 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Adversaries with Anti-adversaries in Training
Apr 25, 2023



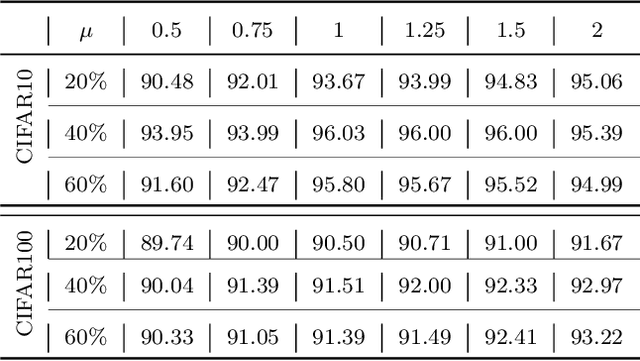
Adversarial training is an effective learning technique to improve the robustness of deep neural networks. In this study, the influence of adversarial training on deep learning models in terms of fairness, robustness, and generalization is theoretically investigated under more general perturbation scope that different samples can have different perturbation directions (the adversarial and anti-adversarial directions) and varied perturbation bounds. Our theoretical explorations suggest that the combination of adversaries and anti-adversaries (samples with anti-adversarial perturbations) in training can be more effective in achieving better fairness between classes and a better tradeoff between robustness and generalization in some typical learning scenarios (e.g., noisy label learning and imbalance learning) compared with standard adversarial training. On the basis of our theoretical findings, a more general learning objective that combines adversaries and anti-adversaries with varied bounds on each training sample is presented. Meta learning is utilized to optimize the combination weights. Experiments on benchmark datasets under different learning scenarios verify our theoretical findings and the effectiveness of the proposed methodology.
* 8 pages, 5 figures
Understanding Difficulty-based Sample Weighting with a Universal Difficulty Measure
Jan 12, 2023Sample weighting is widely used in deep learning. A large number of weighting methods essentially utilize the learning difficulty of training samples to calculate their weights. In this study, this scheme is called difficulty-based weighting. Two important issues arise when explaining this scheme. First, a unified difficulty measure that can be theoretically guaranteed for training samples does not exist. The learning difficulties of the samples are determined by multiple factors including noise level, imbalance degree, margin, and uncertainty. Nevertheless, existing measures only consider a single factor or in part, but not in their entirety. Second, a comprehensive theoretical explanation is lacking with respect to demonstrating why difficulty-based weighting schemes are effective in deep learning. In this study, we theoretically prove that the generalization error of a sample can be used as a universal difficulty measure. Furthermore, we provide formal theoretical justifications on the role of difficulty-based weighting for deep learning, consequently revealing its positive influences on both the optimization dynamics and generalization performance of deep models, which is instructive to existing weighting schemes.
Class-Level Logit Perturbation
Sep 26, 2022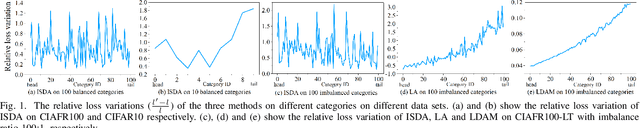

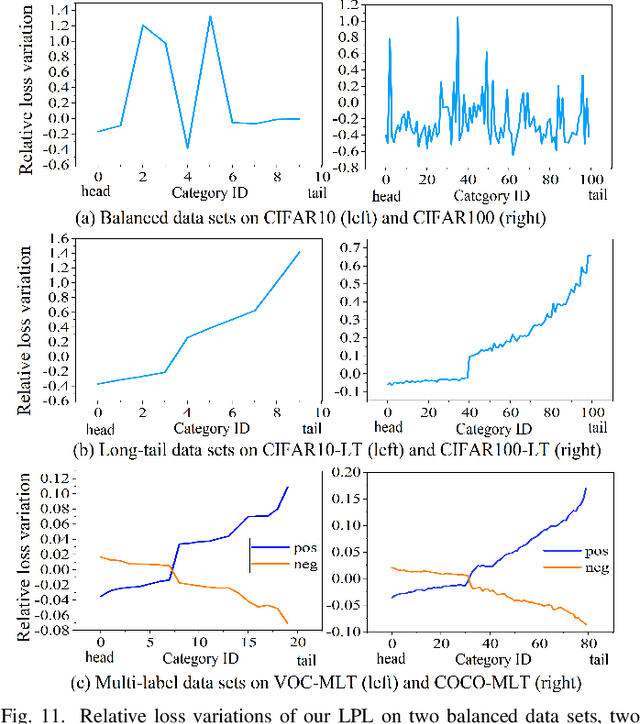
