 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastRSR: Efficient and Accurate Road Surface Reconstruction from Bird's Eye View
Apr 13, 2025



Road Surface Reconstruction (RSR) is crucial for autonomous driving, enabling the understanding of road surface conditions. Recently, RSR from the Bird's Eye View (BEV) has gained attention for its potential to enhance performance. However, existing methods for transforming perspective views to BEV face challenges such as information loss and representation sparsity. Moreover, stereo matching in BEV is limited by the need to balance accuracy with inference speed. To address these challenges, we propose two efficient and accurate BEV-based RSR models: FastRSR-mono and FastRSR-stereo. Specifically, we first introduce Depth-Aware Projection (DAP), an efficient view transformation strategy designed to mitigate information loss and sparsity by querying depth and image features to aggregate BEV data within specific road surface regions using a pre-computed look-up table. To optimize accuracy and speed in stereo matching, we design the Spatial Attention Enhancement (SAE) and Confidence Attention Generation (CAG) modules. SAE adaptively highlights important regions, while CAG focuses on high-confidence predictions and filters out irrelevant information. FastRSR achieves state-of-the-art performance, exceeding monocular competitors by over 6.0% in elevation absolute error and providing at least a 3.0x speedup by stereo methods on the RSRD dataset. The source code will be released.
Aeroengine performance prediction using a physical-embedded data-driven method
Jun 29, 2024Accurate and efficient prediction of aeroengine performance is of paramount importance for engine design, maintenance, and optimization endeavours. However, existing methodologies often struggle to strike an optimal balance among predictive accuracy, computational efficiency, modelling complexity, and data dependency. To address these challenges, we propose a strategy that synergistically combines domain knowledge from both the aeroengine and neural network realms to enable real-time prediction of engine performance parameters. Leveraging aeroengine domain knowledge, we judiciously design the network structure and regulate the internal information flow. Concurrently, drawing upon neural network domain expertise, we devise four distinct feature fusion methods and introduce an innovative loss function formulation. To rigorously evaluate the effectiveness and robustness of our proposed strategy, we conduct comprehensive validation across two distinct datasets. The empirical results demonstrate :(1) the evident advantages of our tailored loss function; (2) our model's ability to maintain equal or superior performance with a reduced parameter count; (3) our model's reduced data dependency compared to generalized neural network architectures; (4)Our model is more interpretable than traditional black box machine learning methods.
Contour Loss for Instance Segmentation via k-step Distance Transformation Image
Feb 22, 2021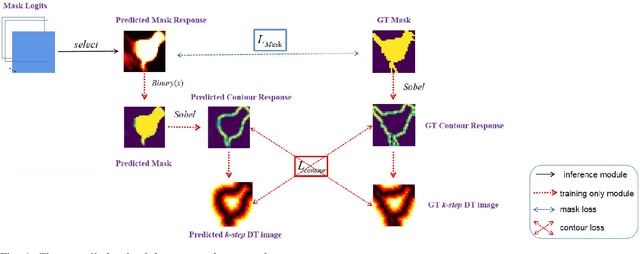
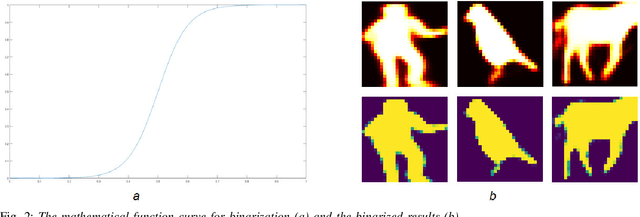


