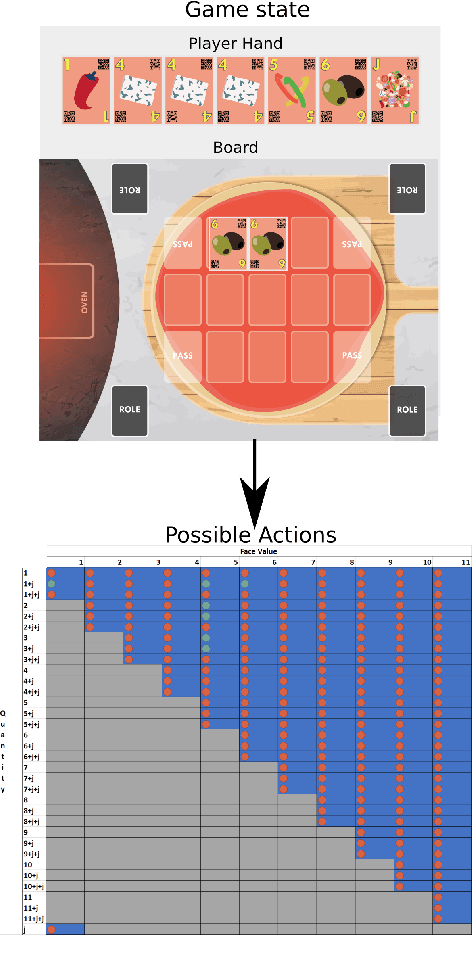
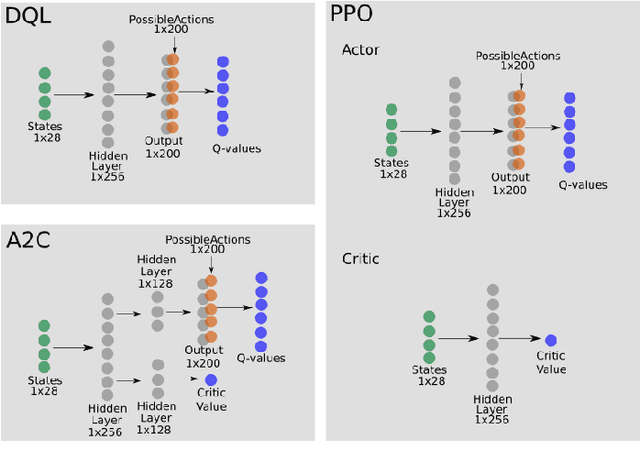
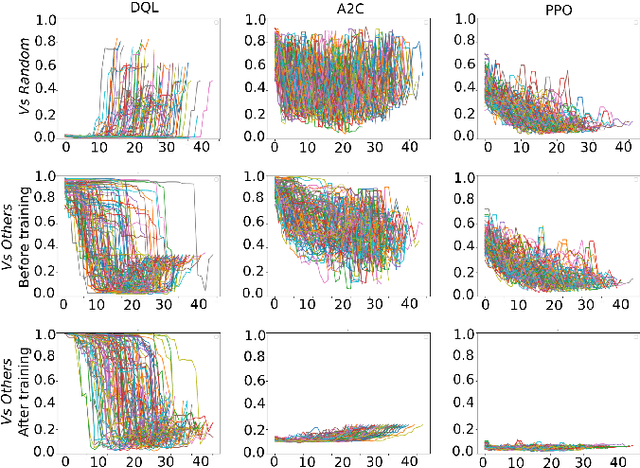
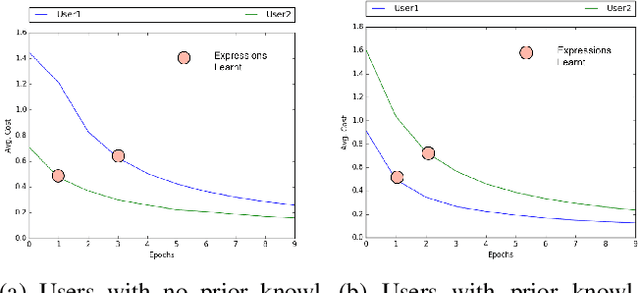
Learning how to adapt to complex and dynamic environments is one of the most important factors that contribute to our intelligence. Endowing artificial agents with this ability is not a simple task, particularly in competitive scenarios. In this paper, we present a broad study on how popular reinforcement learning algorithms can be adapted and implemented to learn and to play a real-world implementation of a competitive multiplayer card game. We propose specific training and validation routines for the learning agents, in order to evaluate how the agents learn to be competitive and explain how they adapt to each others' playing style. Finally, we pinpoint how the behavior of each agent derives from their learning style and create a baseline for future research on this scenario.