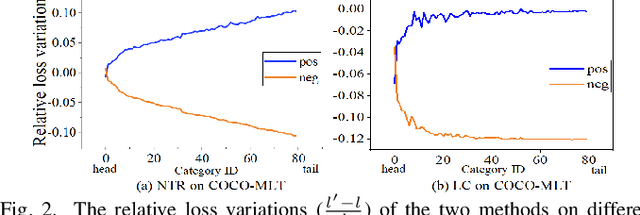
Features, logits, and labels are the three primary data when a sample passes through a deep neural network. Feature perturbation and label perturbation receive increasing attention in recent years. They have been proven to be useful in various deep learning approaches. For example, (adversarial) feature perturbation can improve the robustness or even generalization capability of learned models. However, limited studies have explicitly explored for the perturbation of logit vectors. This work discusses several existing methods related to class-level logit perturbation. A unified viewpoint between positive/negative data augmentation and loss variations incurred by logit perturbation is established. A theoretical analysis is provided to illuminate why class-level logit perturbation is useful. Accordingly, new methodologies are proposed to explicitly learn to perturb logits for both single-label and multi-label classification tasks. Extensive experiments on benchmark image classification data sets and their long-tail versions indicated the competitive performance of our learning method. As it only perturbs on logit, it can be used as a plug-in to fuse with any existing classification algorithms. All the codes are available at https://github.com/limengyang1992/lpl.
Exploring the Learning Difficulty of Data Theory and Measure
May 16, 2022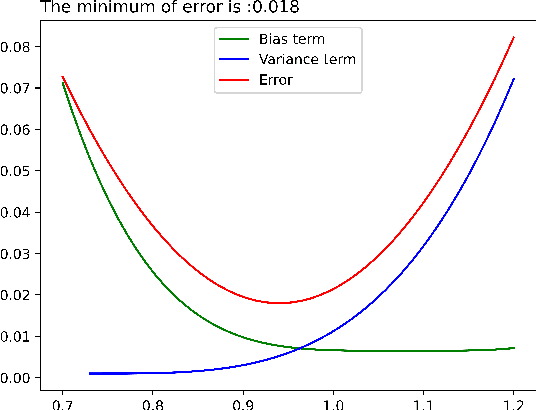


As learning difficulty is crucial for machine learning (e.g., difficulty-based weighting learning strategies), previous literature has proposed a number of learning difficulty measures. However, no comprehensive investigation for learning difficulty is available to date, resulting in that nearly all existing measures are heuristically defined without a rigorous theoretical foundation. In addition, there is no formal definition of easy and hard samples even though they are crucial in many studies. This study attempts to conduct a pilot theoretical study for learning difficulty of samples. First, a theoretical definition of learning difficulty is proposed on the basis of the bias-variance trade-off theory on generalization error. Theoretical definitions of easy and hard samples are established on the basis of the proposed definition. A practical measure of learning difficulty is given as well inspired by the formal definition. Second, the properties for learning difficulty-based weighting strategies are explored. Subsequently, several classical weighting methods in machine learning can be well explained on account of explored properties. Third, the proposed measure is evaluated to verify its reasonability and superiority in terms of several main difficulty factors. The comparison in these experiments indicates that the proposed measure significantly outperforms the other measures throughout the experiments.
