 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured 3D Latents Are Surprisingly Powerful: Unleashing Generalizable Style with 2D Diffusion
May 06, 20263D asset generation plays a pivotal role in fields such as gaming and virtual reality, enabling the rapid synthesis of high-fidelity 3D objects from a single or multiple images. Building on this capability, enabling style-controllable generation naturally emerges as an important and desirable direction. However, existing approaches typically rely on style images that lie within or are similar to the training distribution of 3D generation models. When presented with out-of-distribution (OOD) styles, their performance degrades significantly or even fails. To address this limitation, we introduce $\textbf{DiLAST}$: 2D Diffusion-based Latent Awakening for 3D Style Transfer. Specifically, we leverage a pretrained 2D diffusion model as a teacher to provide rich and generalizable style priors. By aligning rendered views with the target style under diffusion-based guidance, our method optimizes the structured 3D latent representation for stylization. We observe that this limitation stems not from insufficient model capacity, but from the underutilization of structured 3D latents, which are inherently expressive. Despite being trained on comparatively limited data, 3D generation models can leverage 2D diffusion guidance to steer denoising toward specific directions in latent space, thereby producing diverse, OOD styles. Extensive experiments across diverse data and multiple 3D generation backbones demonstrate the effectiveness and plug-and-play nature of our approach.
AdvSplat: Adversarial Attacks on Feed-Forward Gaussian Splatting Models
Mar 24, 20263D Gaussian Splatting (3DGS) is increasingly recognized as a powerful paradigm for real-time, high-fidelity 3D reconstruction. However, its per-scene optimization pipeline limits scalability and generalization, and prevents efficient inference. Recently emerged feed-forward 3DGS models address these limitations by enabling fast reconstruction from a few input views after large-scale pretraining, without scene-specific optimization. Despite their advantages and strong potential for commercial deployment, the use of neural networks as the backbone also amplifies the risk of adversarial manipulation. In this paper, we introduce AdvSplat, the first systematic study of adversarial attacks on feed-forward 3DGS. We first employ white-box attacks to reveal fundamental vulnerabilities of this model family. We then develop two improved, practically relevant, query-efficient black-box algorithms that optimize pixel-space perturbations via a frequency-domain parameterization: one based on gradient estimation and the other gradient-free, without requiring any access to model internals. Extensive experiments across multiple datasets demonstrate that AdvSplat can significantly disrupt reconstruction results by injecting imperceptible perturbations into the input images. Our findings surface an overlooked yet urgent problem in this domain, and we hope to draw the community's attention to this emerging security and robustness challenge.
DefenseSplat: Enhancing the Robustness of 3D Gaussian Splatting via Frequency-Aware Filtering
Feb 22, 20263D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for real-time and high-fidelity 3D reconstruction from posed images. However, recent studies reveal its vulnerability to adversarial corruptions in input views, where imperceptible yet consistent perturbations can drastically degrade rendering quality, increase training and rendering time, and inflate memory usage, even leading to server denial-of-service. In our work, to mitigate this issue, we begin by analyzing the distinct behaviors of adversarial perturbations in the low- and high-frequency components of input images using wavelet transforms. Based on this observation, we design a simple yet effective frequency-aware defense strategy that reconstructs training views by filtering high-frequency noise while preserving low-frequency content. This approach effectively suppresses adversarial artifacts while maintaining the authenticity of the original scene. Notably, it does not significantly impair training on clean data, achieving a desirable trade-off between robustness and performance on clean inputs. Through extensive experiments under a wide range of attack intensities on multiple benchmarks, we demonstrate that our method substantially enhances the robustness of 3DGS without access to clean ground-truth supervision. By highlighting and addressing the overlooked vulnerabilities of 3D Gaussian Splatting, our work paves the way for more robust and secure 3D reconstructions.