iCub: Learning Emotion Expressions using Human Reward
Mar 30, 2020

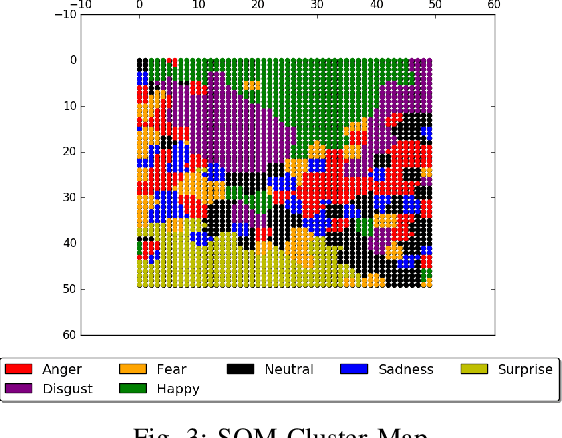
The purpose of the present study is to learn emotion expression representations for artificial agents using reward shaping mechanisms. The approach takes inspiration from the TAMER framework for training a Multilayer Perceptron (MLP) to learn to express different emotions on the iCub robot in a human-robot interaction scenario. The robot uses a combination of a Convolutional Neural Network (CNN) and a Self-Organising Map (SOM) to recognise an emotion and then learns to express the same using the MLP. The objective is to teach a robot to respond adequately to the user's perception of emotions and learn how to express different emotions.
The Chef's Hat Simulation Environment for Reinforcement-Learning-Based Agents
Mar 12, 2020

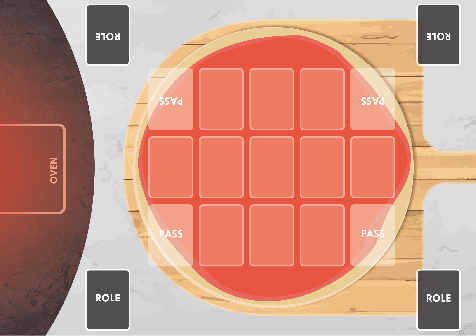
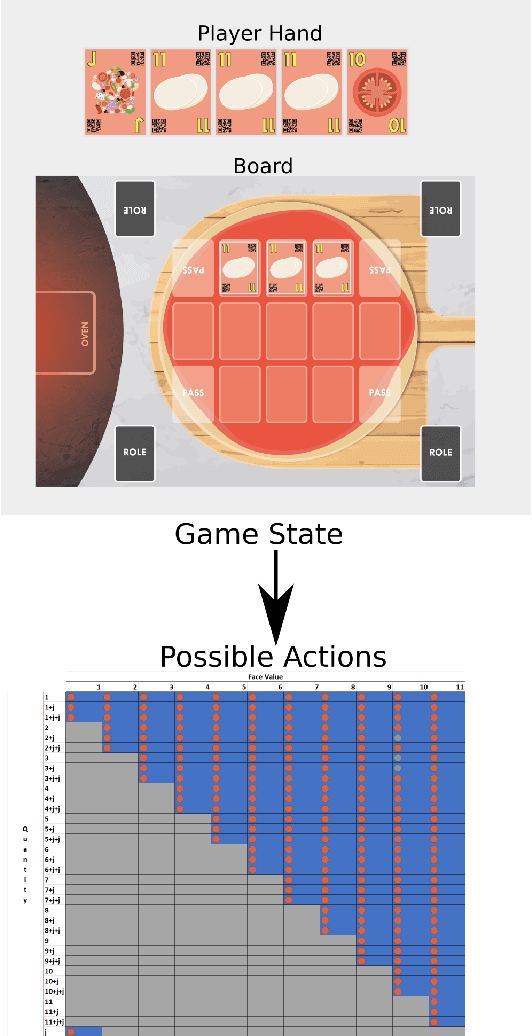
To achieve social interactions within Human-Robot Interaction (HRI) environments is a very challenging task. Most of the current research focuses on Wizard-of-Oz approaches, which neglect the recent development of intelligent robots. On the other hand, real-world scenarios usually do not provide the necessary control and reproducibility which are needed for learning algorithms. In this paper, we propose a virtual simulation environment that implements the Chef's Hat card game, designed to be used in HRI scenarios, to provide a controllable and reproducible scenario for reinforcement-learning algorithms.