Tackling the Imbalance for GNNs
Oct 17, 2021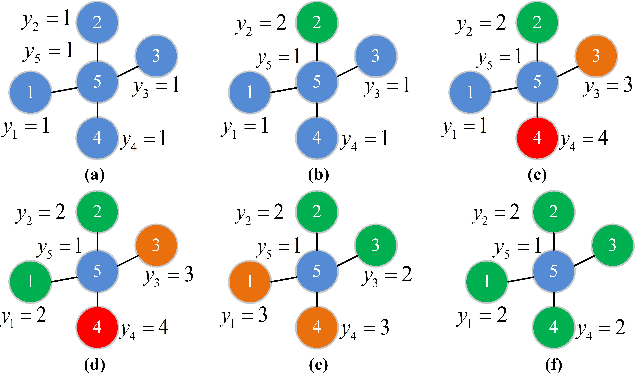
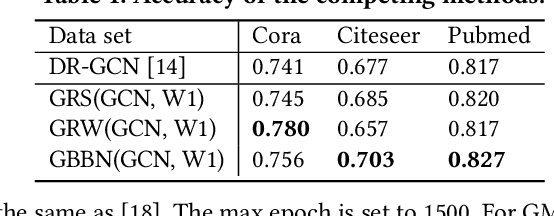
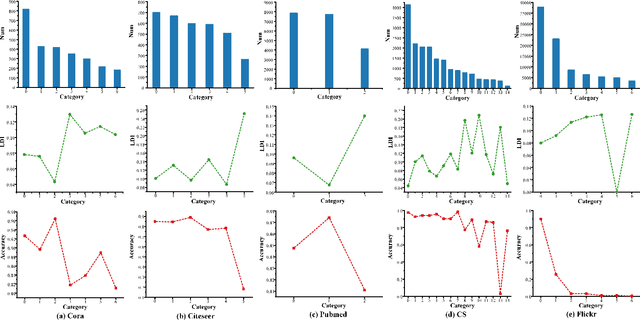
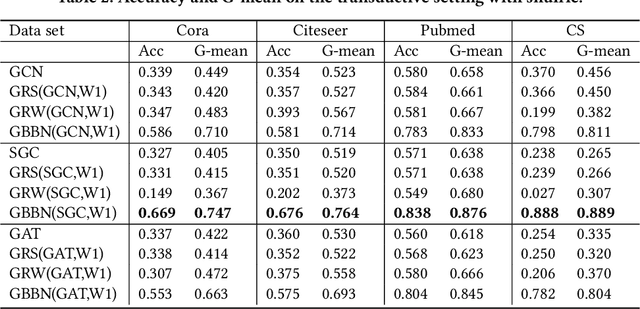
Different from deep neural networks for non-graph data classification, graph neural networks (GNNs) leverage the information exchange between nodes (or samples) when representing nodes. The category distribution shows an imbalance or even a highly-skewed trend on nearly all existing benchmark GNN data sets. The imbalanced distribution will cause misclassification of nodes in the minority classes, and even cause the classification performance on the entire data set to decrease. This study explores the effects of the imbalance problem on the performances of GNNs and proposes new methodologies to solve it. First, a node-level index, namely, the label difference index ($LDI$), is defined to quantitatively analyze the relationship between imbalance and misclassification. The less samples in a class, the higher the value of its average $LDI$; the higher the $LDI$ of a sample, the more likely the sample will be misclassified. We define a new loss and propose four new methods based on $LDI$. Experimental results indicate that the classification accuracies of the three among our proposed four new methods are better in both transductive and inductive settings. The $LDI$ can be applied to other GNNs.
Which Samples Should be Learned First: Easy or Hard?