Instance segmentation aims to locate targets in the image and segment each target area at pixel level, which is one of the most important tasks in computer vision. Mask R-CNN is a classic method of instance segmentation, but we find that its predicted masks are unclear and inaccurate near contours. To cope with this problem, we draw on the idea of contour matching based on distance transformation image and propose a novel loss function, called contour loss. Contour loss is designed to specifically optimize the contour parts of the predicted masks, thus can assure more accurate instance segmentation. In order to make the proposed contour loss to be jointly trained under modern neural network frameworks, we design a differentiable k-step distance transformation image calculation module, which can approximately compute truncated distance transformation images of the predicted mask and corresponding ground-truth mask online. The proposed contour loss can be integrated into existing instance segmentation methods such as Mask R-CNN, and combined with their original loss functions without modification of the inference network structures, thus has strong versatility. Experimental results on COCO show that contour loss is effective, which can further improve instance segmentation performances.
AI Marker-based Large-scale AI Literature Mining
Nov 03, 2020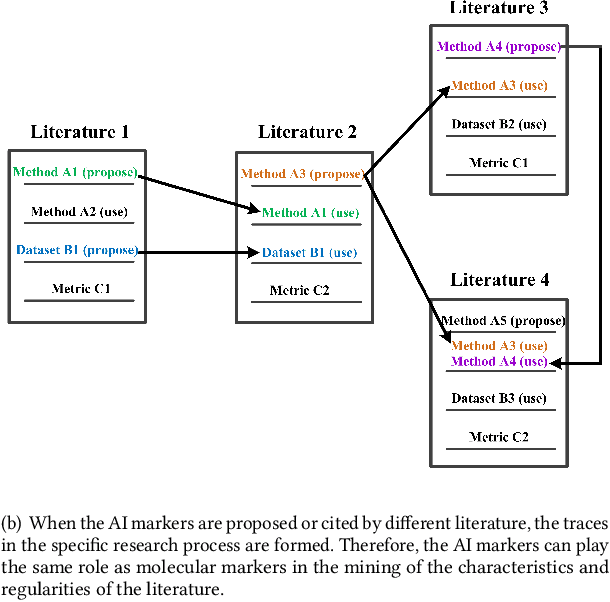

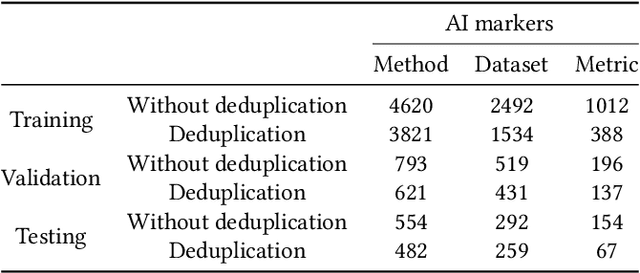
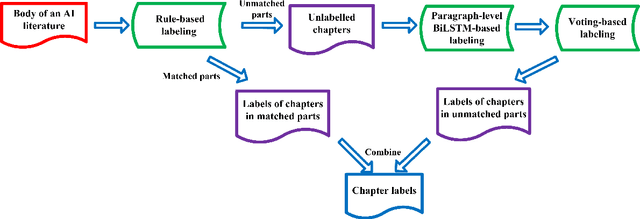
The knowledge contained in academic literature is interesting to mine. Inspired by the idea of molecular markers tracing in the field of biochemistry, three named entities, namely, methods, datasets and metrics are used as AI markers for AI literature. These entities can be used to trace the research process described in the bodies of papers, which opens up new perspectives for seeking and mining more valuable academic information. Firstly, the entity extraction model is used in this study to extract AI markers from large-scale AI literature. Secondly, original papers are traced for AI markers. Statistical and propagation analysis are performed based on tracing results. Finally, the co-occurrences of AI markers are used to achieve clustering. The evolution within method clusters and the influencing relationships amongst different research scene clusters are explored. The above-mentioned mining based on AI markers yields many meaningful discoveries. For example, the propagation of effective methods on the datasets is rapidly increasing with the development of time; effective methods proposed by China in recent years have increasing influence on other countries, whilst France is the opposite. Saliency detection, a classic computer vision research scene, is the least likely to be affected by other research scenes.