Method and Dataset Entity Mining in Scientific Literature: A CNN + Bi-LSTM Model with Self-attention
Oct 26, 2020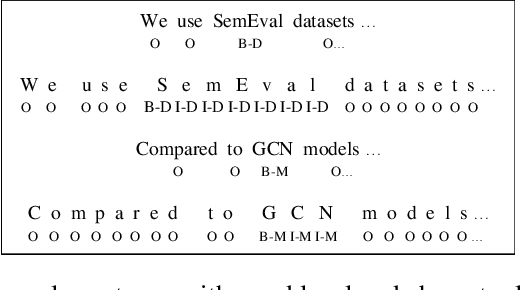
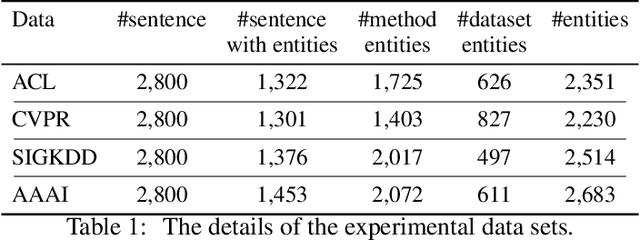
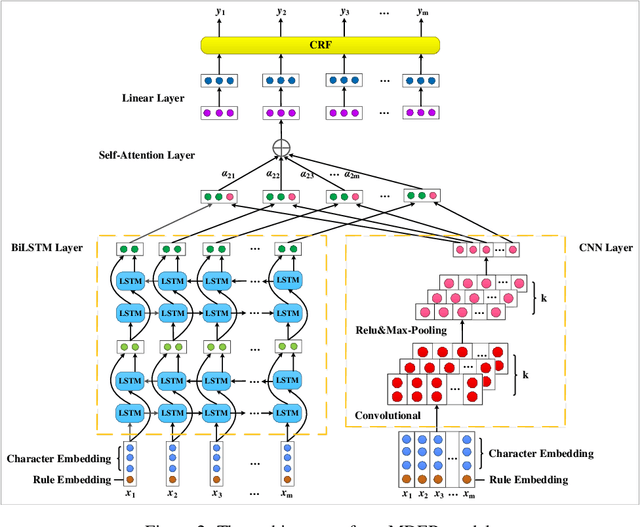
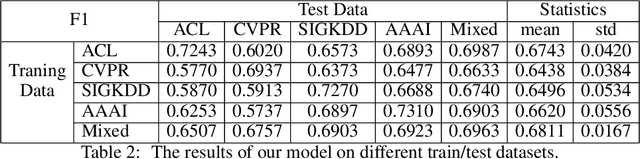
Literature analysis facilitates researchers to acquire a good understanding of the development of science and technology. The traditional literature analysis focuses largely on the literature metadata such as topics, authors, abstracts, keywords, references, etc., and little attention was paid to the main content of papers. In many scientific domains such as science, computing, engineering, etc., the methods and datasets involved in the scientific papers published in those domains carry important information and are quite useful for domain analysis as well as algorithm and dataset recommendation. In this paper, we propose a novel entity recognition model, called MDER, which is able to effectively extract the method and dataset entities from the main textual content of scientific papers. The model utilizes rule embedding and adopts a parallel structure of CNN and Bi-LSTM with the self-attention mechanism. We evaluate the proposed model on datasets which are constructed from the published papers of four research areas in computer science, i.e., NLP, CV, Data Mining and AI. The experimental results demonstrate that our model performs well in all the four areas and it features a good learning capacity for cross-area learning and recognition. We also conduct experiments to evaluate the effectiveness of different building modules within our model which indicate that the importance of different building modules in collectively contributing to the good entity recognition performance as a whole. The data augmentation experiments on our model demonstrated that data augmentation positively contributes to model training, making our model much more robust in dealing with the scenarios where only small number of training samples are available. We finally apply our model on PAKDD papers published from 2009-2019 to mine insightful results from scientific papers published in a longer time span.