What can computational models learn from human selective attention? A review from an audiovisual crossmodal perspective
Sep 05, 2019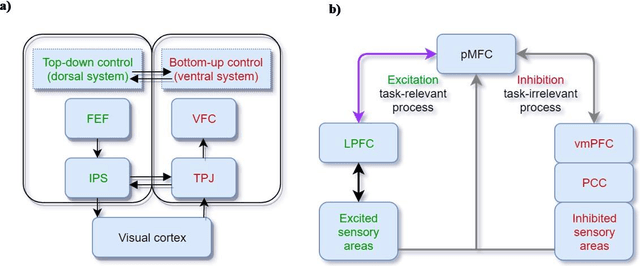

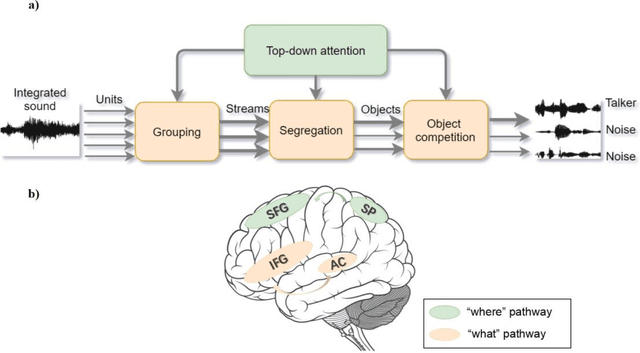
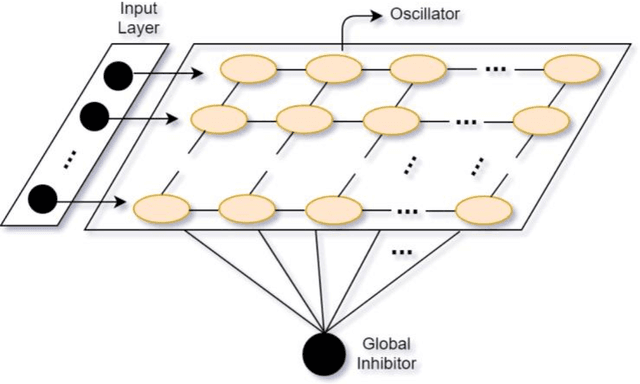
Selective attention plays an essential role in information acquisition and utilization from the environment. In the past 50 years, research on selective attention has been a central topic in cognitive science. Compared with unimodal studies, crossmodal studies are more complex but necessary to solve real-world challenges in both human experiments and computational modeling. Although an increasing number of findings on crossmodal selective attention have shed light on humans' behavioral patterns and neural underpinnings, a much better understanding is still necessary to yield the same benefit for computational intelligent agents. This article reviews studies of selective attention in unimodal visual and auditory and crossmodal audiovisual setups from the multidisciplinary perspectives of psychology and cognitive neuroscience, and evaluates different ways to simulate analogous mechanisms in computational models and robotics. We discuss the gaps between these fields in this interdisciplinary review and provide insights about how to use psychological findings and theories in artificial intelligence from different perspectives.