Oct 14, 2021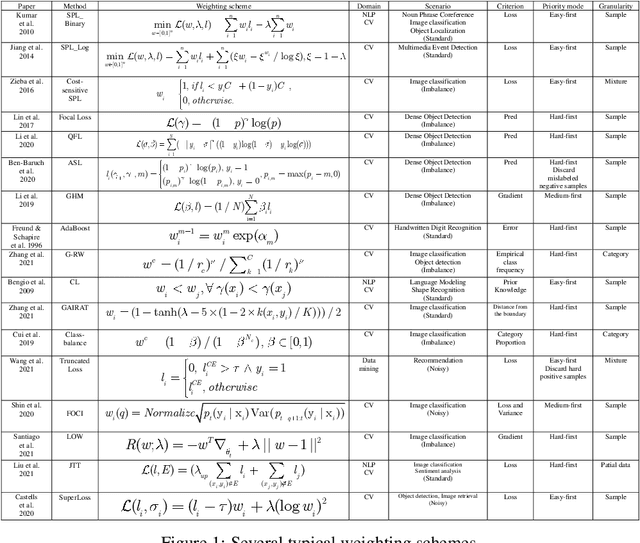
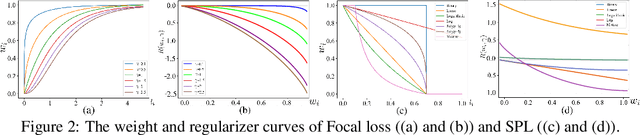
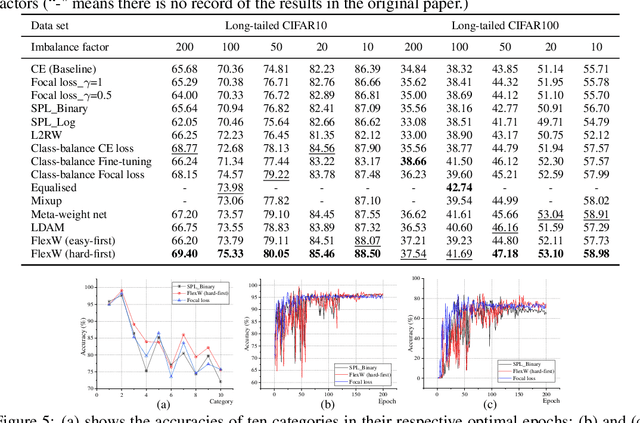
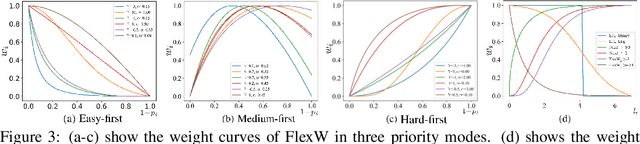
An effective weighting scheme for training samples is essential for learning tasks. Numerous weighting schemes have been proposed. Some schemes take the easy-first mode on samples, whereas some others take the hard-first mode. Naturally, an interesting yet realistic question is raised. Which samples should be learned first given a new learning task, easy or hard? To answer this question, three aspects of research are carried out. First, a high-level unified weighted loss is proposed, providing a more comprehensive view for existing schemes. Theoretical analysis is subsequently conducted and preliminary conclusions are obtained. Second, a flexible weighting scheme is proposed to overcome the defects of existing schemes. The three modes, namely, easy/medium/hard-first, can be flexibly switched in the proposed scheme. Third, a wide range of experiments are conducted to further compare the weighting schemes in different modes. On the basis of these works, reasonable answers are obtained. Factors including prior knowledge and data characteristics determine which samples should be learned first in a learning task.
Compensation Learning
Jul 26, 2021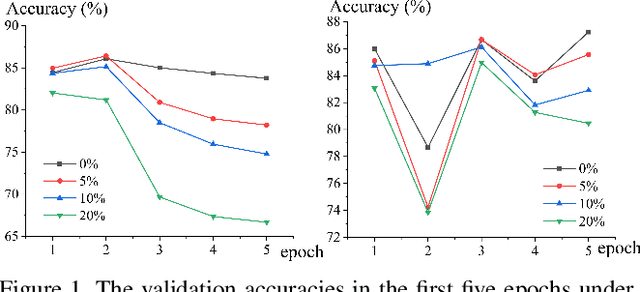
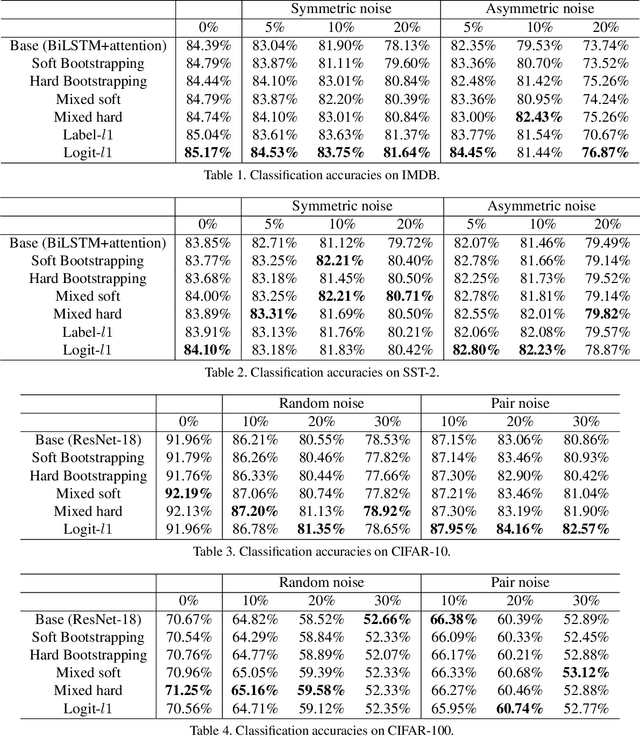
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
A Mathematical Foundation for Robust Machine Learning based on Bias-Variance Trade-off