AntNet: Deep Answer Understanding Network for Natural Reverse QA
Dec 01, 2019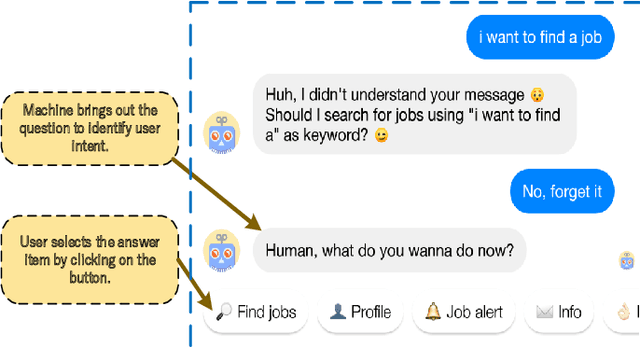
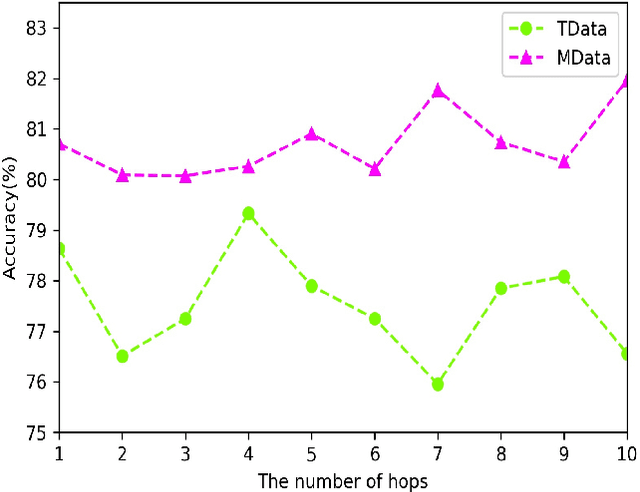
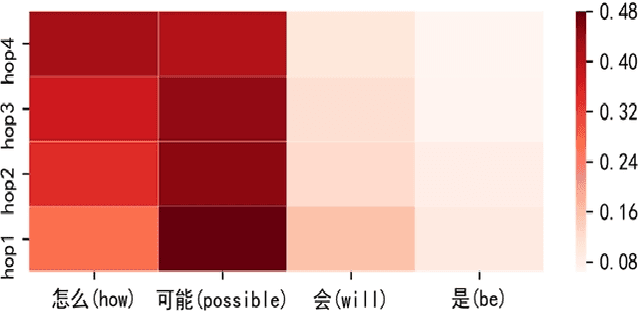
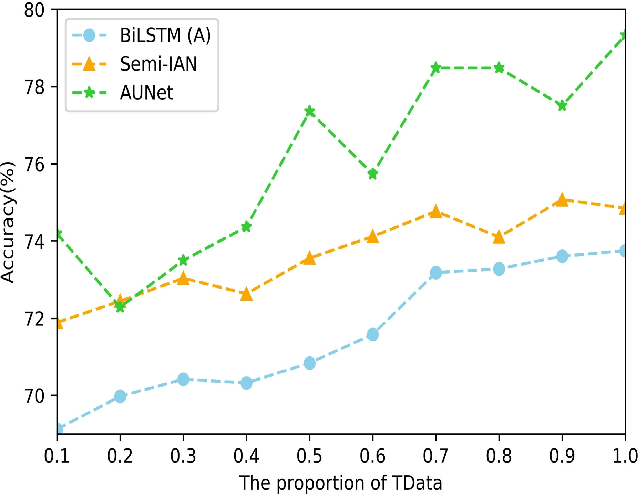
This study refers to a reverse question answering(reverse QA) procedure, in which machines proactively raise questions and humans supply answers. This procedure exists in many real human-machine interaction applications. A crucial problem in human-machine interaction is answer understanding. Existing solutions rely on mandatory option term selection to avoid automatic answer understanding. However, these solutions lead to unnatural human-computer interaction and harm user experience. To this end, this study proposed a novel deep answer understanding network, called AntNet, for reverse QA. The network consists of three new modules, namely, skeleton extraction for questions, relevance-aware representation of answers, and multi-hop based fusion. As answer understanding for reverse QA has not been explored, a new data corpus is compiled in this study. Experimental results indicate that our proposed network is significantly better than existing methods and those modified from classical natural language processing (NLP) deep models. The effectiveness of the three new modules is also verified.