The OMG-Empathy Dataset: Evaluating the Impact of Affective Behavior in Storytelling
Aug 30, 2019
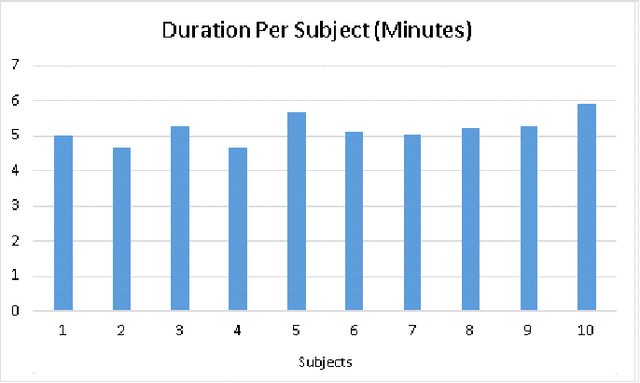
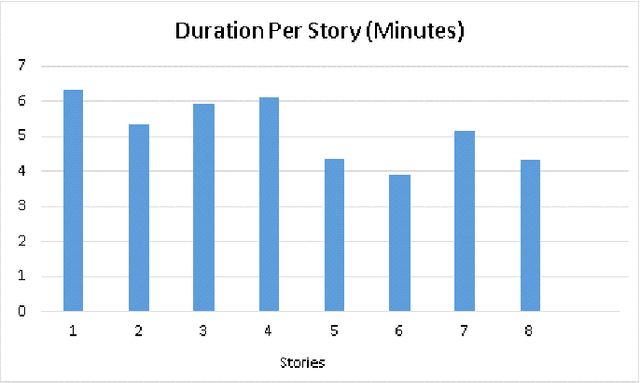
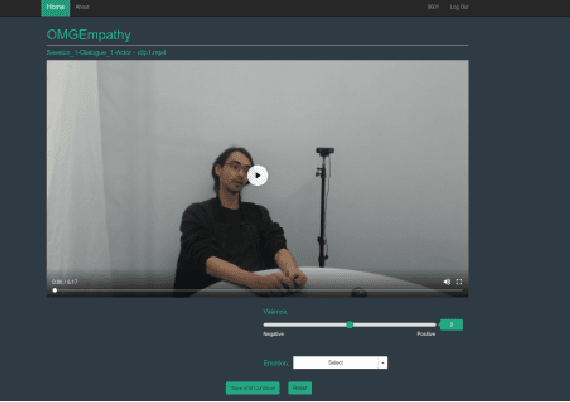
Processing human affective behavior is important for developing intelligent agents that interact with humans in complex interaction scenarios. A large number of current approaches that address this problem focus on classifying emotion expressions by grouping them into known categories. Such strategies neglect, among other aspects, the impact of the affective responses from an individual on their interaction partner thus ignoring how people empathize towards each other. This is also reflected in the datasets used to train models for affective processing tasks. Most of the recent datasets, in particular, the ones which capture natural interactions ("in-the-wild" datasets), are designed, collected, and annotated based on the recognition of displayed affective reactions, ignoring how these displayed or expressed emotions are perceived. In this paper, we propose a novel dataset composed of dyadic interactions designed, collected and annotated with a focus on measuring the affective impact that eight different stories have on the listener. Each video of the dataset contains around 5 minutes of interaction where a speaker tells a story to a listener. After each interaction, the listener annotated, using a valence scale, how the story impacted their affective state, reflecting how they empathized with the speaker as well as the story. We also propose different evaluation protocols and a baseline that encourages participation in the advancement of the field of artificial empathy and emotion contagion.
Towards Learning How to Properly Play UNO with the iCub Robot
Aug 02, 2019
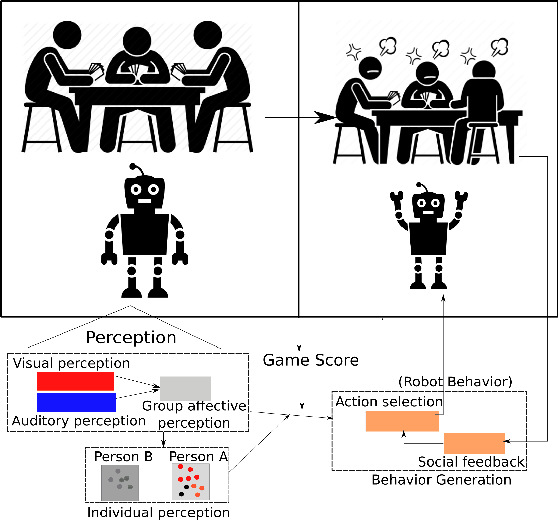
While interacting with another person, our reactions and behavior are much affected by the emotional changes within the temporal context of the interaction. Our intrinsic affective appraisal comprising perception, self-assessment, and the affective memories with similar social experiences will drive specific, and in most cases addressed as proper, reactions within the interaction. This paper proposes the roadmap for the development of multimodal research which aims to empower a robot with the capability to provide proper social responses in a Human-Robot Interaction (HRI) scenario.