Jun 22, 2021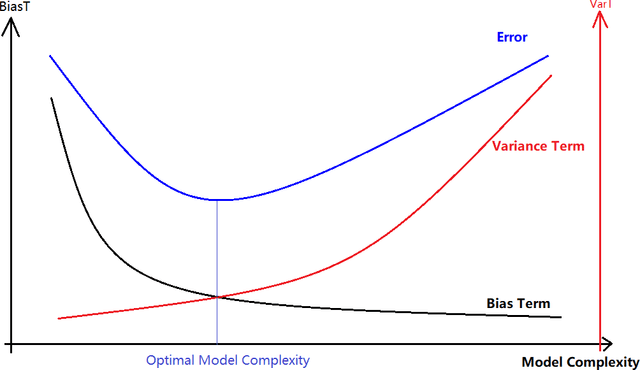
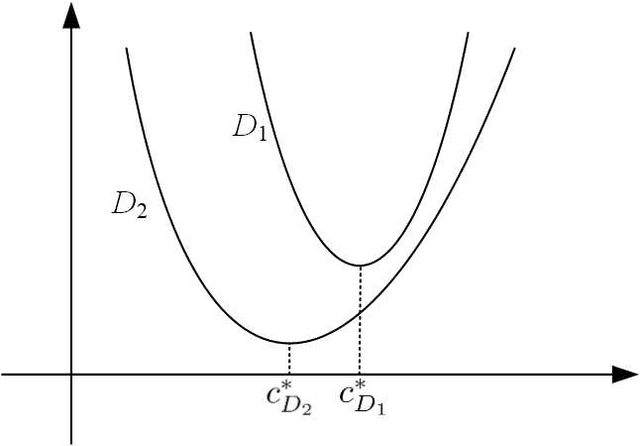
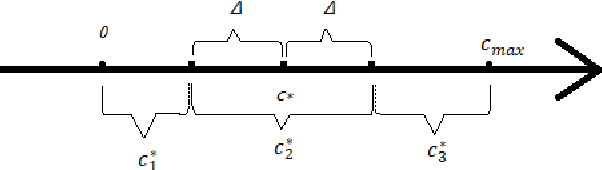

A common assumption in machine learning is that samples are independently and identically distributed (i.i.d). However, the contributions of different samples are not identical in training. Some samples are difficult to learn and some samples are noisy. The unequal contributions of samples has a considerable effect on training performances. Studies focusing on unequal sample contributions (e.g., easy, hard, noisy) in learning usually refer to these contributions as robust machine learning (RML). Weighing and regularization are two common techniques in RML. Numerous learning algorithms have been proposed but the strategies for dealing with easy/hard/noisy samples differ or even contradict with different learning algorithms. For example, some strategies take the hard samples first, whereas some strategies take easy first. Conducting a clear comparison for existing RML algorithms in dealing with different samples is difficult due to lack of a unified theoretical framework for RML. This study attempts to construct a mathematical foundation for RML based on the bias-variance trade-off theory. A series of definitions and properties are presented and proved. Several classical learning algorithms are also explained and compared. Improvements of existing methods are obtained based on the comparison. A unified method that combines two classical learning strategies is proposed.