Method and Dataset Mining in Scientific Papers
Nov 29, 2019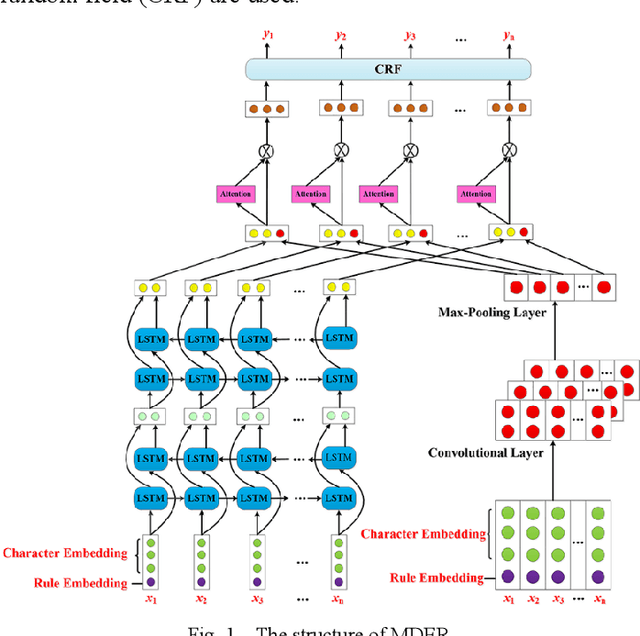
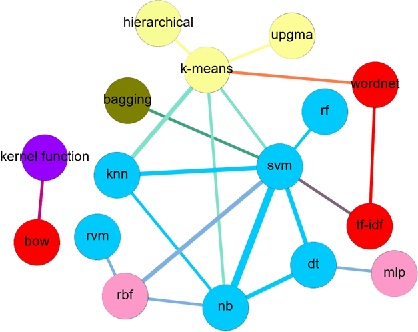
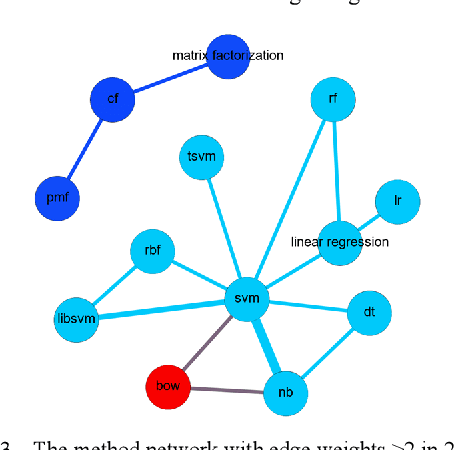
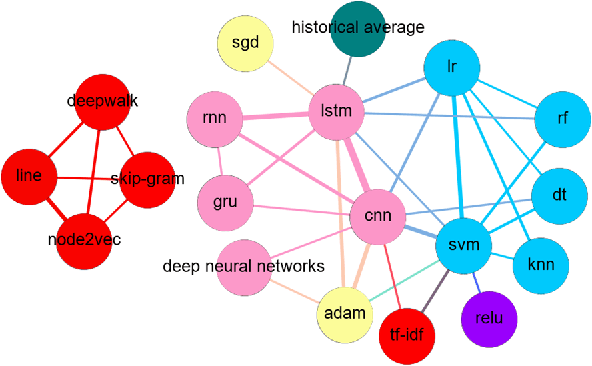
Literature analysis facilitates researchers better understanding the development of science and technology. The conventional literature analysis focuses on the topics, authors, abstracts, keywords, references, etc., and rarely pays attention to the content of papers. In the field of machine learning, the involved methods (M) and datasets (D) are key information in papers. The extraction and mining of M and D are useful for discipline analysis and algorithm recommendation. In this paper, we propose a novel entity recognition model, called MDER, and constructe datasets from the papers of the PAKDD conferences (2009-2019). Some preliminary experiments are conducted to assess the extraction performance and the mining results are visualized.