A Personalized Affective Memory Neural Model for Improving Emotion Recognition
Apr 23, 2019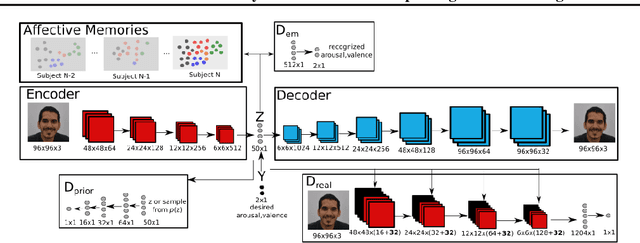

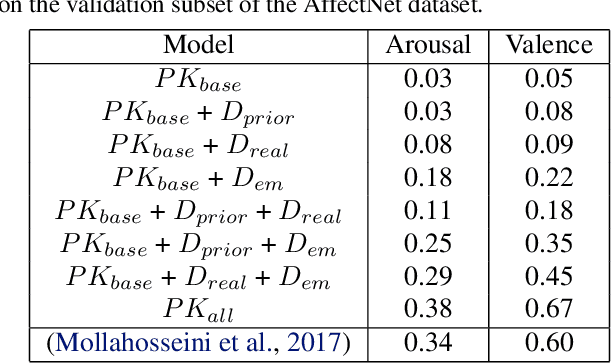
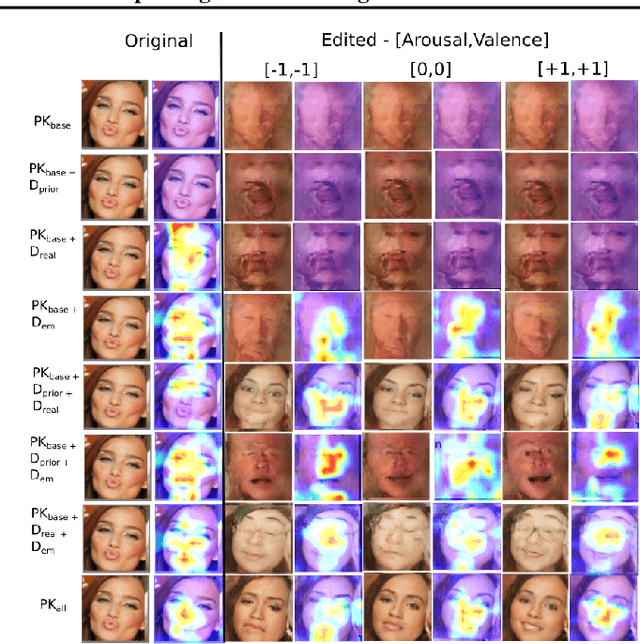
Recent models of emotion recognition strongly rely on supervised deep learning solutions for the distinction of general emotion expressions. However, they are not reliable when recognizing online and personalized facial expressions, e.g., for person-specific affective understanding. In this paper, we present a neural model based on a conditional adversarial autoencoder to learn how to represent and edit general emotion expressions. We then propose Grow-When-Required networks as personalized affective memories to learn individualized aspects of emotion expressions. Our model achieves state-of-the-art performance on emotion recognition when evaluated on \textit{in-the-wild} datasets. Furthermore, our experiments include ablation studies and neural visualizations in order to explain the behavior of our model.