Improving the Expressive Power of Graph Neural Network with Tinhofer Algorithm
Apr 05, 2021
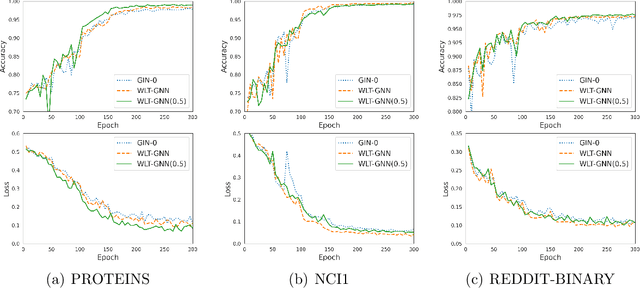

In recent years, Graph Neural Network (GNN) has bloomly progressed for its power in processing graph-based data. Most GNNs follow a message passing scheme, and their expressive power is mathematically limited by the discriminative ability of the Weisfeiler-Lehman (WL) test. Following Tinhofer's research on compact graphs, we propose a variation of the message passing scheme, called the Weisfeiler-Lehman-Tinhofer GNN (WLT-GNN), that theoretically breaks through the limitation of the WL test. In addition, we conduct comparative experiments and ablation studies on several well-known datasets. The results show that the proposed methods have comparable performances and better expressive power on these datasets.
AI Marker-based Large-scale AI Literature Mining
Nov 03, 2020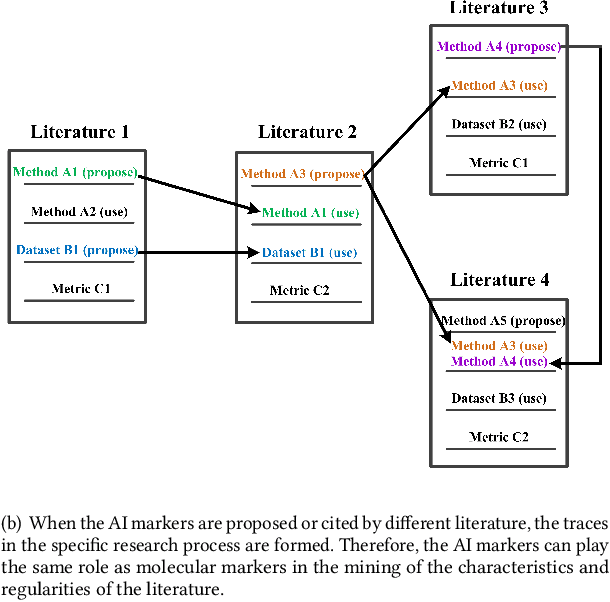

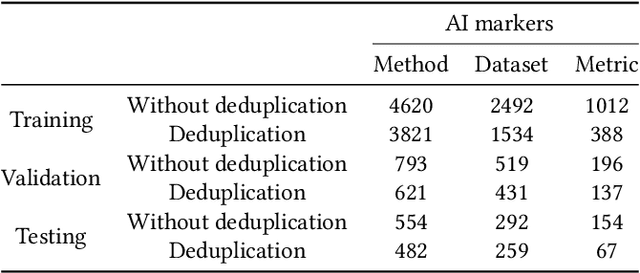
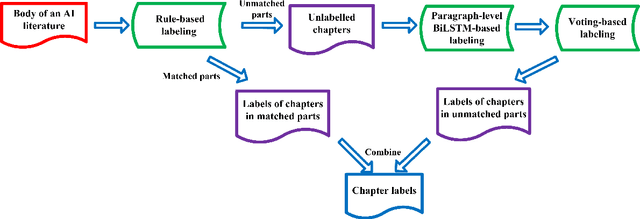
The knowledge contained in academic literature is interesting to mine. Inspired by the idea of molecular markers tracing in the field of biochemistry, three named entities, namely, methods, datasets and metrics are used as AI markers for AI literature. These entities can be used to trace the research process described in the bodies of papers, which opens up new perspectives for seeking and mining more valuable academic information. Firstly, the entity extraction model is used in this study to extract AI markers from large-scale AI literature. Secondly, original papers are traced for AI markers. Statistical and propagation analysis are performed based on tracing results. Finally, the co-occurrences of AI markers are used to achieve clustering. The evolution within method clusters and the influencing relationships amongst different research scene clusters are explored. The above-mentioned mining based on AI markers yields many meaningful discoveries. For example, the propagation of effective methods on the datasets is rapidly increasing with the development of time; effective methods proposed by China in recent years have increasing influence on other countries, whilst France is the opposite. Saliency detection, a classic computer vision research scene, is the least likely to be affected by other research scenes.