Assessing the Contribution of Semantic Congruency to Multisensory Integration and Conflict Resolution
Oct 15, 2018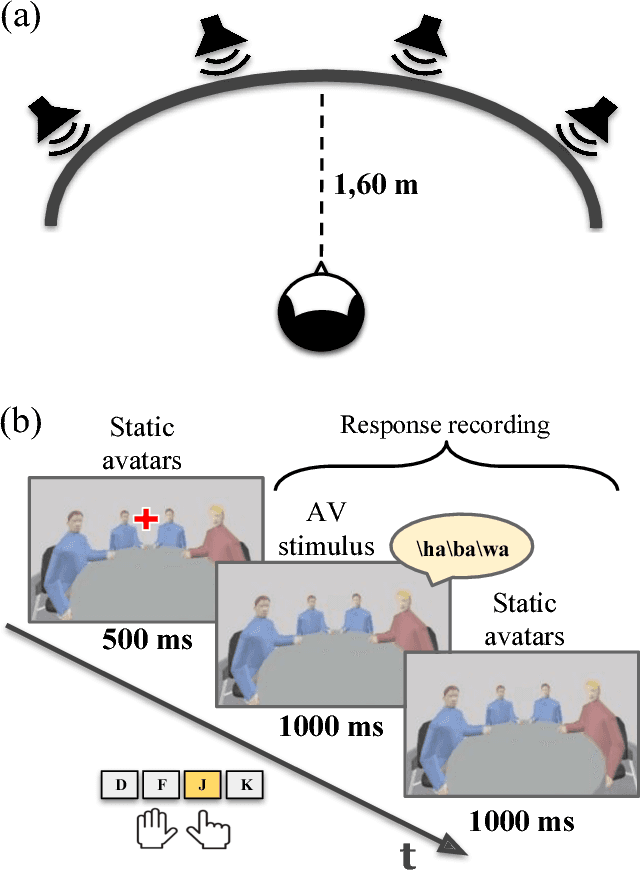
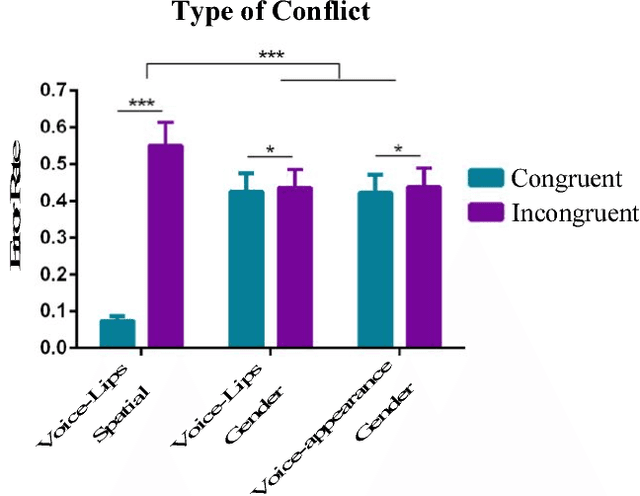
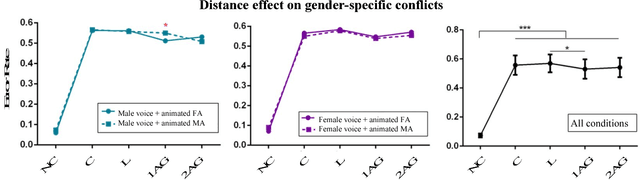
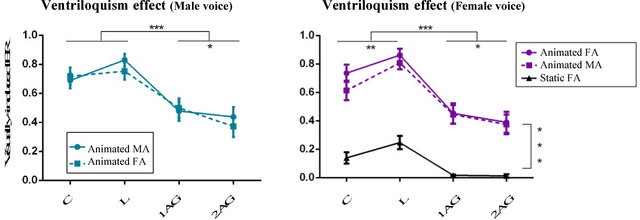
The efficient integration of multisensory observations is a key property of the brain that yields the robust interaction with the environment. However, artificial multisensory perception remains an open issue especially in situations of sensory uncertainty and conflicts. In this work, we extend previous studies on audio-visual (AV) conflict resolution in complex environments. In particular, we focus on quantitatively assessing the contribution of semantic congruency during an AV spatial localization task. In addition to conflicts in the spatial domain (i.e. spatially misaligned stimuli), we consider gender-specific conflicts with male and female avatars. Our results suggest that while semantically related stimuli affect the magnitude of the visual bias (perceptually shifting the location of the sound towards a semantically congruent visual cue), humans still strongly rely on environmental statistics to solve AV conflicts. Together with previously reported results, this work contributes to a better understanding of how multisensory integration and conflict resolution can be modelled in artificial agents and robots operating in real-world environments.
A Neurorobotic Experiment for Crossmodal Conflict Resolution in Complex Environments
Sep 24, 2018
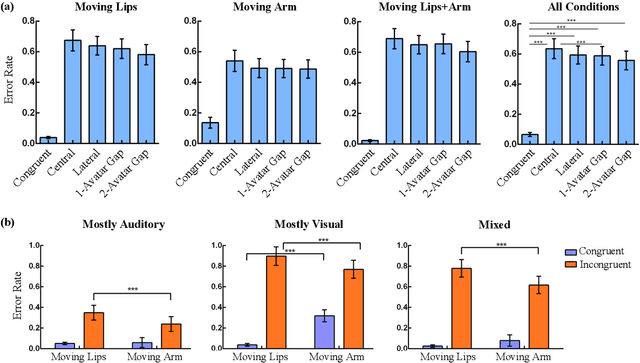
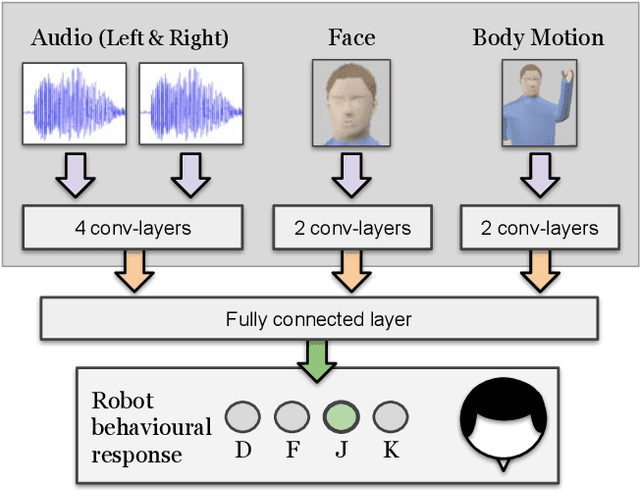
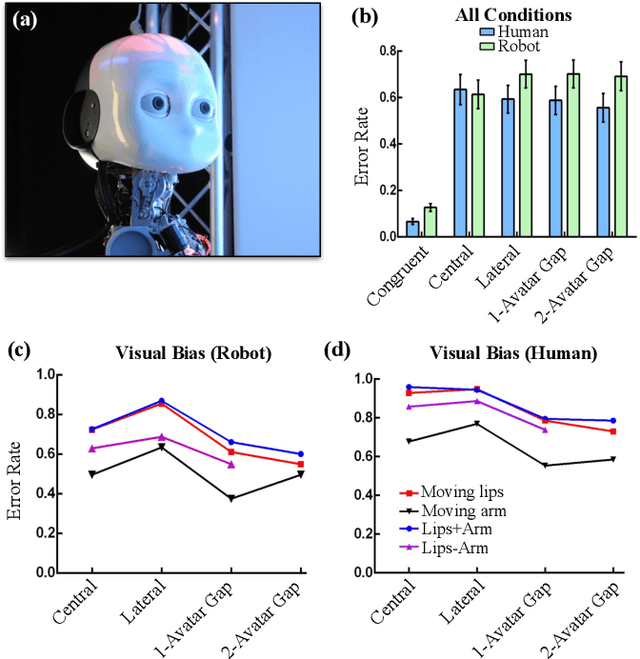
Crossmodal conflict resolution is crucial for robot sensorimotor coupling through the interaction with the environment, yielding swift and robust behaviour also in noisy conditions. In this paper, we propose a neurorobotic experiment in which an iCub robot exhibits human-like responses in a complex crossmodal environment. To better understand how humans deal with multisensory conflicts, we conducted a behavioural study exposing 33 subjects to congruent and incongruent dynamic audio-visual cues. In contrast to previous studies using simplified stimuli, we designed a scenario with four animated avatars and observed that the magnitude and extension of the visual bias are related to the semantics embedded in the scene, i.e., visual cues that are congruent with environmental statistics (moving lips and vocalization) induce the strongest bias. We implement a deep learning model that processes stereophonic sound, facial features, and body motion to trigger a discrete behavioural response. After training the model, we exposed the iCub to the same experimental conditions as the human subjects, showing that the robot can replicate similar responses in real time. Our interdisciplinary work provides important insights into how crossmodal conflict resolution can be modelled in robots and introduces future research directions for the efficient combination of sensory observations with internally generated knowledge and expectations.
A Deep Neural Model Of Emotion Appraisal
Aug 01, 2018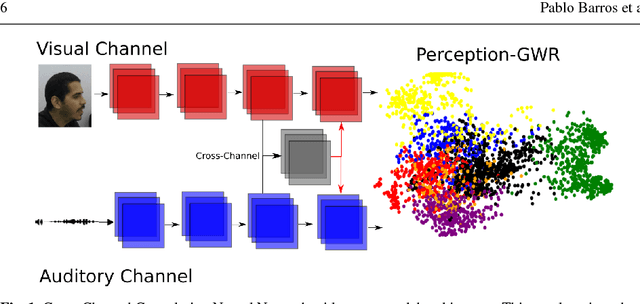
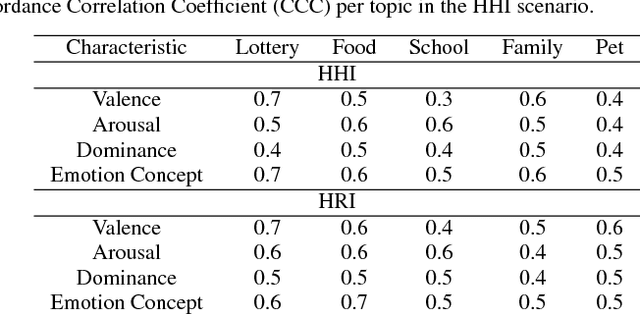
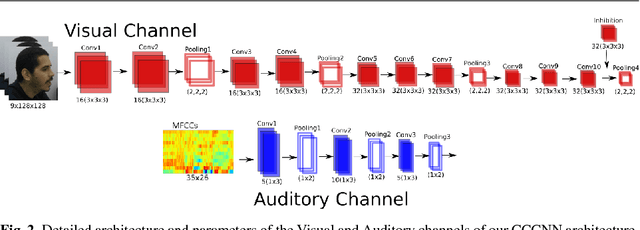
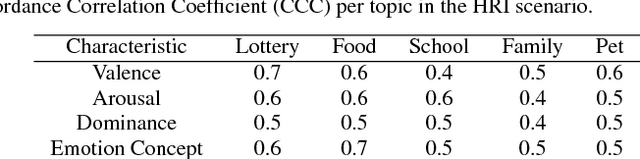
Emotional concepts play a huge role in our daily life since they take part into many cognitive processes: from the perception of the environment around us to different learning processes and natural communication. Social robots need to communicate with humans, which increased also the popularity of affective embodied models that adopt different emotional concepts in many everyday tasks. However, there is still a gap between the development of these solutions and the integration and development of a complex emotion appraisal system, which is much necessary for true social robots. In this paper, we propose a deep neural model which is designed in the light of different aspects of developmental learning of emotional concepts to provide an integrated solution for internal and external emotion appraisal. We evaluate the performance of the proposed model with different challenging corpora and compare it with state-of-the-art models for external emotion appraisal. To extend the evaluation of the proposed model, we designed and collected a novel dataset based on a Human-Robot Interaction (HRI) scenario. We deployed the model in an iCub robot and evaluated the capability of the robot to learn and describe the affective behavior of different persons based on observation. The performed experiments demonstrate that the proposed model is competitive with the state of the art in describing emotion behavior in general. In addition, it is able to generate internal emotional concepts that evolve through time: it continuously forms and updates the formed emotional concepts, which is a step towards creating an emotional appraisal model grounded in the robot experiences.